 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Works in Practice. But Does it Work in Theory?
Paper and Code
Jan 31, 2018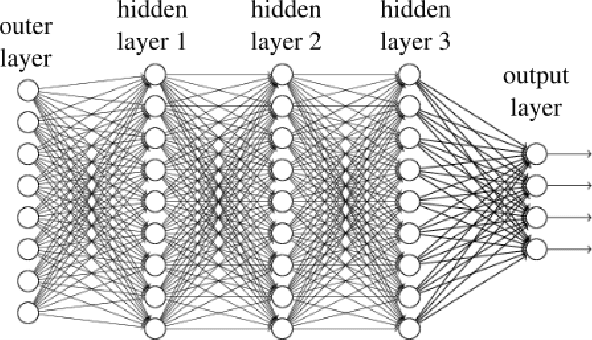
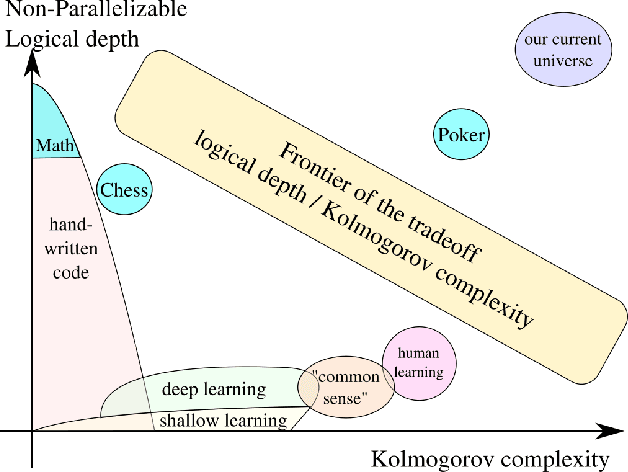


Deep learning relies on a very specific kind of neural networks: those superposing several neural layers. In the last few years, deep learning achieved major breakthroughs in many tasks such as image analysis, speech recognition, natural language processing, and so on. Yet, there is no theoretical explanation of this success. In particular, it is not clear why the deeper the network, the better it actually performs. We argue that the explanation is intimately connected to a key feature of the data collected from our surrounding universe to feed the machine learning algorithms: large non-parallelizable logical depth. Roughly speaking, we conjecture that the shortest computational descriptions of the universe are algorithms with inherently large computation times, even when a large number of computers are available for parallelization. Interestingly, this conjecture, combined with the folklore conjecture in theoretical computer science that $ P \neq NC$, explains the success of deep learning.