 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Bayesian Optimization for High-Dimensional Experimental Design: Simulation and Visualization
Apr 04, 2025



Bayesian Optimization (BO) is increasingly used to guide experimental optimization tasks. To elucidate BO behavior in noisy and high-dimensional settings typical for materials science applications, we perform batch BO of two six-dimensional test functions: an Ackley function representing a needle-in-a-haystack problem and a Hartmann function representing a problem with a false maximum with a value close to the global maximum. We show learning curves, performance metrics, and visualization to effectively track the evolution of optimization in high dimensions and evaluate how they are affected by noise, batch-picking method, choice of acquisition function,and its exploration hyperparameter values. We find that the effects of noise depend on the problem landscape; therefore, prior knowledge of the domain structure and noise level is needed when designing BO. The Ackley function optimization is significantly degraded by noise with a complete loss of ground truth resemblance when noise equals 10 % of the maximum objective value. For the Hartmann function, even in the absence of noise, a significant fraction of the initial samplings identify the false maximum instead of the ground truth maximum as the optimum of the function; with increasing noise, BO remains effective, albeit with increasing probability of landing on the false maximum. This study systematically highlights the critical issues when setting up BO and choosing synthetic data to test experimental design. The results and methodology will facilitate wider utilization of BO in guiding experiments, specifically in high-dimensional settings.
Cost-aware learning of relevant contextual variables within Bayesian optimization
May 24, 2023

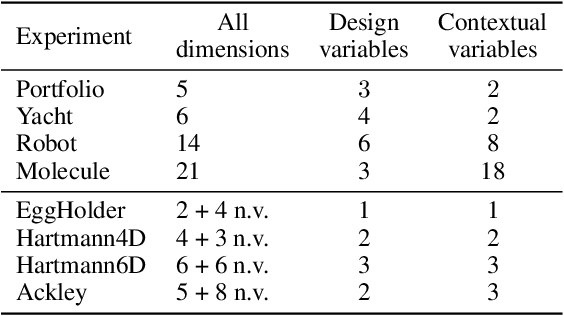

Contextual Bayesian Optimization (CBO) is a powerful framework for optimizing black-box, expensive-to-evaluate functions with respect to design variables, while simultaneously efficiently integrating relevant contextual information regarding the environment, such as experimental conditions. However, in many practical scenarios, the relevance of contextual variables is not necessarily known beforehand. Moreover, the contextual variables can sometimes be optimized themselves, a setting that current CBO algorithms do not take into account. Optimizing contextual variables may be costly, which raises the question of determining a minimal relevant subset. In this paper, we frame this problem as a cost-aware model selection BO task and address it using a novel method, Sensitivity-Analysis-Driven Contextual BO (SADCBO). We learn the relevance of context variables by sensitivity analysis of the posterior surrogate model at specific input points, whilst minimizing the cost of optimization by leveraging recent developments on early stopping for BO. We empirically evaluate our proposed SADCBO against alternatives on synthetic experiments together with extensive ablation studies, and demonstrate a consistent improvement across examples.
Opportunities for Machine Learning to Accelerate Halide Perovskite Commercialization and Scale-Up
Oct 08, 2021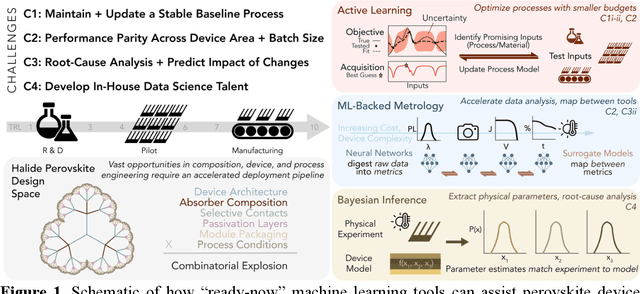
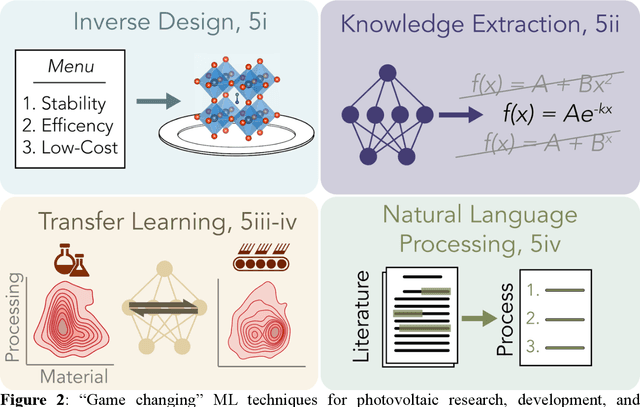
While halide perovskites attract significant academic attention, examples of at-scale industrial production are still sparse. In this perspective, we review practical challenges hindering the commercialization of halide perovskites, and discuss how machine-learning (ML) tools could help: (1) active-learning algorithms that blend institutional knowledge and human expertise could help stabilize and rapidly update baseline manufacturing processes; (2) ML-powered metrology, including computer imaging, could help narrow the performance gap between large- and small-area devices; and (3) inference methods could help accelerate root-cause analysis by reconciling multiple data streams and simulations, focusing research effort on areas with highest probability for improvement. We conclude that to satisfy many of these challenges, incremental -- not radical -- adaptations of existing ML and statistical methods are needed. We identify resources to help develop in-house data-science talent, and propose how industry-academic partnerships could help adapt "ready-now" ML tools to specific industry needs, further improve process control by revealing underlying mechanisms, and develop "gamechanger" discovery-oriented algorithms to better navigate vast materials combination spaces and the literature.
Benchmarking the Performance of Bayesian Optimization across Multiple Experimental Materials Science Domains
May 23, 2021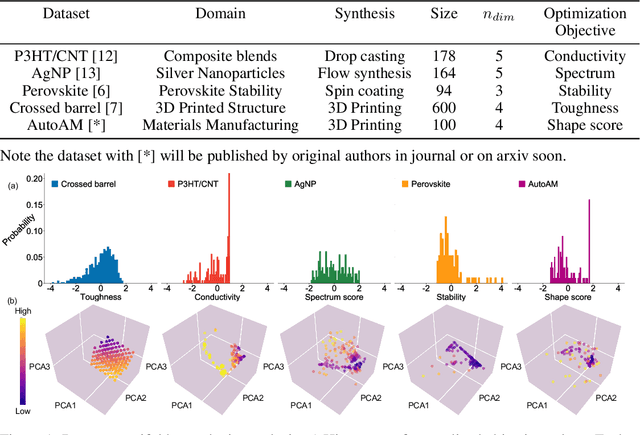
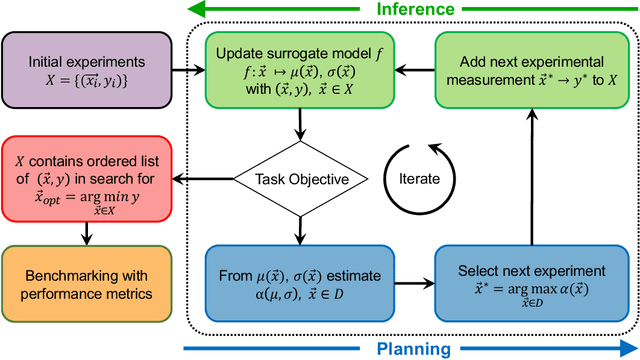
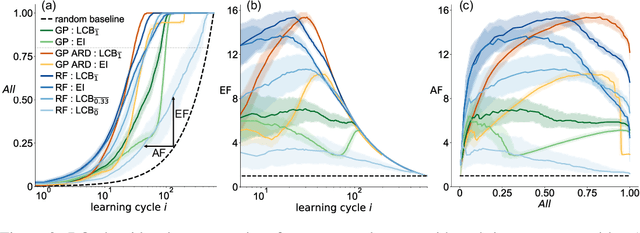
In the field of machine learning (ML) for materials optimization, active learning algorithms, such as Bayesian Optimization (BO), have been leveraged for guiding autonomous and high-throughput experimentation systems. However, very few studies have evaluated the efficiency of BO as a general optimization algorithm across a broad range of experimental materials science domains. In this work, we evaluate the performance of BO algorithms with a collection of surrogate model and acquisition function pairs across five diverse experimental materials systems, namely carbon nanotube polymer blends, silver nanoparticles, lead-halide perovskites, as well as additively manufactured polymer structures and shapes. By defining acceleration and enhancement metrics for general materials optimization objectives, we find that for surrogate model selection, Gaussian Process (GP) with anisotropic kernels (automatic relevance detection, ARD) and Random Forests (RF) have comparable performance and both outperform the commonly used GP without ARD. We discuss the implicit distributional assumptions of RF and GP, and the benefits of using GP with anisotropic kernels in detail. We provide practical insights for experimentalists on surrogate model selection of BO during materials optimization campaigns.