 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Zoom: Questioning Network Evidence for Fine-grained Classification
Paper and Code
Dec 06, 2018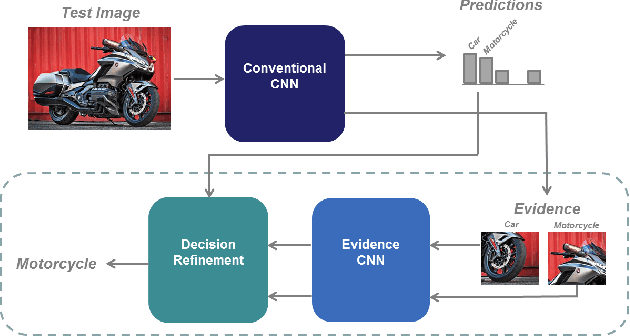

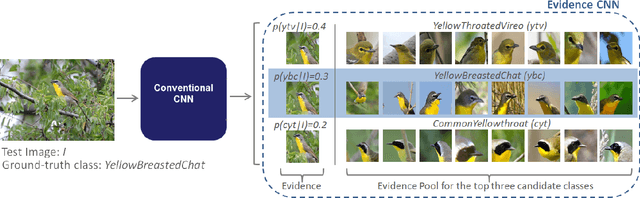
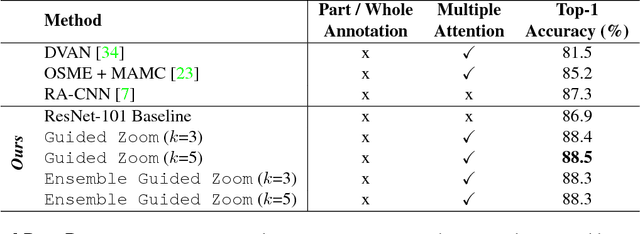
We propose Guided Zoom, an approach that utilizes spatial grounding to make more informed predictions. It does so by making sure the model has "the right reasons" for a prediction, being defined as reasons that are coherent with those used to make similar correct decisions at training time. The reason/evidence upon which a deep neural network makes a prediction is defined to be the spatial grounding, in the pixel space, for a specific class conditional probability in the model output. Guided Zoom questions how reasonable the evidence used to make a prediction is. In state-of-the-art deep single-label classification models, the top-k (k = 2, 3, 4, ...) accuracy is usually significantly higher than the top-1 accuracy. This is more evident in fine-grained datasets, where differences between classes are quite subtle. We show that Guided Zoom results in the refinement of a model's classification accuracy on three finegrained classification datasets. We also explore the complementarity of different grounding techniques, by comparing their ensemble to an adversarial erasing approach that iteratively reveals the next most discriminative evidence.