 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Bayesian Optimization for High-Dimensional Experimental Design: Simulation and Visualization
Apr 04, 2025



Bayesian Optimization (BO) is increasingly used to guide experimental optimization tasks. To elucidate BO behavior in noisy and high-dimensional settings typical for materials science applications, we perform batch BO of two six-dimensional test functions: an Ackley function representing a needle-in-a-haystack problem and a Hartmann function representing a problem with a false maximum with a value close to the global maximum. We show learning curves, performance metrics, and visualization to effectively track the evolution of optimization in high dimensions and evaluate how they are affected by noise, batch-picking method, choice of acquisition function,and its exploration hyperparameter values. We find that the effects of noise depend on the problem landscape; therefore, prior knowledge of the domain structure and noise level is needed when designing BO. The Ackley function optimization is significantly degraded by noise with a complete loss of ground truth resemblance when noise equals 10 % of the maximum objective value. For the Hartmann function, even in the absence of noise, a significant fraction of the initial samplings identify the false maximum instead of the ground truth maximum as the optimum of the function; with increasing noise, BO remains effective, albeit with increasing probability of landing on the false maximum. This study systematically highlights the critical issues when setting up BO and choosing synthetic data to test experimental design. The results and methodology will facilitate wider utilization of BO in guiding experiments, specifically in high-dimensional settings.
Deep learning robotics using self-supervised spatial differentiation drive autonomous contact-based semiconductor characterization
Nov 15, 2024



Integrating autonomous contact-based robotic characterization into self-driving laboratories can enhance measurement quality, reliability, and throughput. While deep learning models support robust autonomy, current methods lack pixel-precision positioning and require extensive labeled data. To overcome these challenges, we propose a self-supervised convolutional neural network with a spatially differentiable loss function, incorporating shape priors to refine predictions of optimal robot contact poses for semiconductor characterization. This network improves valid pose generation by 20.0%, relative to existing models. We demonstrate our network's performance by driving a 4-degree-of-freedom robot to characterize photoconductivity at 3,025 predicted poses across a gradient of perovskite compositions, achieving throughputs over 125 measurements per hour. Spatially mapping photoconductivity onto each drop-casted film reveals regions of inhomogeneity. With this self-supervised deep learning-driven robotic system, we enable high-precision and reliable automation of contact-based characterization techniques at high throughputs, thereby allowing the measurement of previously inaccessible yet important semiconductor properties for self-driving laboratories.
Decreasing the Computing Time of Bayesian Optimization using Generalizable Memory Pruning
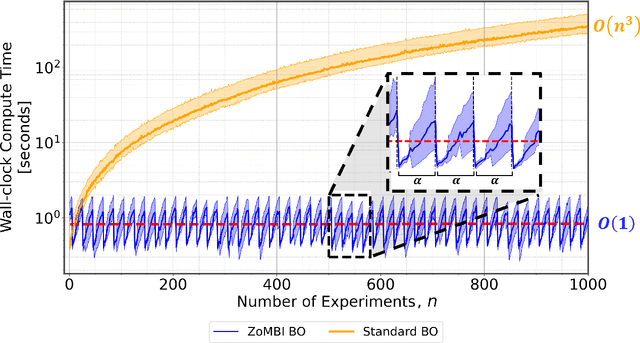
Sep 08, 2023Bayesian optimization (BO) suffers from long computing times when processing highly-dimensional or large data sets. These long computing times are a result of the Gaussian process surrogate model having a polynomial time complexity with the number of experiments. Running BO on high-dimensional or massive data sets becomes intractable due to this time complexity scaling, in turn, hindering experimentation. Alternative surrogate models have been developed to reduce the computing utilization of the BO procedure, however, these methods require mathematical alteration of the inherit surrogate function, pigeonholing use into only that function. In this paper, we demonstrate a generalizable BO wrapper of memory pruning and bounded optimization, capable of being used with any surrogate model and acquisition function. Using this memory pruning approach, we show a decrease in wall-clock computing times per experiment of BO from a polynomially increasing pattern to a sawtooth pattern that has a non-increasing trend without sacrificing convergence performance. Furthermore, we illustrate the generalizability of the approach across two unique data sets, two unique surrogate models, and four unique acquisition functions. All model implementations are run on the MIT Supercloud state-of-the-art computing hardware.
Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models
Jun 24, 2023



We curate a comprehensive dataset of 4,550 questions and solutions from problem sets, midterm exams, and final exams across all MIT Mathematics and Electrical Engineering and Computer Science (EECS) courses required for obtaining a degree. We evaluate the ability of large language models to fulfill the graduation requirements for any MIT major in Mathematics and EECS. Our results demonstrate that GPT-3.5 successfully solves a third of the entire MIT curriculum, while GPT-4, with prompt engineering, achieves a perfect solve rate on a test set excluding questions based on images. We fine-tune an open-source large language model on this dataset. We employ GPT-4 to automatically grade model responses, providing a detailed performance breakdown by course, question, and answer type. By embedding questions in a low-dimensional space, we explore the relationships between questions, topics, and classes and discover which questions and classes are required for solving other questions and classes through few-shot learning. Our analysis offers valuable insights into course prerequisites and curriculum design, highlighting language models' potential for learning and improving Mathematics and EECS education.
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022
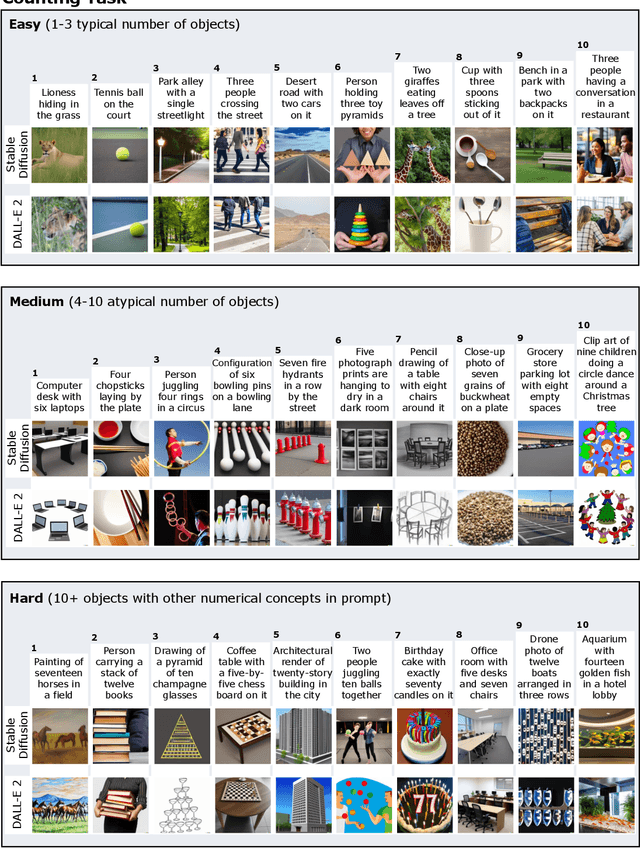

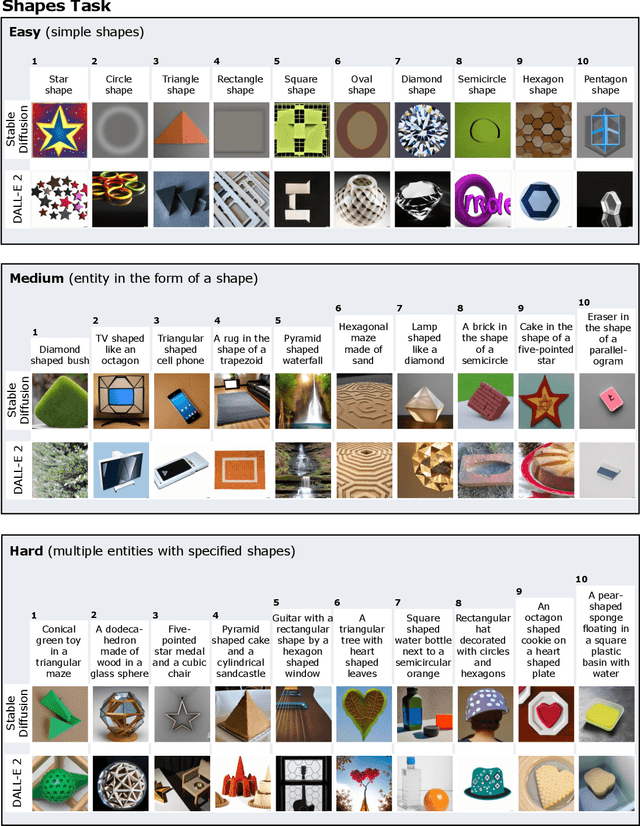
We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.
Fast Bayesian Optimization of Needle-in-a-Haystack Problems using Zooming Memory-Based Initialization
Aug 26, 2022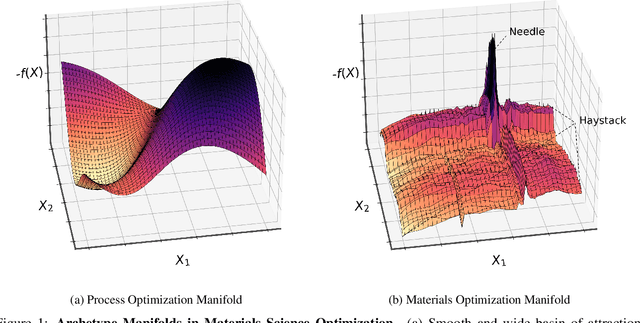
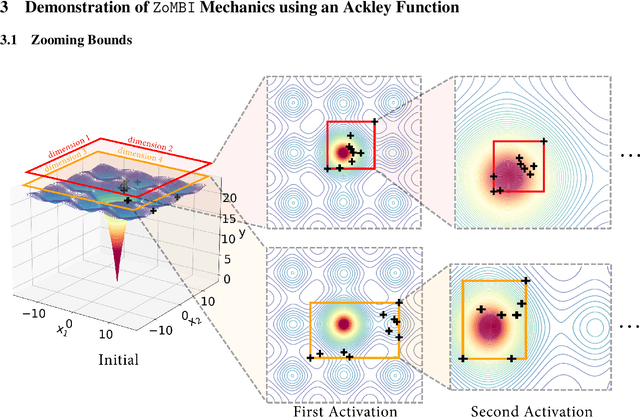
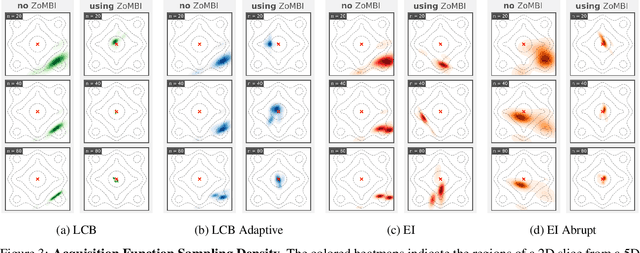
Needle-in-a-Haystack problems exist across a wide range of applications including rare disease prediction, ecological resource management, fraud detection, and material property optimization. A Needle-in-a-Haystack problem arises when there is an extreme imbalance of optimum conditions relative to the size of the dataset. For example, only 0.82% out of 146k total materials in the open-access Materials Project database have a negative Poisson's ratio. However, current state-of-the-art optimization algorithms are not designed with the capabilities to find solutions to these challenging multidimensional Needle-in-a-Haystack problems, resulting in slow convergence to a global optimum or pigeonholing into a local minimum. In this paper, we present a Zooming Memory-Based Initialization algorithm, entitled ZoMBI, that builds on conventional Bayesian optimization principles to quickly and efficiently optimize Needle-in-a-Haystack problems in both less time and fewer experiments by addressing the common convergence and pigeonholing issues. ZoMBI actively extracts knowledge from the previously best-performing evaluated experiments to iteratively zoom in the sampling search bounds towards the global optimum "needle" and then prunes the memory of low-performing historical experiments to accelerate compute times. We validate the algorithm's performance on two real-world 5-dimensional Needle-in-a-Haystack material property optimization datasets: discovery of auxetic Poisson's ratio materials and discovery of high thermoelectric figure of merit materials. The ZoMBI algorithm demonstrates compute time speed-ups of 400x compared to traditional Bayesian optimization as well as efficiently discovering materials in under 100 experiments that are up to 3x more highly optimized than those discovered by current state-of-the-art algorithms.
Introducing flexible perovskites to the IoT world using photovoltaic-powered wireless tags
Jul 01, 2022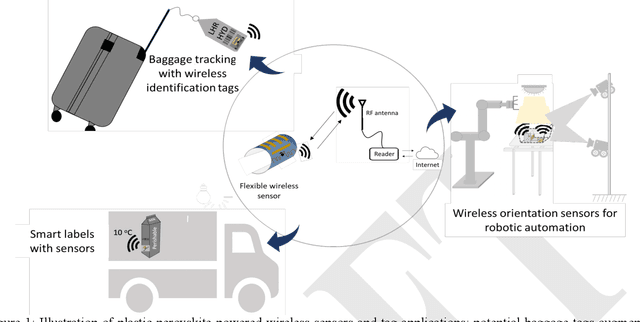
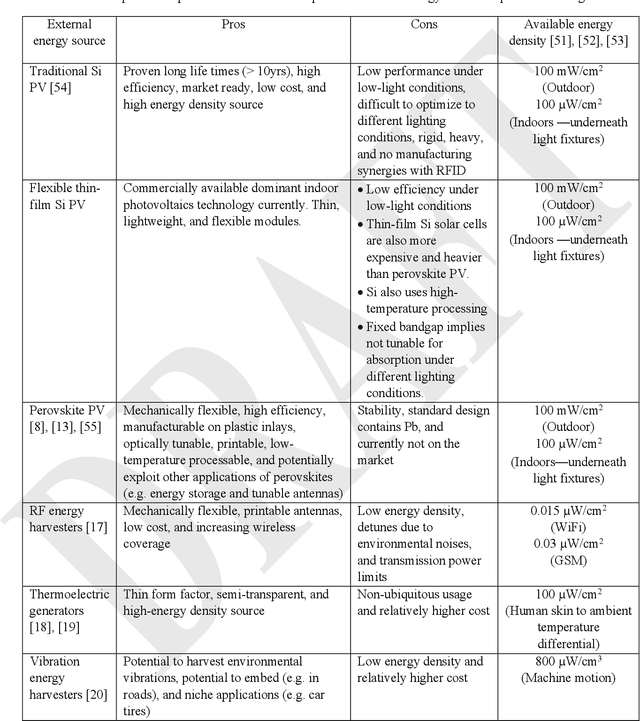
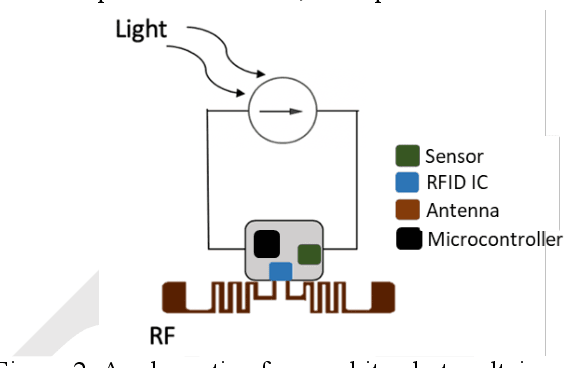
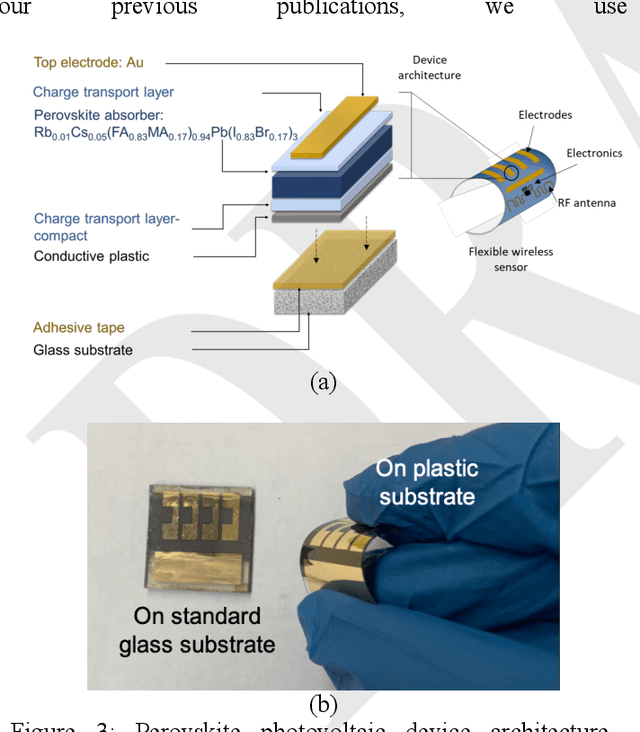
Billions of everyday objects could become part of the Internet of Things (IoT) by augmentation with low-cost, long-range, maintenance-free wireless sensors. Radio Frequency Identification (RFID) is a low-cost wireless technology that could enable this vision, but it is constrained by short communication range and lack of sufficient energy available to power auxiliary electronics and sensors. Here, we explore the use of flexible perovskite photovoltaic cells to provide external power to semi-passive RFID tags to increase range and energy availability for external electronics such as microcontrollers and digital sensors. Perovskites are intriguing materials that hold the possibility to develop high-performance, low-cost, optically tunable (to absorb different light spectra), and flexible light energy harvesters. Our prototype perovskite photovoltaic cells on plastic substrates have an efficiency of 13% and a voltage of 0.88 V at maximum power under standard testing conditions. We built prototypes of RFID sensors powered with these flexible photovoltaic cells to demonstrate real-world applications. Our evaluation of the prototypes suggests that: i) flexible PV cells are durable up to a bending radius of 5 mm with only a 20 % drop in relative efficiency; ii) RFID communication range increased by 5x, and meets the energy needs (10-350 microwatt) to enable self-powered wireless sensors; iii) perovskite powered wireless sensors enable many battery-less sensing applications (e.g., perishable good monitoring, warehouse automation)
Interpretable and Explainable Machine Learning for Materials Science and Chemistry
Nov 03, 2021
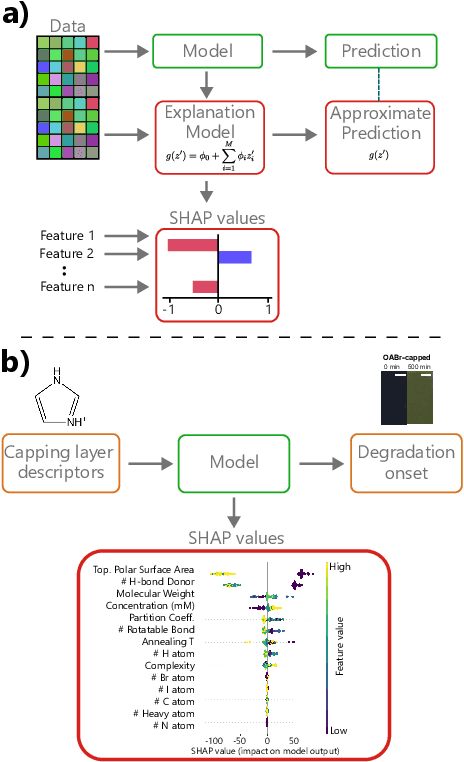
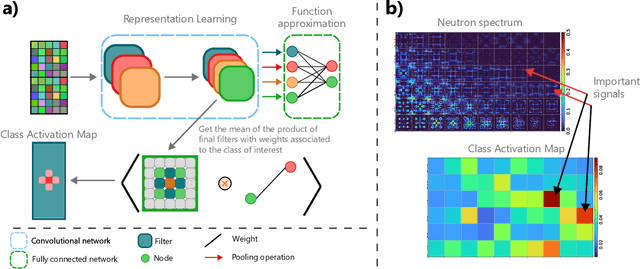
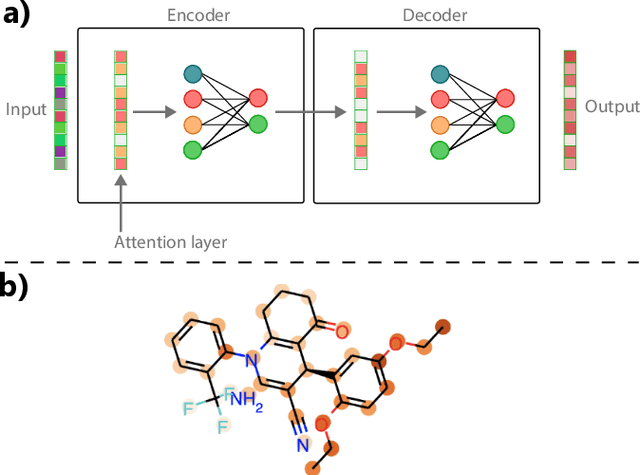
While the uptake of data-driven approaches for materials science and chemistry is at an exciting, early stage, to realise the true potential of machine learning models for successful scientific discovery, they must have qualities beyond purely predictive power. The predictions and inner workings of models should provide a certain degree of explainability by human experts, permitting the identification of potential model issues or limitations, building trust on model predictions and unveiling unexpected correlations that may lead to scientific insights. In this work, we summarize applications of interpretability and explainability techniques for materials science and chemistry and discuss how these techniques can improve the outcome of scientific studies. We discuss various challenges for interpretable machine learning in materials science and, more broadly, in scientific settings. In particular, we emphasize the risks of inferring causation or reaching generalization by purely interpreting machine learning models and the need of uncertainty estimates for model explanations. Finally, we showcase a number of exciting developments in other fields that could benefit interpretability in material science and chemistry problems.
Machine Learning with Knowledge Constraints for Process Optimization of Open-Air Perovskite Solar Cell Manufacturing
Oct 15, 2021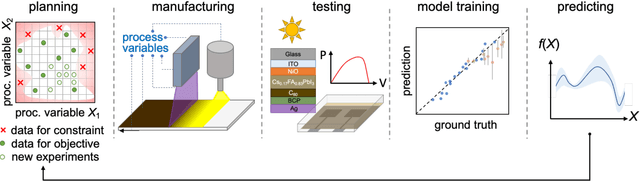
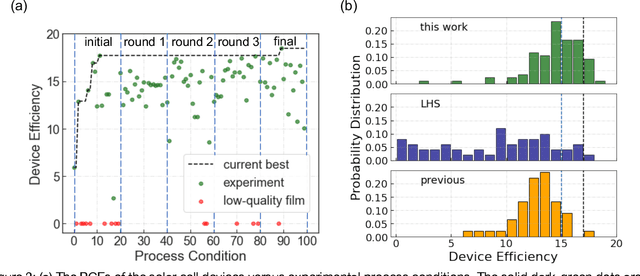
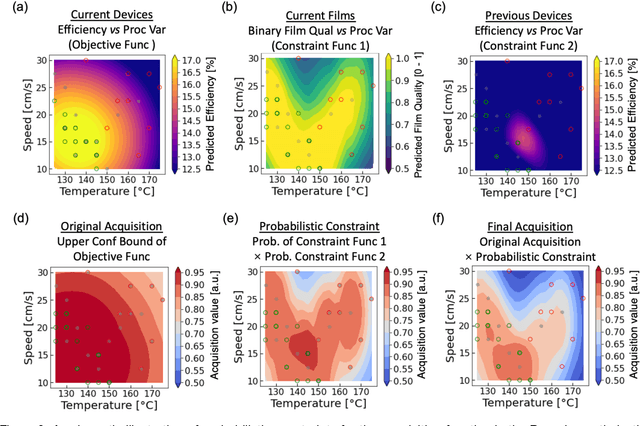
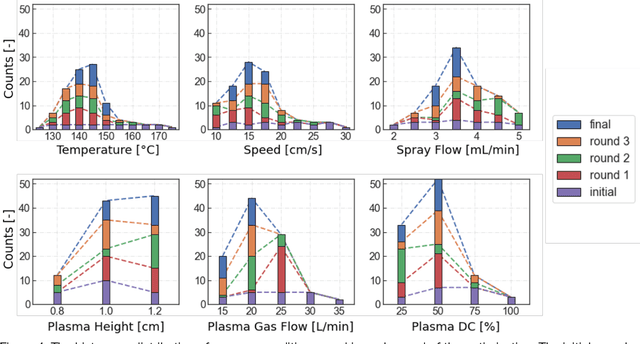
Perovskite photovoltaics (PV) have achieved rapid development in the past decade in terms of power conversion efficiency of small-area lab-scale devices; however, successful commercialization still requires further development of low-cost, scalable, and high-throughput manufacturing techniques. One of the key challenges to the development of a new fabrication technique is the high-dimensional parameter space, and machine learning (ML) can be used to accelerate perovskite PV scaling. Here, we present an ML-guided framework of sequential learning for manufacturing process optimization. We apply our methodology to the Rapid Spray Plasma Processing (RSPP) technique for perovskite thin films in ambient conditions. With a limited experimental budget of screening 100 conditions process conditions, we demonstrated an efficiency improvement to 18.5% for the best device, and we also experimentally found 10 unique conditions to produce the top-performing devices of more than 17% efficiency, which is 5 times higher rate of success than pseudo-random Latin hypercube sampling. Our model is enabled by three innovations: (a) flexible knowledge transfer between experimental processes by incorporating data from prior experimental data as a soft constraint; (b) incorporation of both subjective human observations and ML insights when selecting next experiments; (c) adaptive strategy of locating the region of interest using Bayesian optimization first, and then conducting local exploration for high-efficiency devices. Furthermore, in virtual benchmarking, our framework achieves faster improvements with limited experimental budgets than traditional design-of-experiments methods (e.g., one-variable-at-a-time sampling).
Opportunities for Machine Learning to Accelerate Halide Perovskite Commercialization and Scale-Up
Oct 08, 2021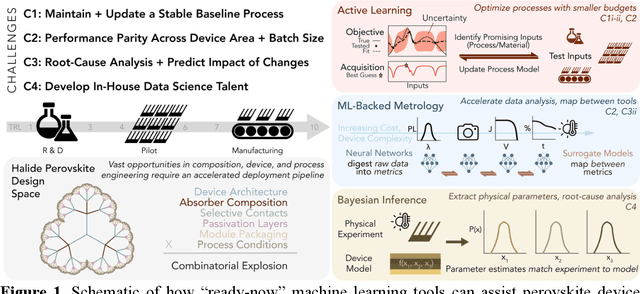
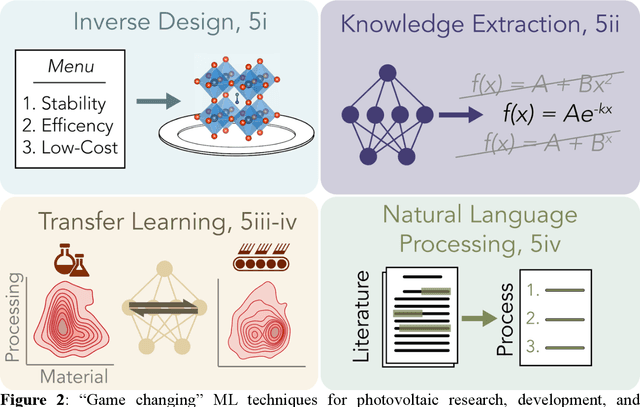
While halide perovskites attract significant academic attention, examples of at-scale industrial production are still sparse. In this perspective, we review practical challenges hindering the commercialization of halide perovskites, and discuss how machine-learning (ML) tools could help: (1) active-learning algorithms that blend institutional knowledge and human expertise could help stabilize and rapidly update baseline manufacturing processes; (2) ML-powered metrology, including computer imaging, could help narrow the performance gap between large- and small-area devices; and (3) inference methods could help accelerate root-cause analysis by reconciling multiple data streams and simulations, focusing research effort on areas with highest probability for improvement. We conclude that to satisfy many of these challenges, incremental -- not radical -- adaptations of existing ML and statistical methods are needed. We identify resources to help develop in-house data-science talent, and propose how industry-academic partnerships could help adapt "ready-now" ML tools to specific industry needs, further improve process control by revealing underlying mechanisms, and develop "gamechanger" discovery-oriented algorithms to better navigate vast materials combination spaces and the literature.