 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Byzantine Decentralized Learning Efficient
Sep 22, 2022
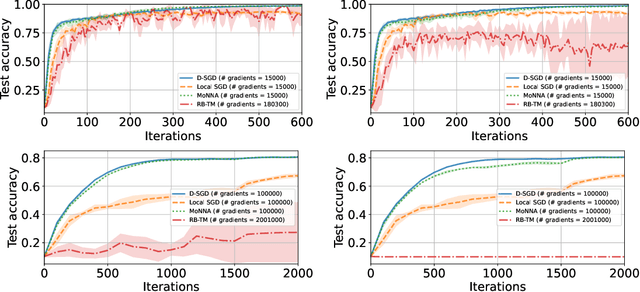
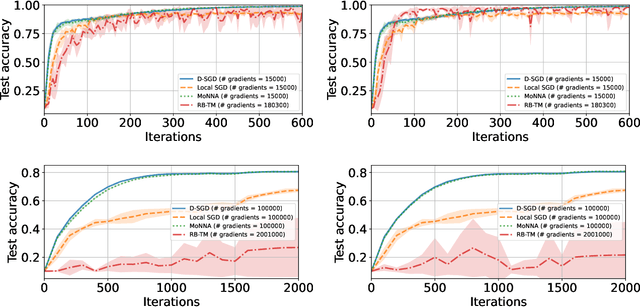
Decentralized-SGD (D-SGD) distributes heavy learning tasks across multiple machines (a.k.a., {\em nodes}), effectively dividing the workload per node by the size of the system. However, a handful of \emph{Byzantine} (i.e., misbehaving) nodes can jeopardize the entire learning procedure. This vulnerability is further amplified when the system is \emph{asynchronous}. Although approaches that confer Byzantine resilience to D-SGD have been proposed, these significantly impact the efficiency of the process to the point of even negating the benefit of decentralization. This naturally raises the question: \emph{can decentralized learning simultaneously enjoy Byzantine resilience and reduced workload per node?} We answer positively by proposing \newalgorithm{} that ensures Byzantine resilience without losing the computational efficiency of D-SGD. Essentially, \newalgorithm{} weakens the impact of Byzantine nodes by reducing the variance in local updates using \emph{Polyak's momentum}. Then, by establishing coordination between nodes via {\em signed echo broadcast} and a {\em nearest-neighbor averaging} scheme, we effectively tolerate Byzantine nodes whilst distributing the overhead amongst the non-Byzantine nodes. To demonstrate the correctness of our algorithm, we introduce and analyze a novel {\em Lyapunov function} that accounts for the {\em non-Markovian model drift} arising from the use of momentum. We also demonstrate the efficiency of \newalgorithm{} through experiments on several image classification tasks.
Purely Bayesian counterfactuals versus Newcomb's paradox
Aug 10, 2020This paper proposes a careful separation between an entity's epistemic system and their decision system. Crucially, Bayesian counterfactuals are estimated by the epistemic system; not by the decision system. Based on this remark, I prove the existence of Newcomb-like problems for which an epistemic system necessarily expects the entity to make a counterfactually bad decision. I then address (a slight generalization of) Newcomb's paradox. I solve the specific case where the player believes that the predictor applies Bayes rule with a supset of all the data available to the player. I prove that the counterfactual optimality of the 1-Box strategy depends on the player's prior on the predictor's additional data. If these additional data are not expected to reduce sufficiently the predictor's uncertainty on the player's decision, then the player's epistemic system will counterfactually prefer to 2-Box. But if the predictor's data is believed to make them quasi-omniscient, then 1-Box will be counterfactually preferred. Implications of the analysis are then discussed. More generally, I argue that, to better understand or design an entity, it is useful to clearly separate the entity's epistemic, decision, but also data collection, reward and maintenance systems, whether the entity is human, algorithmic or institutional.
Collaborative Learning as an Agreement Problem
Aug 04, 2020
We address the problem of Byzantine collaborative learning: a set of $n$ nodes try to collectively learn from data, whose distributions may vary from one node to another. None of them is trusted and $f < n$ can behave arbitrarily. We show that collaborative learning is equivalent to a new form of agreement, which we call averaging agreement. In this problem, nodes start each with an initial vector and seek to approximately agree on a common vector, while guaranteeing that this common vector remains within a constant (also called averaging constant) of the maximum distance between the original vectors. Essentially, the smaller the averaging constant, the better the learning. We present three asynchronous solutions to averaging agreement, each interesting in its own right. The first, based on the minimum volume ellipsoid, achieves asymptotically the best-possible averaging constant but requires $ n \geq 6f+1$. The second, based on reliable broadcast, achieves optimal Byzantine resilience, i.e., $n \geq 3f+1$, but requires signatures and induces a large number of communication rounds. The third, based on coordinate-wise trimmed mean, is faster and achieves optimal Byzantine resilience, i.e., $n \geq 4f+1$, within standard form algorithms that do not use signatures.
A Roadmap for the Value-Loading Problem
Oct 21, 2018

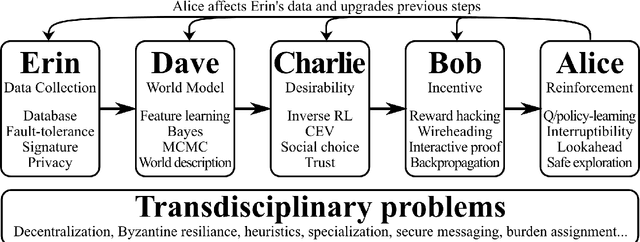
We analyze the value-loading problem. This is the problem of encoding moral values into an AI agent interacting with a complex environment. Like many before, we argue that this is both a major concern and an extremely challenging problem. Solving it will likely require years, if not decades, of multidisciplinary work by teams of top scientists and experts. Given how uncertain the timeline of human-level AI research is, we thus argue that a pragmatic partial solution should be designed as soon as possible. To this end, we propose a preliminary research program. This roadmap identifies several key steps. We hope that this will allow scholars, engineers and decision-makers to better grasp the upcoming difficulties, and to foresee how they can best contribute to the global effort.
Removing Algorithmic Discrimination (With Minimal Individual Error)
Jun 07, 2018
We address the problem of correcting group discriminations within a score function, while minimizing the individual error. Each group is described by a probability density function on the set of profiles. We first solve the problem analytically in the case of two populations, with a uniform bonus-malus on the zones where each population is a majority. We then address the general case of n populations, where the entanglement of populations does not allow a similar analytical solution. We show that an approximate solution with an arbitrarily high level of precision can be computed with linear programming. Finally, we address the inverse problem where the error should not go beyond a certain value and we seek to minimize the discrimination.
Deep Learning Works in Practice. But Does it Work in Theory?
Jan 31, 2018
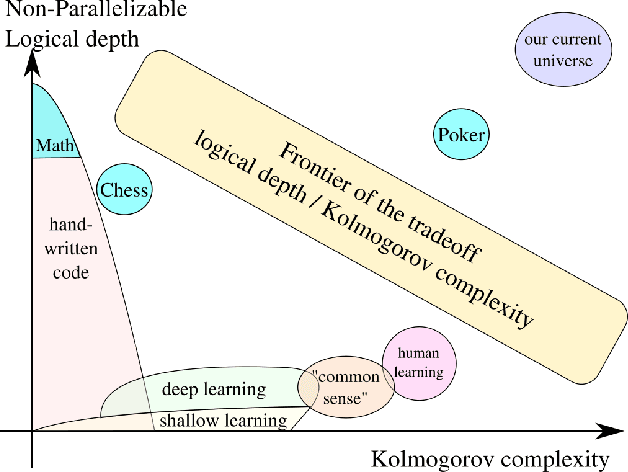


Deep learning relies on a very specific kind of neural networks: those superposing several neural layers. In the last few years, deep learning achieved major breakthroughs in many tasks such as image analysis, speech recognition, natural language processing, and so on. Yet, there is no theoretical explanation of this success. In particular, it is not clear why the deeper the network, the better it actually performs. We argue that the explanation is intimately connected to a key feature of the data collected from our surrounding universe to feed the machine learning algorithms: large non-parallelizable logical depth. Roughly speaking, we conjecture that the shortest computational descriptions of the universe are algorithms with inherently large computation times, even when a large number of computers are available for parallelization. Interestingly, this conjecture, combined with the folklore conjecture in theoretical computer science that $ P \neq NC$, explains the success of deep learning.