 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompliant Non-Prehensile Pushing Manipulation
May 25, 2026In this paper, we address the challenge of performing non-prehensile pushing operations with a compliant robotic manipulation system. To ensure safe operations in human-populated environments, robots must comply with external physical interactions and exhibit passive behavior. To achieve this, we extend a state-of-the-art pushing model to integrate it with impedance-controlled robots. We develop a model predictive control framework built upon this model that enables compliant pushing through optimal modulation of the robot's position/velocity set-point, jointly realizing the required pushing force and contact point adaptation to obtain desired object motion. However, external interactions may induce tracking errors, causing a consequent potentially indefinite increase of the pushing force. To prevent this, we integrate an energy tank passivity filter that further modulates the robot velocity set-point to guarantee passivity and avoid uncontrolled energy buildup. The proposed method has been rigorously tested in simulation and validated through experiments on two different robotic systems, demonstrating passive compliance during human-robot interactions and assessing trajectory tracking performance and robustness to variations in the object's physical parameters.
What Can Robots Teach Us About Trust and Reliance? An interdisciplinary dialogue between Social Sciences and Social Robotics
Jul 17, 2025As robots find their way into more and more aspects of everyday life, questions around trust are becoming increasingly important. What does it mean to trust a robot? And how should we think about trust in relationships that involve both humans and non-human agents? While the field of Human-Robot Interaction (HRI) has made trust a central topic, the concept is often approached in fragmented ways. At the same time, established work in sociology, where trust has long been a key theme, is rarely brought into conversation with developments in robotics. This article argues that we need a more interdisciplinary approach. By drawing on insights from both social sciences and social robotics, we explore how trust is shaped, tested and made visible. Our goal is to open up a dialogue between disciplines and help build a more grounded and adaptable framework for understanding trust in the evolving world of human-robot interaction.
From Vocal Instructions to Household Tasks: The Inria Tiago++ in the euROBIN Service Robots Coopetition
Dec 20, 2024This paper describes the Inria team's integrated robotics system used in the 1st euROBIN coopetition, during which service robots performed voice-activated household tasks in a kitchen setting.The team developed a modified Tiago++ platform that leverages a whole-body control stack for autonomous and teleoperated modes, and an LLM-based pipeline for instruction understanding and task planning. The key contributions (opens-sourced) are the integration of these components and the design of custom teleoperation devices, addressing practical challenges in the deployment of service robots.
FollowMe: a Robust Person Following Framework Based on Re-Identification and Gestures
Nov 21, 2023



Human-robot interaction (HRI) has become a crucial enabler in houses and industries for facilitating operational flexibility. When it comes to mobile collaborative robots, this flexibility can be further increased due to the autonomous mobility and navigation capacity of the robotic agents, expanding their workspace and consequently, the personalizable assistance they can provide to the human operators. This however requires that the robot is capable of detecting and identifying the human counterpart in all stages of the collaborative task, and in particular while following a human in crowded workplaces. To respond to this need, we developed a unified perception and navigation framework, which enables the robot to identify and follow a target person using a combination of visual Re-Identification (Re-ID), hand gestures detection, and collision-free navigation. The Re-ID module can autonomously learn the features of a target person and use the acquired knowledge to visually re-identify the target. The navigation stack is used to follow the target avoiding obstacles and other individuals in the environment. Experiments are conducted with few subjects in a laboratory setting where some unknown dynamic obstacles are introduced.
Learning Control from Raw Position Measurements
Jan 30, 2023We propose a Model-Based Reinforcement Learning (MBRL) algorithm named VF-MC-PILCO, specifically designed for application to mechanical systems where velocities cannot be directly measured. This circumstance, if not adequately considered, can compromise the success of MBRL approaches. To cope with this problem, we define a velocity-free state formulation which consists of the collection of past positions and inputs. Then, VF-MC-PILCO uses Gaussian Process Regression to model the dynamics of the velocity-free state and optimizes the control policy through a particle-based policy gradient approach. We compare VF-MC-PILCO with our previous MBRL algorithm, MC-PILCO4PMS, which handles the lack of direct velocity measurements by modeling the presence of velocity estimators. Results on both simulated (cart-pole and UR5 robot) and real mechanical systems (Furuta pendulum and a ball-and-plate rig) show that the two algorithms achieve similar results. Conveniently, VF-MC-PILCO does not require the design and implementation of state estimators, which can be a challenging and time-consuming activity to be performed by an expert user.
Control of Mechanical Systems via Feedback Linearization Based on Black-Box Gaussian Process Models
May 02, 2021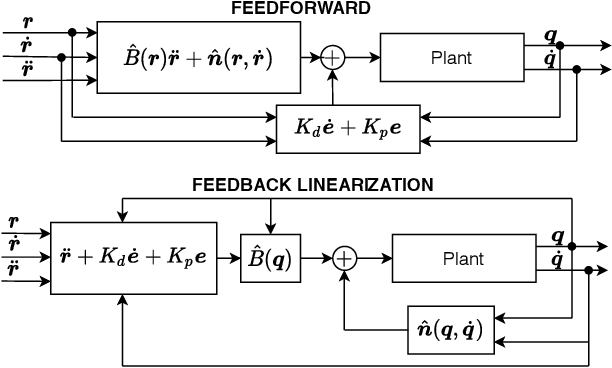
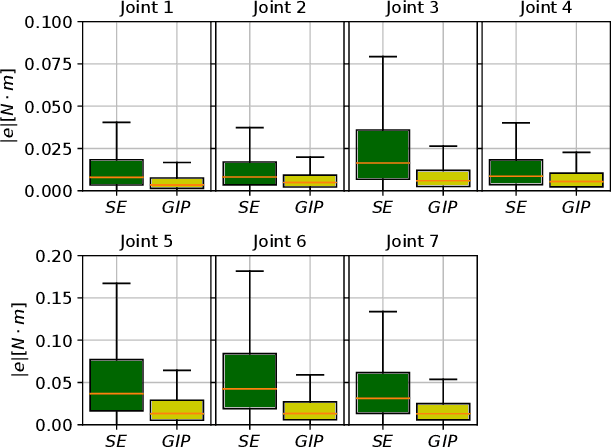
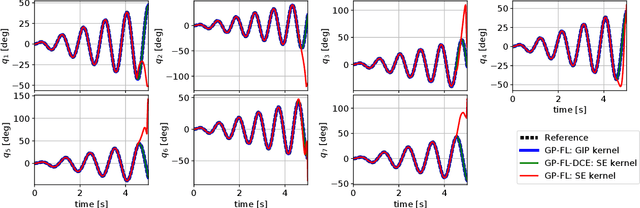
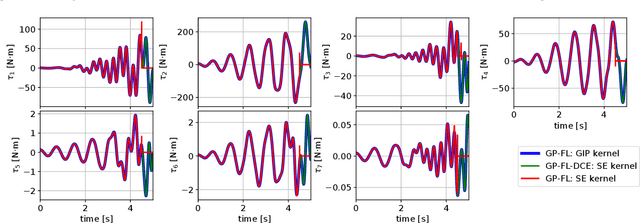
In this paper, we consider the use of black-box Gaussian process (GP) models for trajectory tracking control based on feedback linearization, in the context of mechanical systems. We considered two strategies. The first computes the control input directly by using the GP model, whereas the second computes the input after estimating the individual components of the dynamics. We tested the two strategies on a simulated manipulator with seven degrees of freedom, also varying the GP kernel choice. Results show that the second implementation is more robust w.r.t. the kernel choice and model inaccuracies. Moreover, as regards the choice of kernel, the obtained performance shows that the use of a structured kernel, such as a polynomial kernel, is advantageous, because of its effectiveness with both strategies.
Controlled Gaussian Process Dynamical Models with Application to Robotic Cloth Manipulation
Mar 11, 2021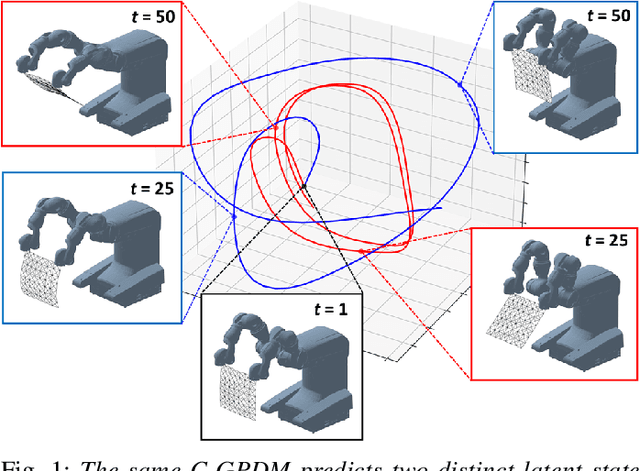
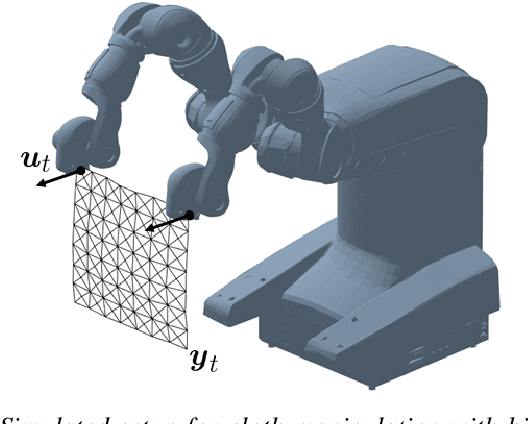

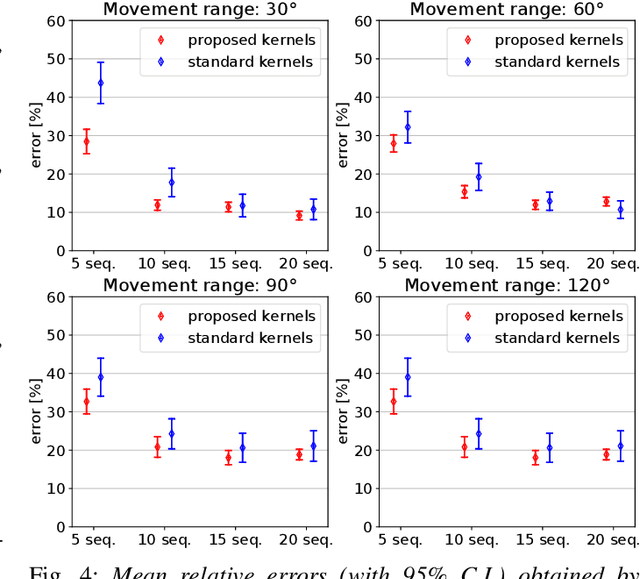
Over the last years, robotic cloth manipulation has gained relevance within the research community. While significant advances have been made in robotic manipulation of rigid objects, the manipulation of non-rigid objects such as cloth garments is still a challenging problem. The uncertainty on how cloth behaves often requires the use of model-based approaches. However, cloth models have a very high dimensionality. Therefore, it is difficult to find a middle point between providing a manipulator with a dynamics model of cloth and working with a state space of tractable dimensionality. For this reason, most cloth manipulation approaches in literature perform static or quasi-static manipulation. In this paper, we propose a variation of Gaussian Process Dynamical Models (GPDMs) to model cloth dynamics in a low-dimensional manifold. GPDMs project a high-dimensional state space into a smaller dimension latent space which is capable of keeping the dynamic properties. Using such approach, we add control variables to the original formulation. In this way, it is possible to take into account the robot commands exerted on the cloth dynamics. We call this new version Controlled Gaussian Process Dynamical Model (C-GPDM). Moreover, we propose an alternative kernel representation for the model, characterized by a richer parameterization than the one employed in the majority of previous GPDM realizations. The modeling capacity of our proposal has been tested in a simulated scenario, where C-GPDM proved to be capable of generalizing over a considerably wide range of movements and correctly predicting the cloth oscillations generated by previously unseen sequences of control actions.
Model-Based Policy Search Using Monte Carlo Gradient Estimation with Real Systems Application
Jan 28, 2021



In this paper, we present a Model-Based Reinforcement Learning algorithm named Monte Carlo Probabilistic Inference for Learning COntrol (MC-PILCO). The algorithm relies on Gaussian Processes (GPs) to model the system dynamics and on a Monte Carlo approach to estimate the policy gradient. This defines a framework in which we ablate the choice of the following components: (i) the selection of the cost function, (ii) the optimization of policies using dropout, (iii) an improved data efficiency through the use of structured kernels in the GP models. The combination of the aforementioned aspects affects dramatically the performance of MC-PILCO. Numerical comparisons in a simulated cart-pole environment show that MC-PILCO exhibits better data-efficiency and control performance w.r.t. state-of-the-art GP-based MBRL algorithms. Finally, we apply MC-PILCO to real systems, considering in particular systems with partially measurable states. We discuss the importance of modeling both the measurement system and the state estimators during policy optimization. The effectiveness of the proposed solutions has been tested in simulation and in two real systems, a Furuta pendulum and a ball-and-plate.
Model-based Policy Search for Partially Measurable Systems
Jan 21, 2021


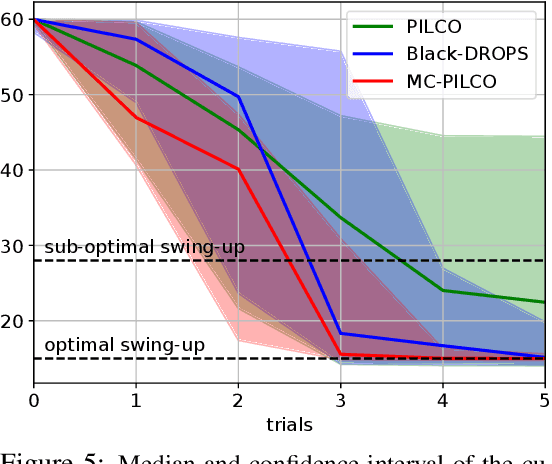
In this paper, we propose a Model-Based Reinforcement Learning (MBRL) algorithm for Partially Measurable Systems (PMS), i.e., systems where the state can not be directly measured, but must be estimated through proper state observers. The proposed algorithm, named Monte Carlo Probabilistic Inference for Learning COntrol for Partially Measurable Systems (MC-PILCO4PMS), relies on Gaussian Processes (GPs) to model the system dynamics, and on a Monte Carlo approach to update the policy parameters. W.r.t. previous GP-based MBRL algorithms, MC-PILCO4PMS models explicitly the presence of state observers during policy optimization, allowing to deal PMS. The effectiveness of the proposed algorithm has been tested both in simulation and in two real systems.