 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning robotics using self-supervised spatial differentiation drive autonomous contact-based semiconductor characterization
Nov 15, 2024



Integrating autonomous contact-based robotic characterization into self-driving laboratories can enhance measurement quality, reliability, and throughput. While deep learning models support robust autonomy, current methods lack pixel-precision positioning and require extensive labeled data. To overcome these challenges, we propose a self-supervised convolutional neural network with a spatially differentiable loss function, incorporating shape priors to refine predictions of optimal robot contact poses for semiconductor characterization. This network improves valid pose generation by 20.0%, relative to existing models. We demonstrate our network's performance by driving a 4-degree-of-freedom robot to characterize photoconductivity at 3,025 predicted poses across a gradient of perovskite compositions, achieving throughputs over 125 measurements per hour. Spatially mapping photoconductivity onto each drop-casted film reveals regions of inhomogeneity. With this self-supervised deep learning-driven robotic system, we enable high-precision and reliable automation of contact-based characterization techniques at high throughputs, thereby allowing the measurement of previously inaccessible yet important semiconductor properties for self-driving laboratories.
Decreasing the Computing Time of Bayesian Optimization using Generalizable Memory Pruning
Sep 08, 2023Bayesian optimization (BO) suffers from long computing times when processing highly-dimensional or large data sets. These long computing times are a result of the Gaussian process surrogate model having a polynomial time complexity with the number of experiments. Running BO on high-dimensional or massive data sets becomes intractable due to this time complexity scaling, in turn, hindering experimentation. Alternative surrogate models have been developed to reduce the computing utilization of the BO procedure, however, these methods require mathematical alteration of the inherit surrogate function, pigeonholing use into only that function. In this paper, we demonstrate a generalizable BO wrapper of memory pruning and bounded optimization, capable of being used with any surrogate model and acquisition function. Using this memory pruning approach, we show a decrease in wall-clock computing times per experiment of BO from a polynomially increasing pattern to a sawtooth pattern that has a non-increasing trend without sacrificing convergence performance. Furthermore, we illustrate the generalizability of the approach across two unique data sets, two unique surrogate models, and four unique acquisition functions. All model implementations are run on the MIT Supercloud state-of-the-art computing hardware.
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022
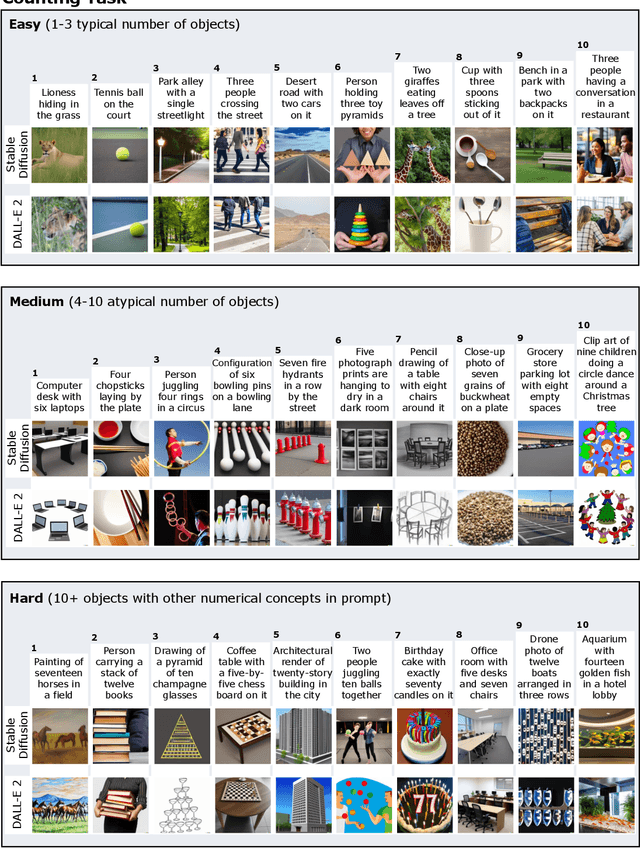

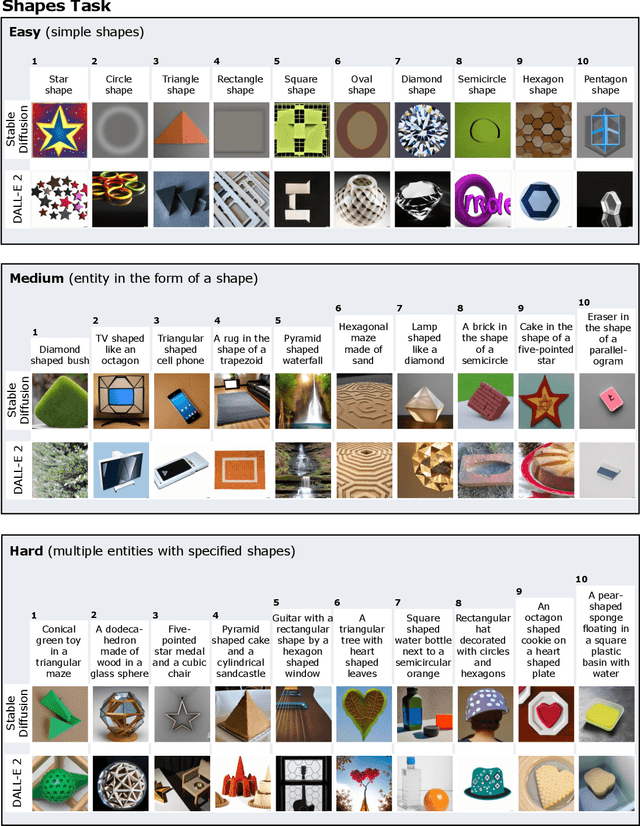
We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.
Fast Bayesian Optimization of Needle-in-a-Haystack Problems using Zooming Memory-Based Initialization
Aug 26, 2022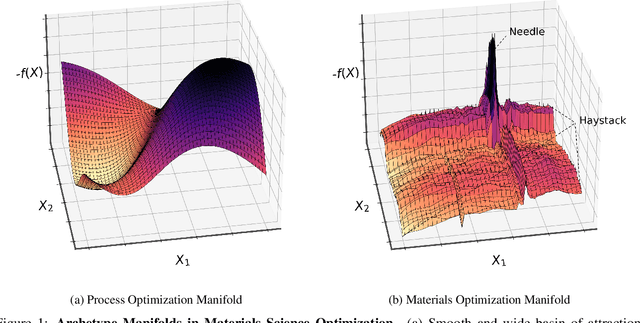
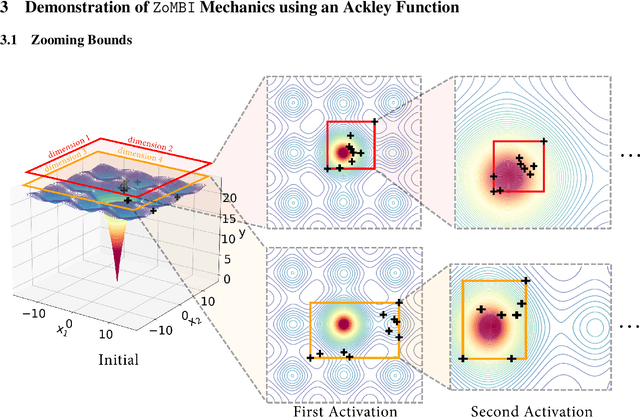
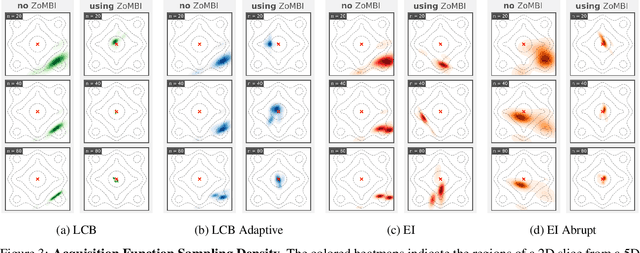
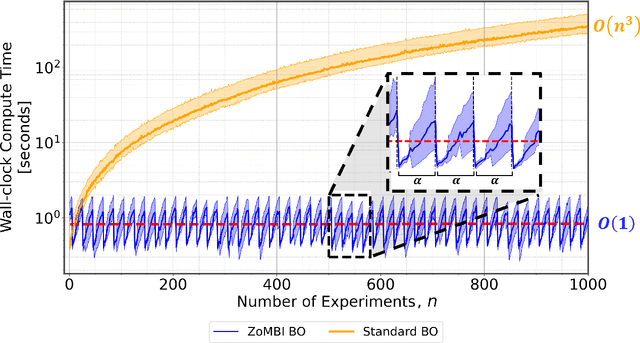
Needle-in-a-Haystack problems exist across a wide range of applications including rare disease prediction, ecological resource management, fraud detection, and material property optimization. A Needle-in-a-Haystack problem arises when there is an extreme imbalance of optimum conditions relative to the size of the dataset. For example, only 0.82% out of 146k total materials in the open-access Materials Project database have a negative Poisson's ratio. However, current state-of-the-art optimization algorithms are not designed with the capabilities to find solutions to these challenging multidimensional Needle-in-a-Haystack problems, resulting in slow convergence to a global optimum or pigeonholing into a local minimum. In this paper, we present a Zooming Memory-Based Initialization algorithm, entitled ZoMBI, that builds on conventional Bayesian optimization principles to quickly and efficiently optimize Needle-in-a-Haystack problems in both less time and fewer experiments by addressing the common convergence and pigeonholing issues. ZoMBI actively extracts knowledge from the previously best-performing evaluated experiments to iteratively zoom in the sampling search bounds towards the global optimum "needle" and then prunes the memory of low-performing historical experiments to accelerate compute times. We validate the algorithm's performance on two real-world 5-dimensional Needle-in-a-Haystack material property optimization datasets: discovery of auxetic Poisson's ratio materials and discovery of high thermoelectric figure of merit materials. The ZoMBI algorithm demonstrates compute time speed-ups of 400x compared to traditional Bayesian optimization as well as efficiently discovering materials in under 100 experiments that are up to 3x more highly optimized than those discovered by current state-of-the-art algorithms.
Autonomous Optimization of Fluid Systems at Varying Length Scales
Jun 10, 2021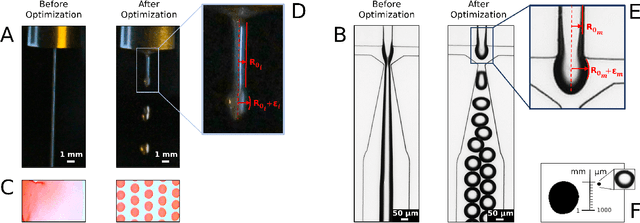
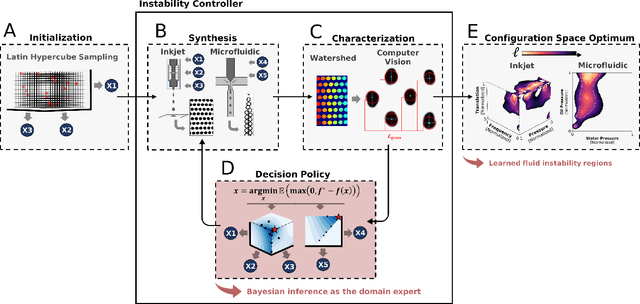
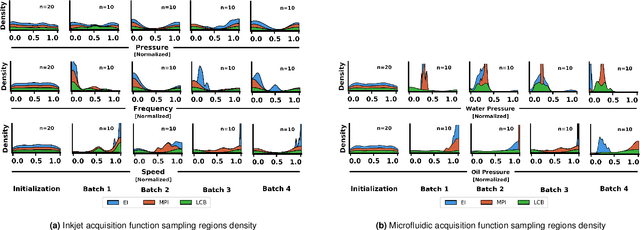
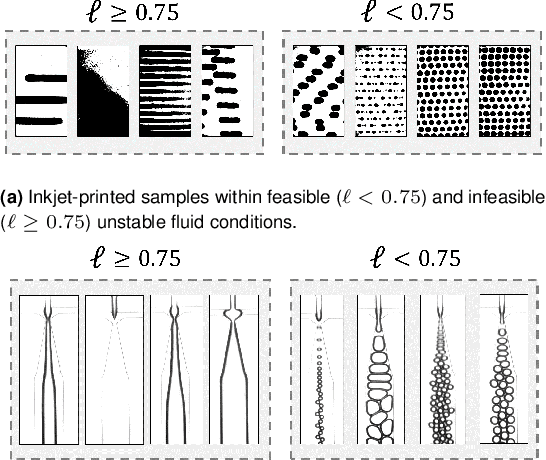
Autonomous optimization is a process by which hardware conditions are discovered that generate an optimized experimental product without the guidance of a domain expert. We design an autonomous optimization framework to discover the experimental conditions within fluid systems that generate discrete and uniform droplet patterns. Generating discrete and uniform droplets requires high-precision control over the experimental conditions of a fluid system. Fluid stream instabilities, such as Rayleigh-Plateau instability and capillary instability, drive the separation of a flow into individual droplets. However, because this phenomenon leverages an instability, by nature the hardware must be precisely tuned to achieve uniform, repeatable droplets. Typically this requires a domain expert in the loop and constant re-tuning depending on the hardware configuration and liquid precursor selection. Herein, we propose a computer vision-driven Bayesian optimization framework to discover the precise hardware conditions that generate uniform, reproducible droplets with the desired features, leveraging flow instability without a domain expert in the loop. This framework is validated on two fluid systems, at the micrometer and millimeter length scales, using microfluidic and inkjet systems, respectively, indicating the application breadth of this approach.
Online Preconditioning of Experimental Inkjet Hardware by Bayesian Optimization in Loop
May 06, 2021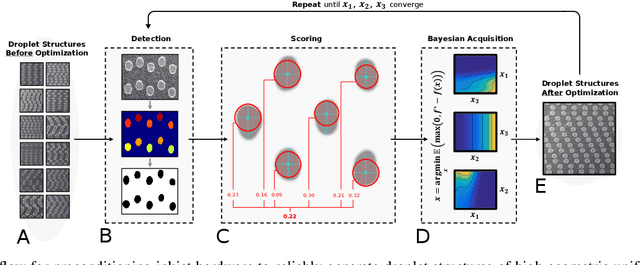
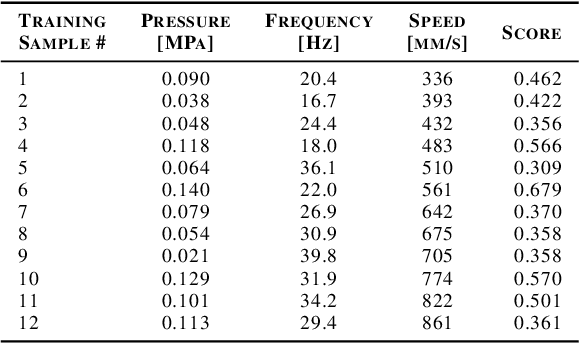
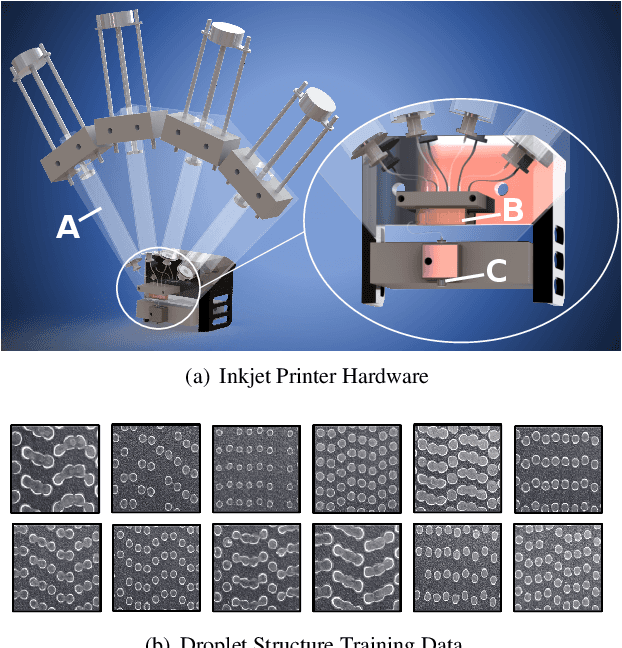
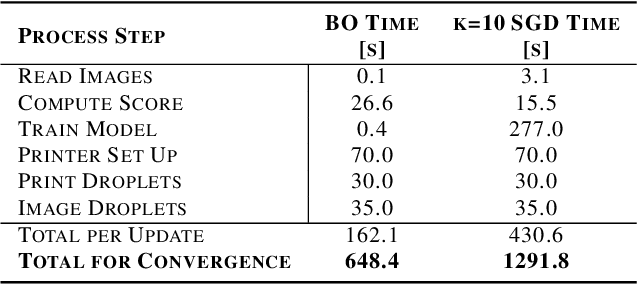
High-performance semiconductor optoelectronics such as perovskites have high-dimensional and vast composition spaces that govern the performance properties of the material. To cost-effectively search these composition spaces, we utilize a high-throughput experimentation method of rapidly printing discrete droplets via inkjet deposition, in which each droplet is comprised of a unique permutation of semiconductor materials. However, inkjet printer systems are not optimized to run high-throughput experimentation on semiconductor materials. Thus, in this work, we develop a computer vision-driven Bayesian optimization framework for optimizing the deposited droplet structures from an inkjet printer such that it is tuned to perform high-throughput experimentation on semiconductor materials. The goal of this framework is to tune to the hardware conditions of the inkjet printer in the shortest amount of time using the fewest number of droplet samples such that we minimize the time and resources spent on setting the system up for material discovery applications. We demonstrate convergence on optimum inkjet hardware conditions in 10 minutes using Bayesian optimization of computer vision-scored droplet structures. We compare our Bayesian optimization results with stochastic gradient descent.