 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtuously Safe Reinforcement Learning
Paper and Code
May 29, 2018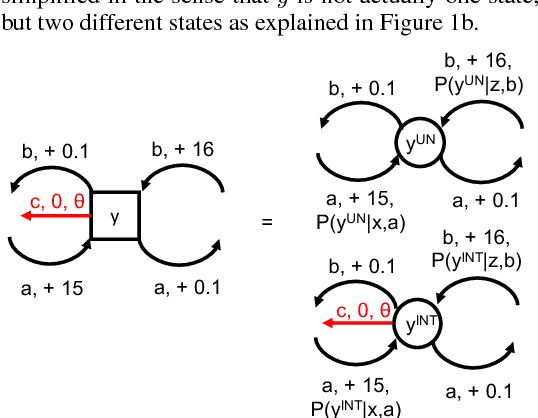
We show that when a third party, the adversary, steps into the two-party setting (agent and operator) of safely interruptible reinforcement learning, a trade-off has to be made between the probability of following the optimal policy in the limit, and the probability of escaping a dangerous situation created by the adversary. So far, the work on safely interruptible agents has assumed a perfect perception of the agent about its environment (no adversary), and therefore implicitly set the second probability to zero, by explicitly seeking a value of one for the first probability. We show that (1) agents can be made both interruptible and adversary-resilient, and (2) the interruptibility can be made safe in the sense that the agent itself will not seek to avoid it. We also solve the problem that arises when the agent does not go completely greedy, i.e. issues with safe exploration in the limit. Resilience to perturbed perception, safe exploration in the limit, and safe interruptibility are the three pillars of what we call \emph{virtuously safe reinforcement learning}.