 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollowMe: a Robust Person Following Framework Based on Re-Identification and Gestures
Nov 21, 2023



Human-robot interaction (HRI) has become a crucial enabler in houses and industries for facilitating operational flexibility. When it comes to mobile collaborative robots, this flexibility can be further increased due to the autonomous mobility and navigation capacity of the robotic agents, expanding their workspace and consequently, the personalizable assistance they can provide to the human operators. This however requires that the robot is capable of detecting and identifying the human counterpart in all stages of the collaborative task, and in particular while following a human in crowded workplaces. To respond to this need, we developed a unified perception and navigation framework, which enables the robot to identify and follow a target person using a combination of visual Re-Identification (Re-ID), hand gestures detection, and collision-free navigation. The Re-ID module can autonomously learn the features of a target person and use the acquired knowledge to visually re-identify the target. The navigation stack is used to follow the target avoiding obstacles and other individuals in the environment. Experiments are conducted with few subjects in a laboratory setting where some unknown dynamic obstacles are introduced.
CARPE-ID: Continuously Adaptable Re-identification for Personalized Robot Assistance
Oct 30, 2023



In today's Human-Robot Interaction (HRI) scenarios, a prevailing tendency exists to assume that the robot shall cooperate with the closest individual or that the scene involves merely a singular human actor. However, in realistic scenarios, such as shop floor operations, such an assumption may not hold and personalized target recognition by the robot in crowded environments is required. To fulfil this requirement, in this work, we propose a person re-identification module based on continual visual adaptation techniques that ensure the robot's seamless cooperation with the appropriate individual even subject to varying visual appearances or partial or complete occlusions. We test the framework singularly using recorded videos in a laboratory environment and an HRI scenario, i.e., a person-following task by a mobile robot. The targets are asked to change their appearance during tracking and to disappear from the camera field of view to test the challenging cases of occlusion and outfit variations. We compare our framework with one of the state-of-the-art Multi-Object Tracking (MOT) methods and the results show that the CARPE-ID can accurately track each selected target throughout the experiments in all the cases (except two limit cases). At the same time, the s-o-t-a MOT has a mean of 4 tracking errors for each video.
Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization
Jul 03, 2023Geometric navigation is nowadays a well-established field of robotics and the research focus is shifting towards higher-level scene understanding, such as Semantic Mapping. When a robot needs to interact with its environment, it must be able to comprehend the contextual information of its surroundings. This work focuses on classifying and localising objects within a map, which is under construction (SLAM) or already built. To further explore this direction, we propose a framework that can autonomously detect and localize predefined objects in a known environment using a multi-modal sensor fusion approach (combining RGB and depth data from an RGB-D camera and a lidar). The framework consists of three key elements: understanding the environment through RGB data, estimating depth through multi-modal sensor fusion, and managing artifacts (i.e., filtering and stabilizing measurements). The experiments show that the proposed framework can accurately detect 98% of the objects in the real sample environment, without post-processing, while 85% and 80% of the objects were mapped using the single RGBD camera or RGB + lidar setup respectively. The comparison with single-sensor (camera or lidar) experiments is performed to show that sensor fusion allows the robot to accurately detect near and far obstacles, which would have been noisy or imprecise in a purely visual or laser-based approach.
Compact CNN Structure Learning by Knowledge Distillation
Apr 19, 2021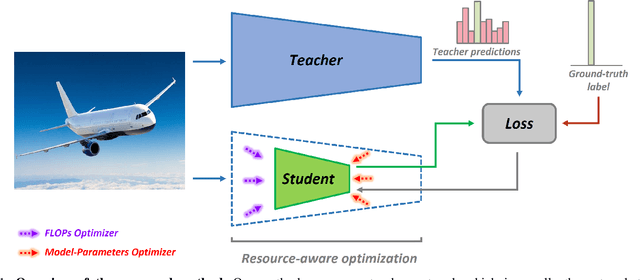
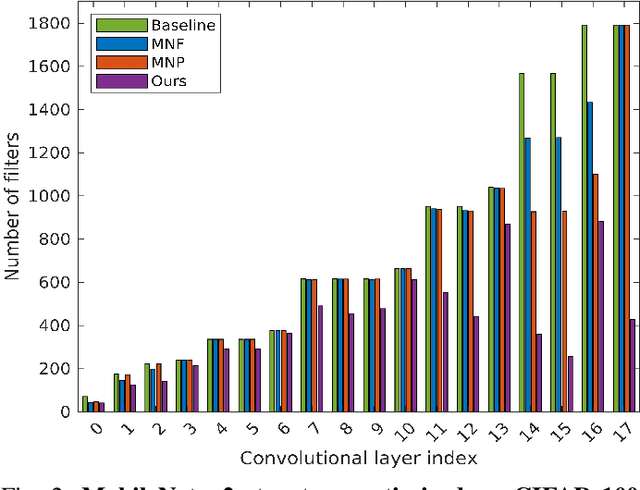
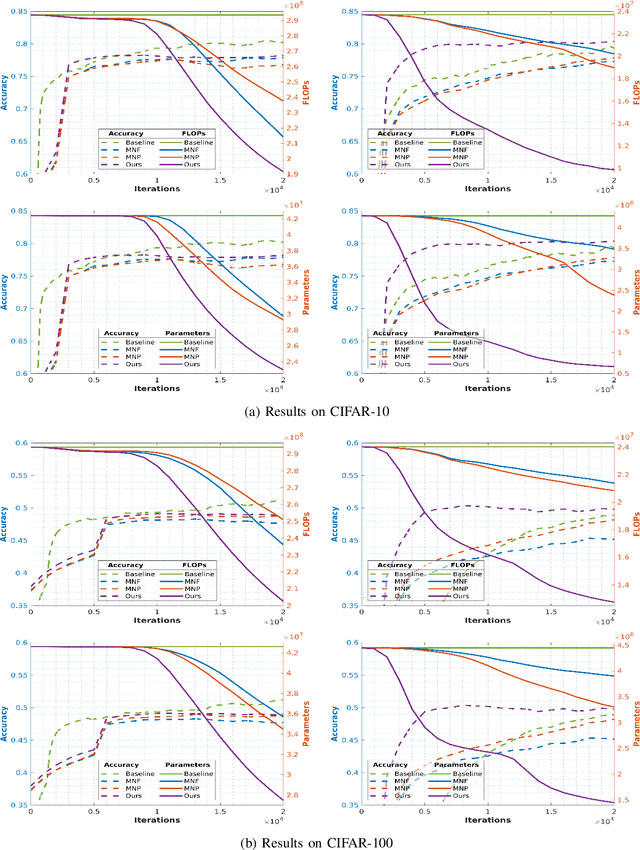
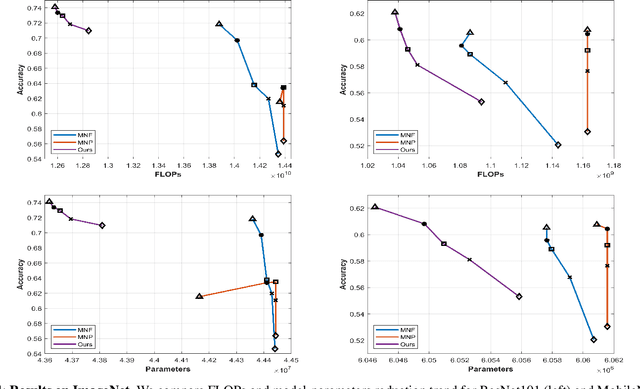
The concept of compressing deep Convolutional Neural Networks (CNNs) is essential to use limited computation, power, and memory resources on embedded devices. However, existing methods achieve this objective at the cost of a drop in inference accuracy in computer vision tasks. To address such a drawback, we propose a framework that leverages knowledge distillation along with customizable block-wise optimization to learn a lightweight CNN structure while preserving better control over the compression-performance tradeoff. Considering specific resource constraints, e.g., floating-point operations per inference (FLOPs) or model-parameters, our method results in a state of the art network compression while being capable of achieving better inference accuracy. In a comprehensive evaluation, we demonstrate that our method is effective, robust, and consistent with results over a variety of network architectures and datasets, at negligible training overhead. In particular, for the already compact network MobileNet_v2, our method offers up to 2x and 5.2x better model compression in terms of FLOPs and model-parameters, respectively, while getting 1.05% better model performance than the baseline network.
Explainable Deep Classification Models for Domain Generalization
Mar 13, 2020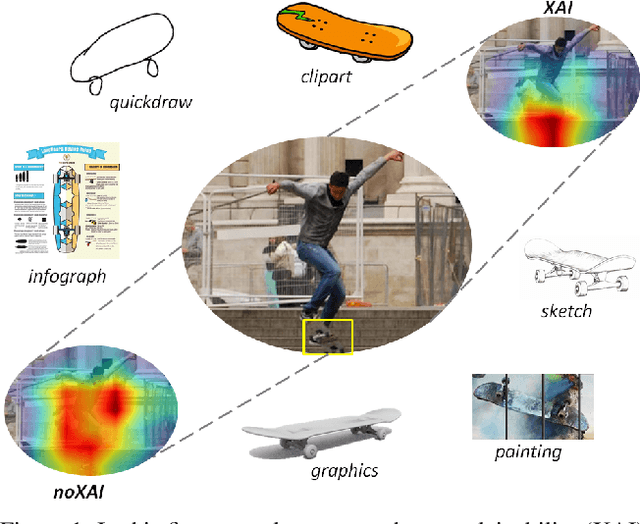
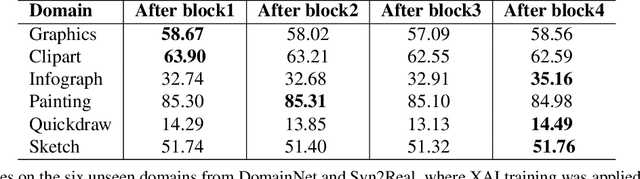

Conventionally, AI models are thought to trade off explainability for lower accuracy. We develop a training strategy that not only leads to a more explainable AI system for object classification, but as a consequence, suffers no perceptible accuracy degradation. Explanations are defined as regions of visual evidence upon which a deep classification network makes a decision. This is represented in the form of a saliency map conveying how much each pixel contributed to the network's decision. Our training strategy enforces a periodic saliency-based feedback to encourage the model to focus on the image regions that directly correspond to the ground-truth object. We quantify explainability using an automated metric, and using human judgement. We propose explainability as a means for bridging the visual-semantic gap between different domains where model explanations are used as a means of disentagling domain specific information from otherwise relevant features. We demonstrate that this leads to improved generalization to new domains without hindering performance on the original domain.
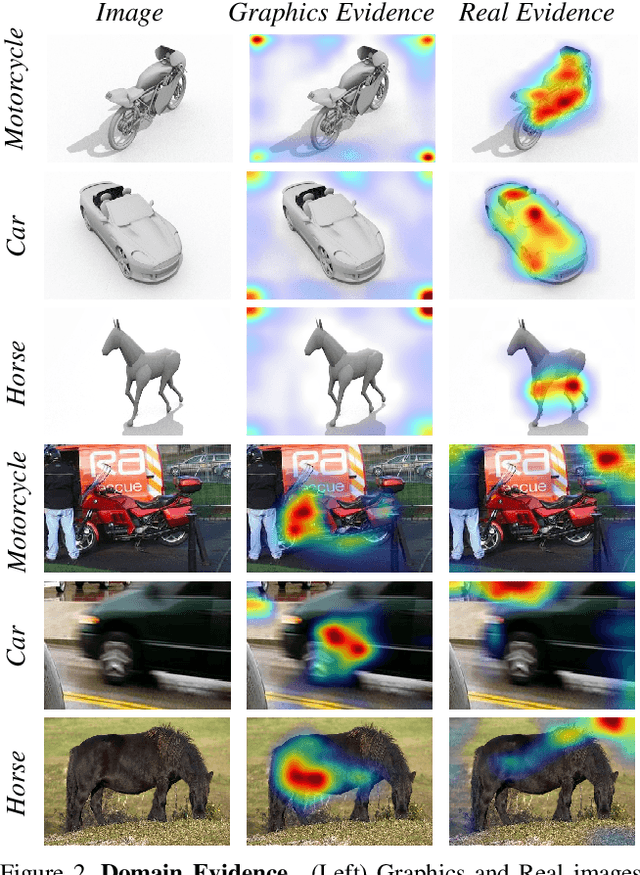
Guided Zoom: Questioning Network Evidence for Fine-grained Classification
Dec 06, 2018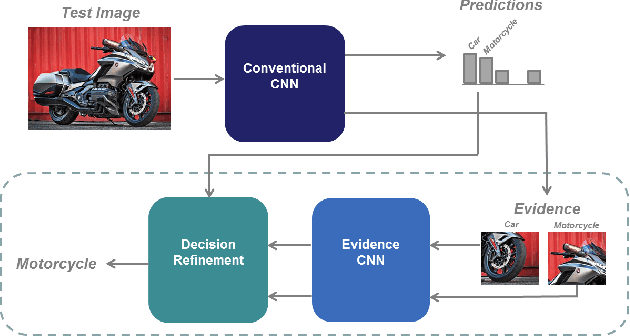

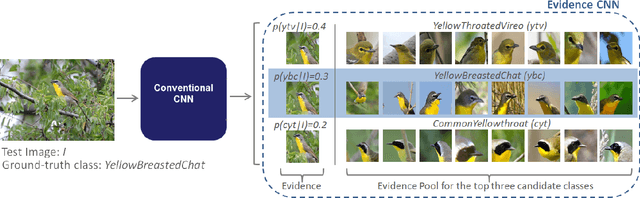
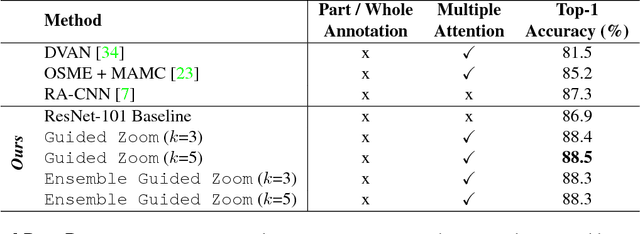
We propose Guided Zoom, an approach that utilizes spatial grounding to make more informed predictions. It does so by making sure the model has "the right reasons" for a prediction, being defined as reasons that are coherent with those used to make similar correct decisions at training time. The reason/evidence upon which a deep neural network makes a prediction is defined to be the spatial grounding, in the pixel space, for a specific class conditional probability in the model output. Guided Zoom questions how reasonable the evidence used to make a prediction is. In state-of-the-art deep single-label classification models, the top-k (k = 2, 3, 4, ...) accuracy is usually significantly higher than the top-1 accuracy. This is more evident in fine-grained datasets, where differences between classes are quite subtle. We show that Guided Zoom results in the refinement of a model's classification accuracy on three finegrained classification datasets. We also explore the complementarity of different grounding techniques, by comparing their ensemble to an adversarial erasing approach that iteratively reveals the next most discriminative evidence.
Excitation Dropout: Encouraging Plasticity in Deep Neural Networks
May 23, 2018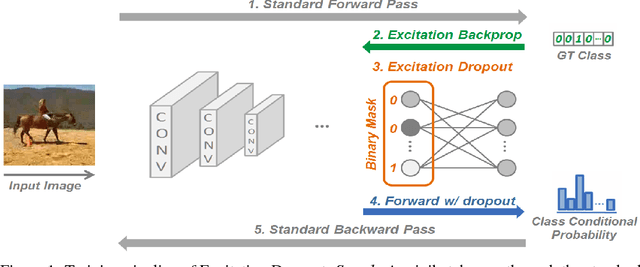


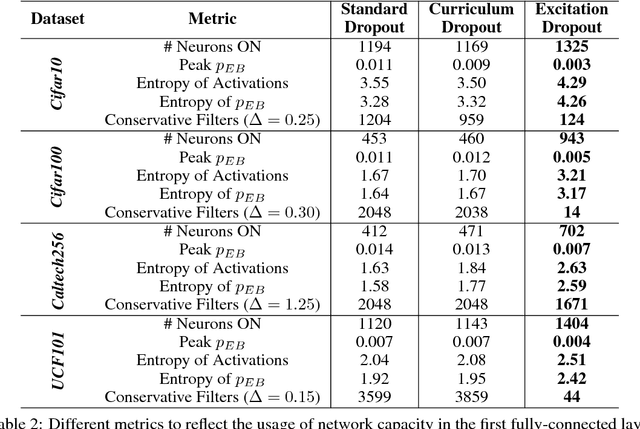
We propose a guided dropout regularizer for deep networks based on the evidence of a network prediction: the firing of neurons in specific paths. In this work, we utilize the evidence at each neuron to determine the probability of dropout, rather than dropping out neurons uniformly at random as in standard dropout. In essence, we dropout with higher probability those neurons which contribute more to decision making at training time. This approach penalizes high saliency neurons that are most relevant for model prediction, i.e. those having stronger evidence. By dropping such high-saliency neurons, the network is forced to learn alternative paths in order to maintain loss minimization, resulting in a plasticity-like behavior, a characteristic of human brains too. We demonstrate better generalization ability, an increased utilization of network neurons, and a higher resilience to network compression using several metrics over four image/video recognition benchmarks.
Excitation Backprop for RNNs
Mar 08, 2018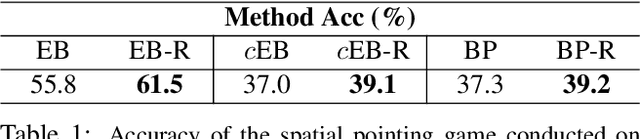
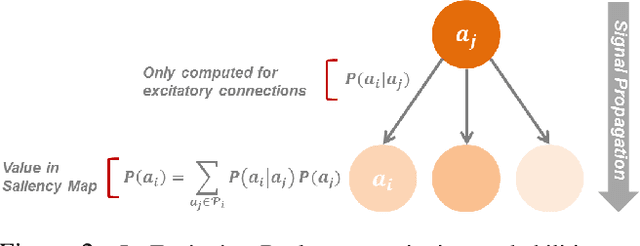
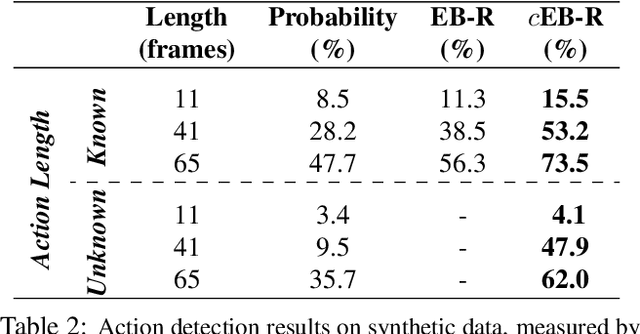
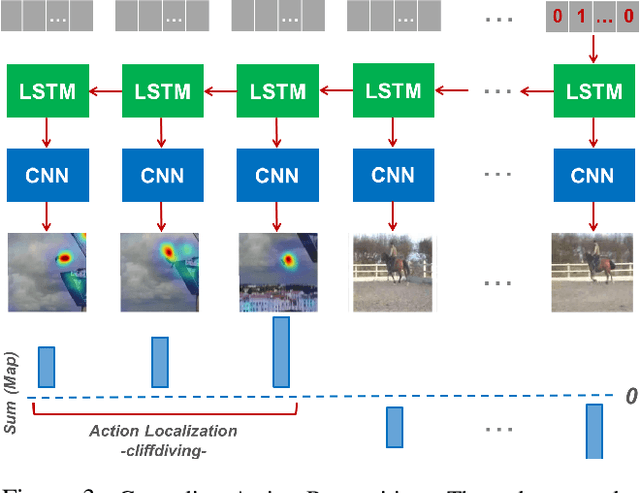
Deep models are state-of-the-art for many vision tasks including video action recognition and video captioning. Models are trained to caption or classify activity in videos, but little is known about the evidence used to make such decisions. Grounding decisions made by deep networks has been studied in spatial visual content, giving more insight into model predictions for images. However, such studies are relatively lacking for models of spatiotemporal visual content - videos. In this work, we devise a formulation that simultaneously grounds evidence in space and time, in a single pass, using top-down saliency. We visualize the spatiotemporal cues that contribute to a deep model's classification/captioning output using the model's internal representation. Based on these spatiotemporal cues, we are able to localize segments within a video that correspond with a specific action, or phrase from a caption, without explicitly optimizing/training for these tasks.
* CVPR 2018 Camera Ready Version
Predicting Human Intentions from Motion Only: A 2D+3D Fusion Approach
Sep 06, 2017


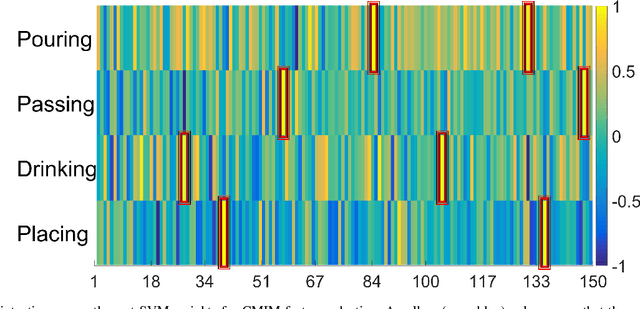
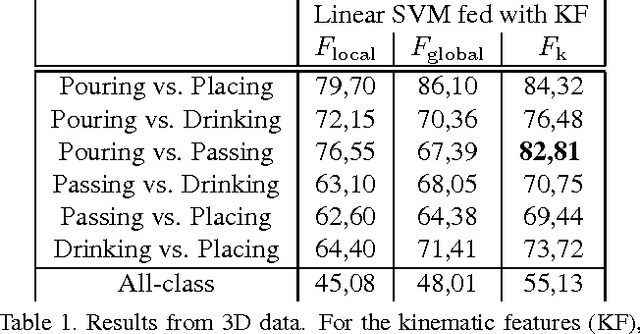
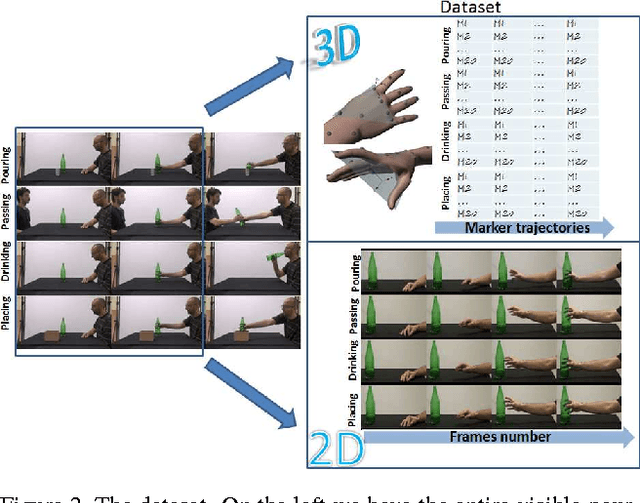
In this paper, we address the new problem of the prediction of human intents. There is neuro-psychological evidence that actions performed by humans are anticipated by peculiar motor acts which are discriminant of the type of action going to be performed afterwards. In other words, an actual intent can be forecast by looking at the kinematics of the immediately preceding movement. To prove it in a computational and quantitative manner, we devise a new experimental setup where, without using contextual information, we predict human intents all originating from the same motor act. We posit the problem as a classification task and we introduce a new multi-modal dataset consisting of a set of motion capture marker 3D data and 2D video sequences, where, by only analysing very similar movements in both training and test phases, we are able to predict the underlying intent, i.e., the future, never observed action. We also present an extensive experimental evaluation as a baseline, customizing state-of-the-art techniques for either 3D and 2D data analysis. Realizing that video processing methods lead to inferior performance but show complementary information with respect to 3D data sequences, we developed a 2D+3D fusion analysis where we achieve better classification accuracies, attesting the superiority of the multimodal approach for the context-free prediction of human intents.
What Will I Do Next? The Intention from Motion Experiment
Aug 03, 2017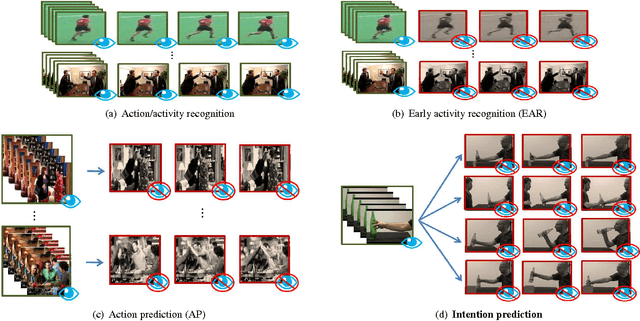

In computer vision, video-based approaches have been widely explored for the early classification and the prediction of actions or activities. However, it remains unclear whether this modality (as compared to 3D kinematics) can still be reliable for the prediction of human intentions, defined as the overarching goal embedded in an action sequence. Since the same action can be performed with different intentions, this problem is more challenging but yet affordable as proved by quantitative cognitive studies which exploit the 3D kinematics acquired through motion capture systems. In this paper, we bridge cognitive and computer vision studies, by demonstrating the effectiveness of video-based approaches for the prediction of human intentions. Precisely, we propose Intention from Motion, a new paradigm where, without using any contextual information, we consider instantaneous grasping motor acts involving a bottle in order to forecast why the bottle itself has been reached (to pass it or to place in a box, or to pour or to drink the liquid inside). We process only the grasping onsets casting intention prediction as a classification framework. Leveraging on our multimodal acquisition (3D motion capture data and 2D optical videos), we compare the most commonly used 3D descriptors from cognitive studies with state-of-the-art video-based techniques. Since the two analyses achieve an equivalent performance, we demonstrate that computer vision tools are effective in capturing the kinematics and facing the cognitive problem of human intention prediction.