 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoveated Reasoning: Stateful, Action-based Visual Focusing for Vision-Language Models
Apr 22, 2026Vision-language models benefit from high-resolution images, but the increase in visual-token count incurs high compute overhead. Humans resolve this tension via foveation: a coarse view guides "where to look", while selectively acquired high-acuity evidence refines "what to think". We introduce Foveated Reasoner, an autoregressive vision-language framework that unifies foveation and reasoning within a single decoding trajectory. Starting from a low-resolution view, the model triggers foveation only when needed, retrieves high-resolution evidence from selected regions, and injects it back into the same decoding trajectory. We train the method with a two-stage pipeline: coldstart supervision to bootstrap foveation behavior, followed by reinforcement learning to jointly improve evidence acquisition and task accuracy while discouraging trivial "see-everything" solutions. Experiments show that the method learns effective foveation policies and achieves stronger accuracy under tight visual-token budgets across multiple vision-language benchmarks.
GoldiCLIP: The Goldilocks Approach for Balancing Explicit Supervision for Language-Image Pretraining
Mar 25, 2026Until recently, the success of large-scale vision-language models (VLMs) has primarily relied on billion-sample datasets, posing a significant barrier to progress. Latest works have begun to close this gap by improving supervision quality, but each addresses only a subset of the weaknesses in contrastive pretraining. We present GoldiCLIP, a framework built on a Goldilocks principle of finding the right balance of supervision signals. Our multifaceted training framework synergistically combines three key innovations: (1) a text-conditioned self-distillation method to align both text-agnostic and text-conditioned features; (2) an encoder integrated decoder with Visual Question Answering (VQA) objective that enables the encoder to generalize beyond the caption-like queries; and (3) an uncertainty-based weighting mechanism that automatically balances all heterogeneous losses. Trained on just 30 million images, 300x less data than leading methods, GoldiCLIP achieves state-of-the-art among data-efficient approaches, improving over the best comparable baseline by 2.2 points on MSCOCO retrieval, 2.0 on fine-grained retrieval, and 5.9 on question-based retrieval, while remaining competitive with billion-scale models. Project page: https://petsi.uk/goldiclip.
ARGENT: Adaptive Hierarchical Image-Text Representations
Mar 24, 2026Large-scale Vision-Language Models (VLMs) such as CLIP learn powerful semantic representations but operate in Euclidean space, which fails to capture the inherent hierarchical structure of visual and linguistic concepts. Hyperbolic geometry, with its exponential volume growth, offers a principled alternative for embedding such hierarchies with low distortion. However, existing hyperbolic VLMs use entailment losses that are unstable: as parent embeddings contract toward the origin, their entailment cones widen toward a half-space, causing catastrophic cone collapse that destroys the intended hierarchy. Additionally, hierarchical evaluation of these models remains unreliable, being largely retrieval-based and correlation-based metrics and prone to taxonomy dependence and ambiguous negatives. To address these limitations, we propose an adaptive entailment loss paired with a norm regularizer that prevents cone collapse without heuristic aperture clipping. We further introduce an angle-based probabilistic entailment protocol (PEP) for evaluating hierarchical understanding, scored with AUC-ROC and Average Precision. This paper introduces a stronger hyperbolic VLM baseline ARGENT, Adaptive hieRarchical imaGe-tExt represeNTation. ARGENT improves the SOTA hyperbolic VLM by 0.7, 1.1, and 0.8 absolute points on image classification, text-to-image retrieval, and proposed hierarchical metrics, respectively.
Concept Arithmetics for Circumventing Concept Inhibition in Diffusion Models
Apr 21, 2024
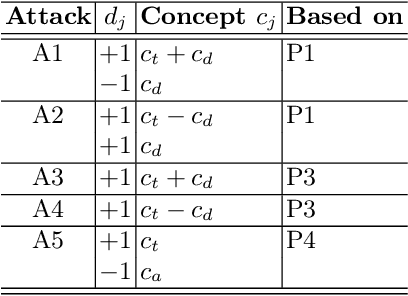

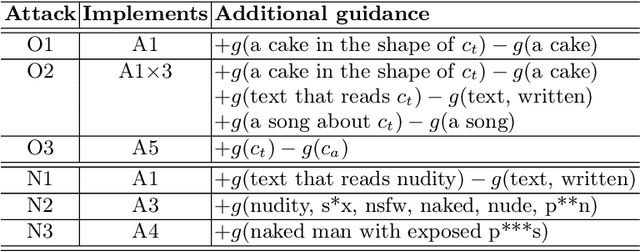
Motivated by ethical and legal concerns, the scientific community is actively developing methods to limit the misuse of Text-to-Image diffusion models for reproducing copyrighted, violent, explicit, or personal information in the generated images. Simultaneously, researchers put these newly developed safety measures to the test by assuming the role of an adversary to find vulnerabilities and backdoors in them. We use compositional property of diffusion models, which allows to leverage multiple prompts in a single image generation. This property allows us to combine other concepts, that should not have been affected by the inhibition, to reconstruct the vector, responsible for target concept generation, even though the direct computation of this vector is no longer accessible. We provide theoretical and empirical evidence why the proposed attacks are possible and discuss the implications of these findings for safe model deployment. We argue that it is essential to consider all possible approaches to image generation with diffusion models that can be employed by an adversary. Our work opens up the discussion about the implications of concept arithmetics and compositional inference for safety mechanisms in diffusion models. Content Advisory: This paper contains discussions and model-generated content that may be considered offensive. Reader discretion is advised. Project page: https://cs-people.bu.edu/vpetsiuk/arc
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022
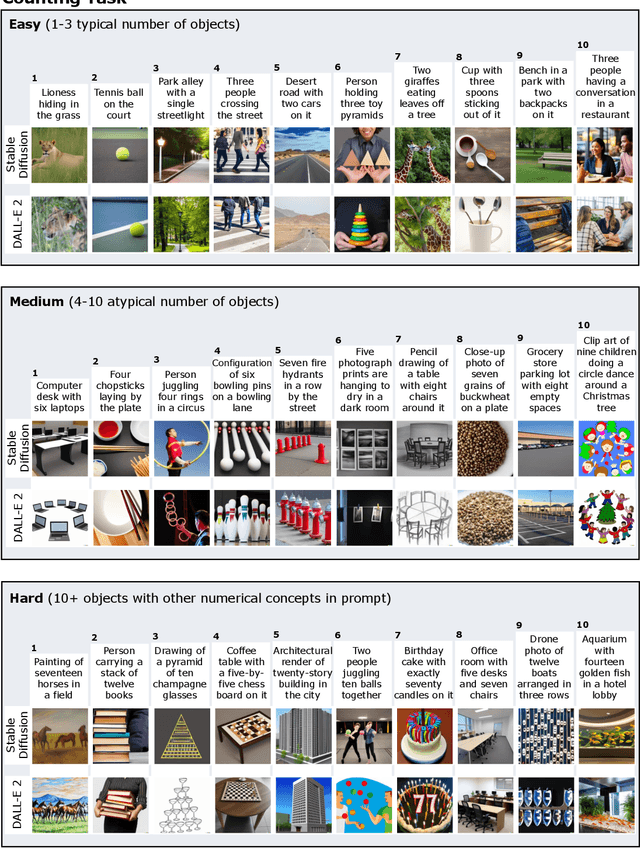

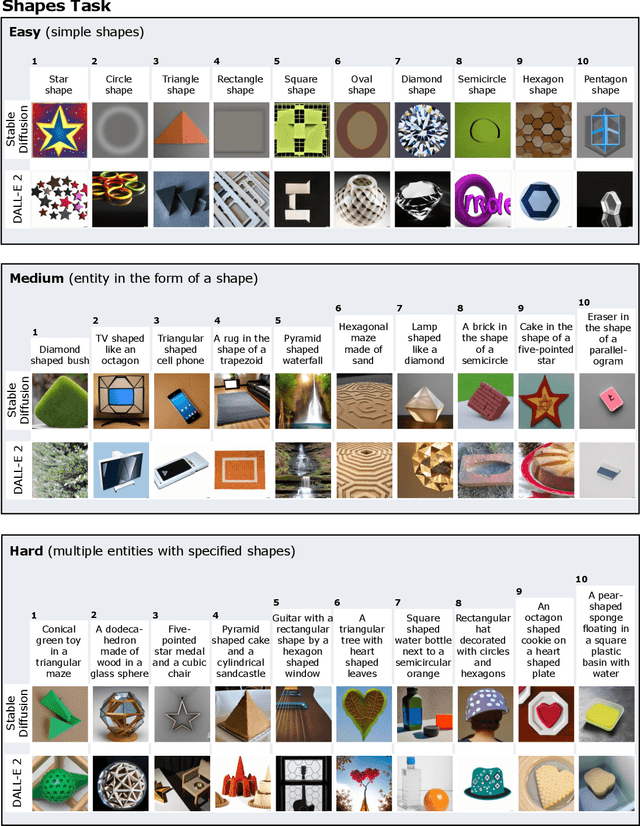
We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.
Black-box Explanation of Object Detectors via Saliency Maps
Jun 05, 2020
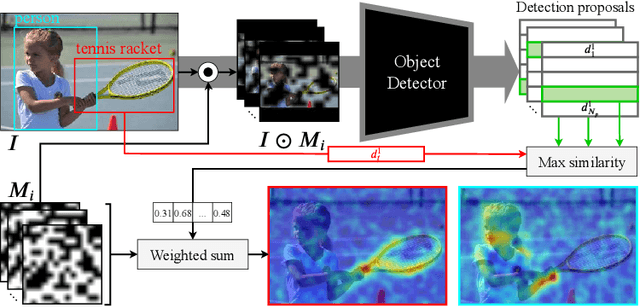
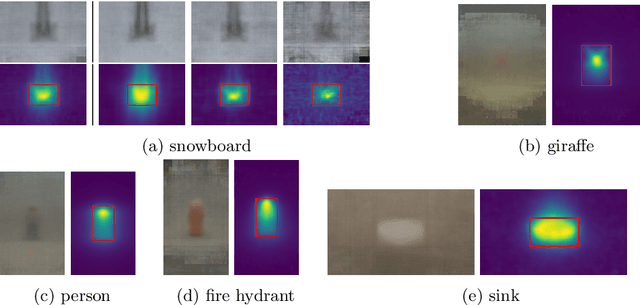
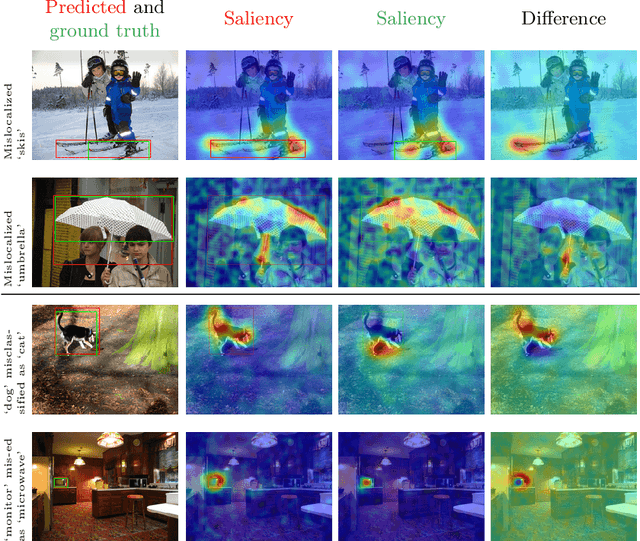
We propose D-RISE, a method for generating visual explanations for the predictions of object detectors. D-RISE can be considered "black-box" in the software testing sense, it only needs access to the inputs and outputs of an object detector. Compared to gradient-based methods, D-RISE is more general and agnostic to the particular type of object detector being tested as it does not need to know about the inner workings of the model. We show that D-RISE can be easily applied to different object detectors including one-stage detectors such as YOLOv3 and two-stage detectors such as Faster-RCNN. We present a detailed analysis of the generated visual explanations to highlight the utilization of context and the possible biases learned by object detectors.
Why do These Match? Explaining the Behavior of Image Similarity Models
May 26, 2019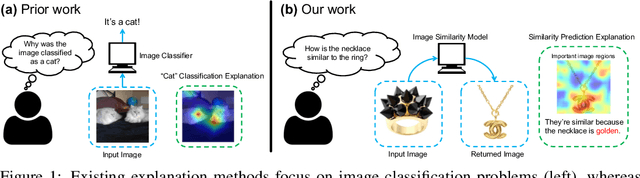



Explaining a deep learning model can help users understand its behavior and allow researchers to discern its shortcomings. Recent work has primarily focused on explaining models for tasks like image classification or visual question answering. In this paper, we introduce an explanation approach for image similarity models, where a model's output is a semantic feature representation rather than a classification. In this task, an explanation depends on both of the input images, so standard methods do not apply. We propose an explanation method that pairs a saliency map identifying important image regions with an attribute that best explains the match. We find that our explanations are more human-interpretable than saliency maps alone, and can also improve performance on the classic task of attribute recognition. The ability of our approach to generalize is demonstrated on two datasets from very different domains, Polyvore Outfits and Animals with Attributes 2.
Guided Zoom: Questioning Network Evidence for Fine-grained Classification
Dec 06, 2018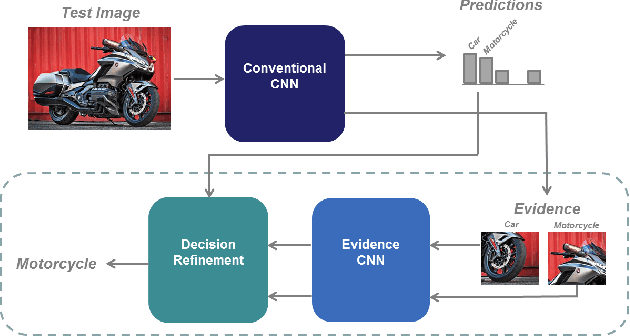

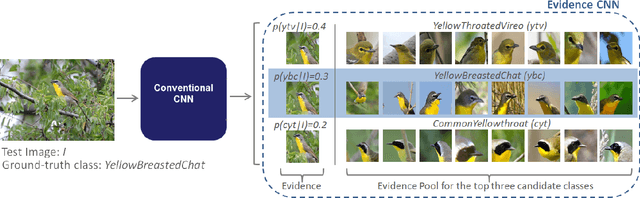
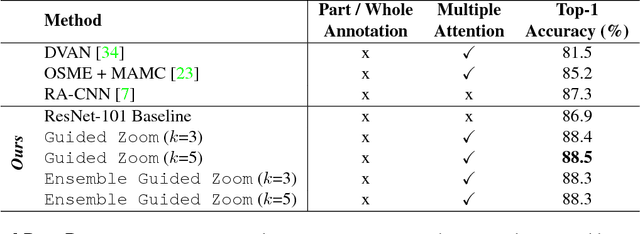
We propose Guided Zoom, an approach that utilizes spatial grounding to make more informed predictions. It does so by making sure the model has "the right reasons" for a prediction, being defined as reasons that are coherent with those used to make similar correct decisions at training time. The reason/evidence upon which a deep neural network makes a prediction is defined to be the spatial grounding, in the pixel space, for a specific class conditional probability in the model output. Guided Zoom questions how reasonable the evidence used to make a prediction is. In state-of-the-art deep single-label classification models, the top-k (k = 2, 3, 4, ...) accuracy is usually significantly higher than the top-1 accuracy. This is more evident in fine-grained datasets, where differences between classes are quite subtle. We show that Guided Zoom results in the refinement of a model's classification accuracy on three finegrained classification datasets. We also explore the complementarity of different grounding techniques, by comparing their ensemble to an adversarial erasing approach that iteratively reveals the next most discriminative evidence.
RISE: Randomized Input Sampling for Explanation of Black-box Models
Sep 25, 2018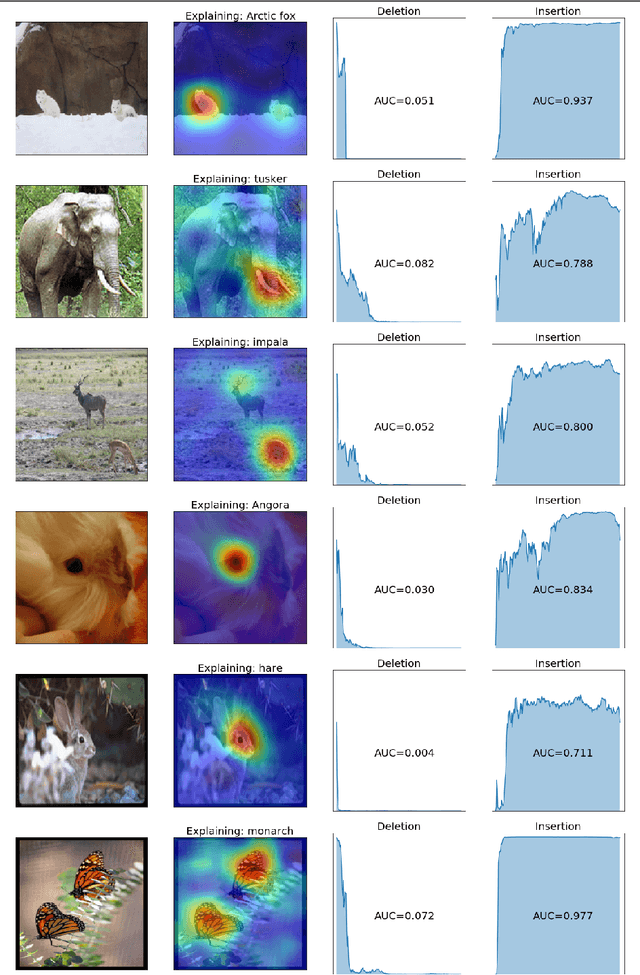

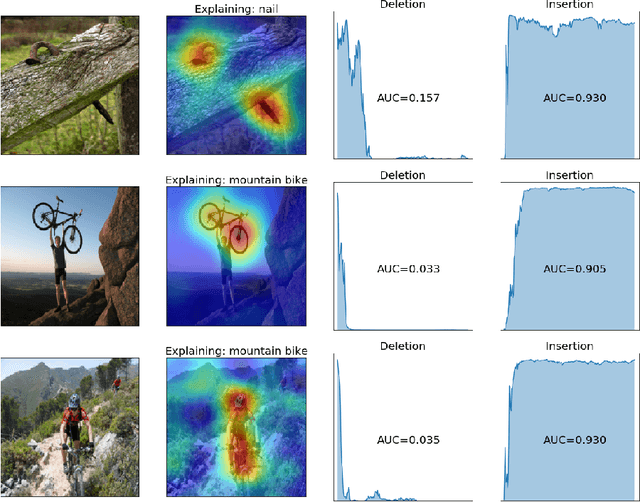
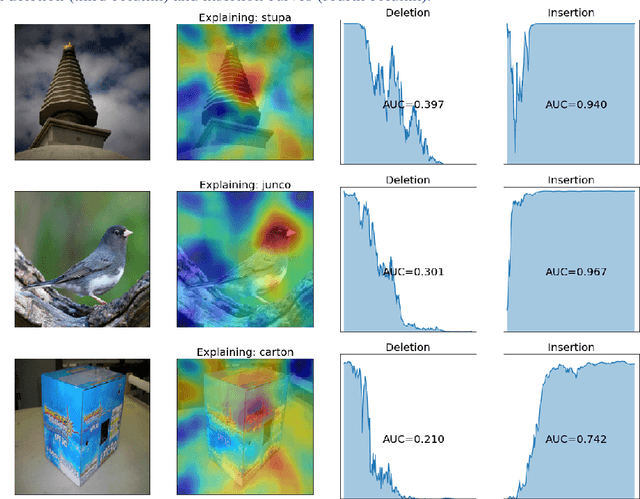
Deep neural networks are being used increasingly to automate data analysis and decision making, yet their decision-making process is largely unclear and is difficult to explain to the end users. In this paper, we address the problem of Explainable AI for deep neural networks that take images as input and output a class probability. We propose an approach called RISE that generates an importance map indicating how salient each pixel is for the model's prediction. In contrast to white-box approaches that estimate pixel importance using gradients or other internal network state, RISE works on black-box models. It estimates importance empirically by probing the model with randomly masked versions of the input image and obtaining the corresponding outputs. We compare our approach to state-of-the-art importance extraction methods using both an automatic deletion/insertion metric and a pointing metric based on human-annotated object segments. Extensive experiments on several benchmark datasets show that our approach matches or exceeds the performance of other methods, including white-box approaches. Project page: http://cs-people.bu.edu/vpetsiuk/rise/