 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons in Reproducibility: Insights from NLP Studies in Materials Science
Jul 28, 2023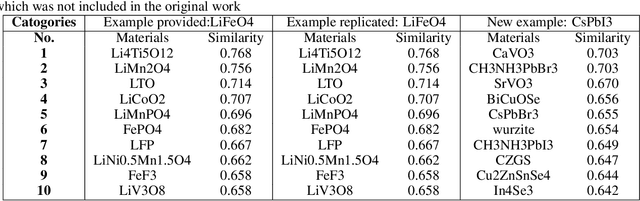
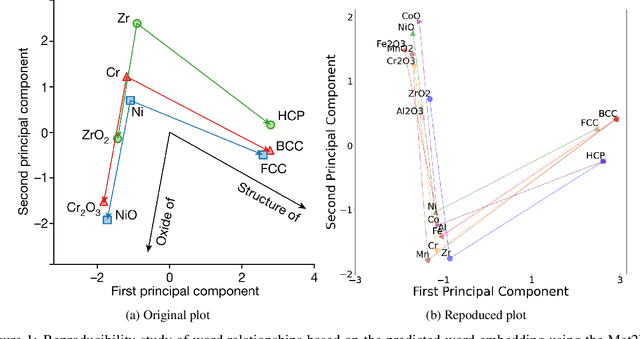
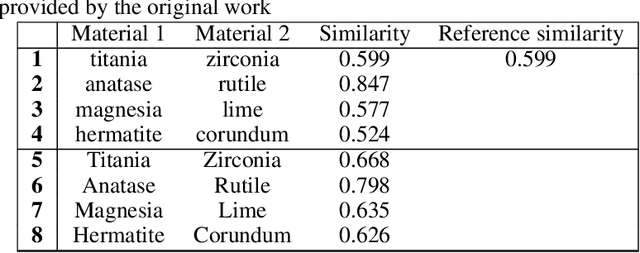

Natural Language Processing (NLP), a cornerstone field within artificial intelligence, has been increasingly utilized in the field of materials science literature. Our study conducts a reproducibility analysis of two pioneering works within this domain: "Machine-learned and codified synthesis parameters of oxide materials" by Kim et al., and "Unsupervised word embeddings capture latent knowledge from materials science literature" by Tshitoyan et al. We aim to comprehend these studies from a reproducibility perspective, acknowledging their significant influence on the field of materials informatics, rather than critiquing them. Our study indicates that both papers offered thorough workflows, tidy and well-documented codebases, and clear guidance for model evaluation. This makes it easier to replicate their results successfully and partially reproduce their findings. In doing so, they set commendable standards for future materials science publications to aspire to. However, our analysis also highlights areas for improvement such as to provide access to training data where copyright restrictions permit, more transparency on model architecture and the training process, and specifications of software dependency versions. We also cross-compare the word embedding models between papers, and find that some key differences in reproducibility and cross-compatibility are attributable to design choices outside the bounds of the models themselves. In summary, our study appreciates the benchmark set by these seminal papers while advocating for further enhancements in research reproducibility practices in the field of NLP for materials science. This balance of understanding and continuous improvement will ultimately propel the intersecting domains of NLP and materials science literature into a future of exciting discoveries.
Introducing flexible perovskites to the IoT world using photovoltaic-powered wireless tags
Jul 01, 2022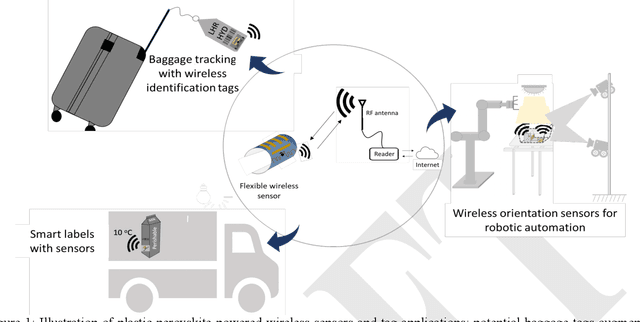
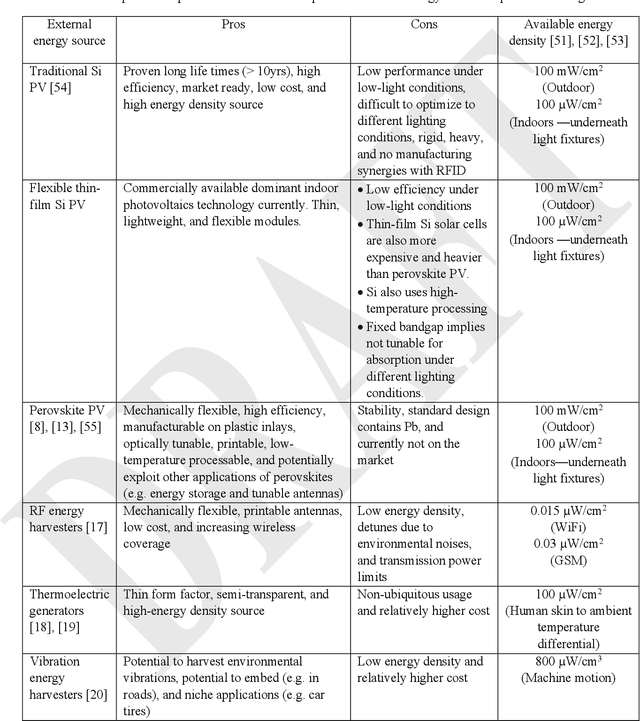
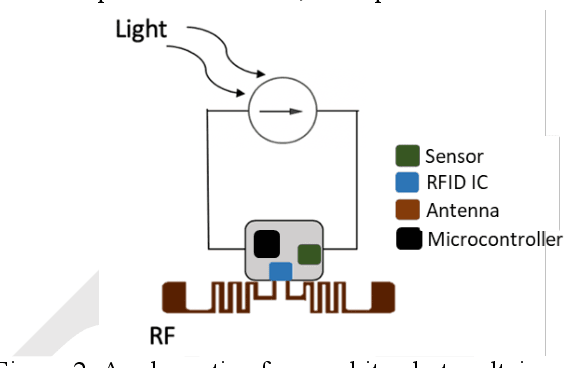
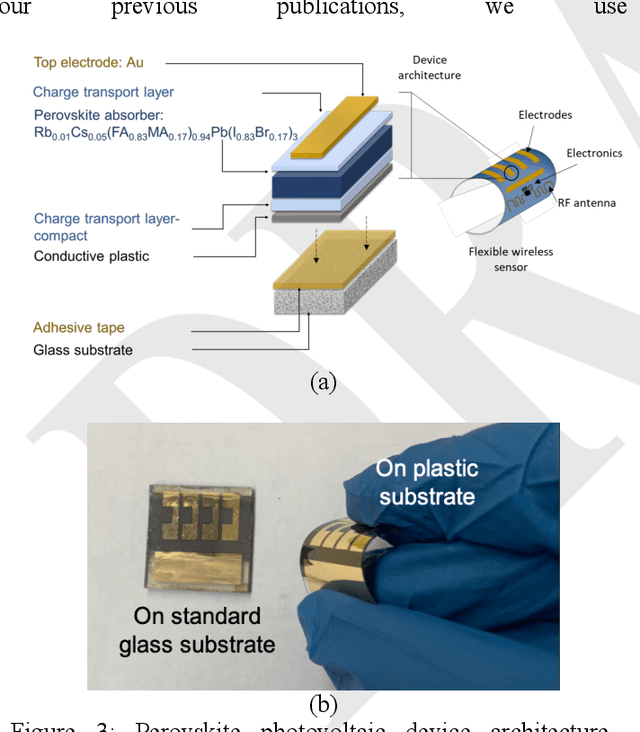
Billions of everyday objects could become part of the Internet of Things (IoT) by augmentation with low-cost, long-range, maintenance-free wireless sensors. Radio Frequency Identification (RFID) is a low-cost wireless technology that could enable this vision, but it is constrained by short communication range and lack of sufficient energy available to power auxiliary electronics and sensors. Here, we explore the use of flexible perovskite photovoltaic cells to provide external power to semi-passive RFID tags to increase range and energy availability for external electronics such as microcontrollers and digital sensors. Perovskites are intriguing materials that hold the possibility to develop high-performance, low-cost, optically tunable (to absorb different light spectra), and flexible light energy harvesters. Our prototype perovskite photovoltaic cells on plastic substrates have an efficiency of 13% and a voltage of 0.88 V at maximum power under standard testing conditions. We built prototypes of RFID sensors powered with these flexible photovoltaic cells to demonstrate real-world applications. Our evaluation of the prototypes suggests that: i) flexible PV cells are durable up to a bending radius of 5 mm with only a 20 % drop in relative efficiency; ii) RFID communication range increased by 5x, and meets the energy needs (10-350 microwatt) to enable self-powered wireless sensors; iii) perovskite powered wireless sensors enable many battery-less sensing applications (e.g., perishable good monitoring, warehouse automation)
Opportunities for Machine Learning to Accelerate Halide Perovskite Commercialization and Scale-Up
Oct 08, 2021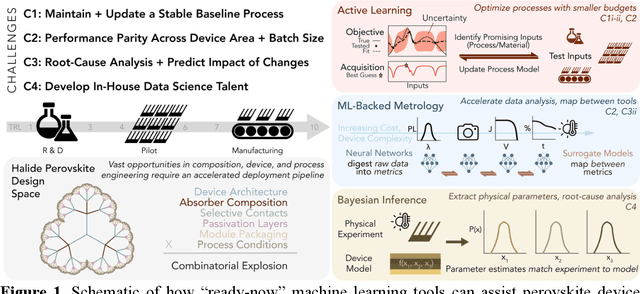
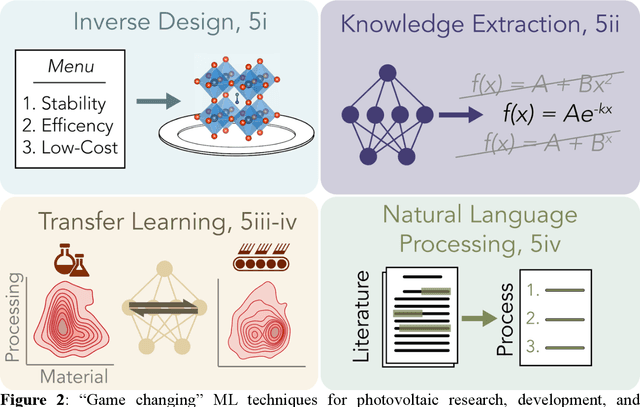
While halide perovskites attract significant academic attention, examples of at-scale industrial production are still sparse. In this perspective, we review practical challenges hindering the commercialization of halide perovskites, and discuss how machine-learning (ML) tools could help: (1) active-learning algorithms that blend institutional knowledge and human expertise could help stabilize and rapidly update baseline manufacturing processes; (2) ML-powered metrology, including computer imaging, could help narrow the performance gap between large- and small-area devices; and (3) inference methods could help accelerate root-cause analysis by reconciling multiple data streams and simulations, focusing research effort on areas with highest probability for improvement. We conclude that to satisfy many of these challenges, incremental -- not radical -- adaptations of existing ML and statistical methods are needed. We identify resources to help develop in-house data-science talent, and propose how industry-academic partnerships could help adapt "ready-now" ML tools to specific industry needs, further improve process control by revealing underlying mechanisms, and develop "gamechanger" discovery-oriented algorithms to better navigate vast materials combination spaces and the literature.
Benchmarking the Performance of Bayesian Optimization across Multiple Experimental Materials Science Domains
May 23, 2021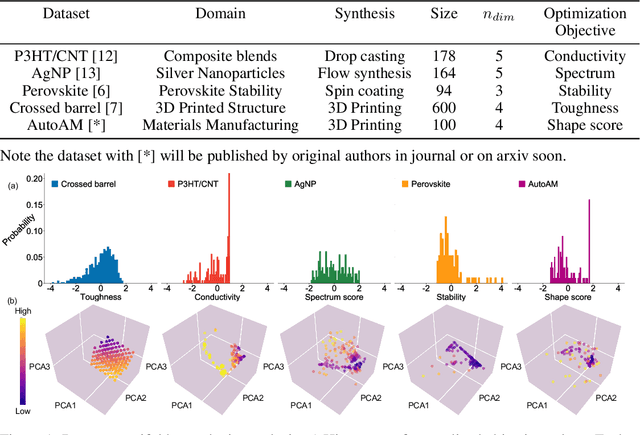
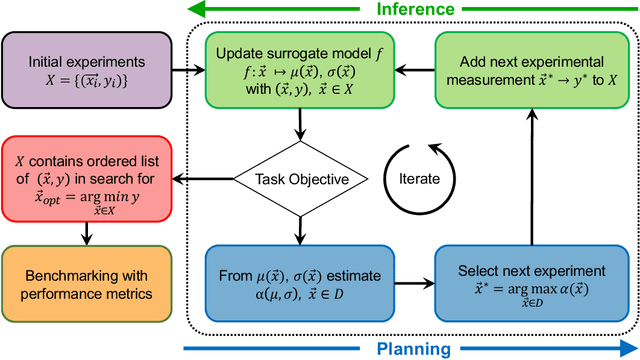
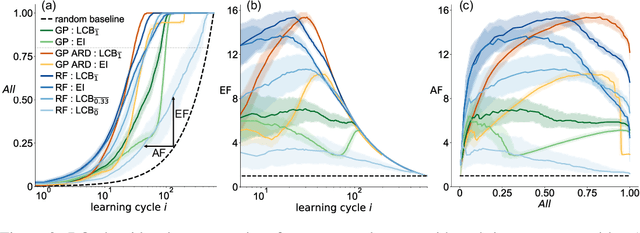
In the field of machine learning (ML) for materials optimization, active learning algorithms, such as Bayesian Optimization (BO), have been leveraged for guiding autonomous and high-throughput experimentation systems. However, very few studies have evaluated the efficiency of BO as a general optimization algorithm across a broad range of experimental materials science domains. In this work, we evaluate the performance of BO algorithms with a collection of surrogate model and acquisition function pairs across five diverse experimental materials systems, namely carbon nanotube polymer blends, silver nanoparticles, lead-halide perovskites, as well as additively manufactured polymer structures and shapes. By defining acceleration and enhancement metrics for general materials optimization objectives, we find that for surrogate model selection, Gaussian Process (GP) with anisotropic kernels (automatic relevance detection, ARD) and Random Forests (RF) have comparable performance and both outperform the commonly used GP without ARD. We discuss the implicit distributional assumptions of RF and GP, and the benefits of using GP with anisotropic kernels in detail. We provide practical insights for experimentalists on surrogate model selection of BO during materials optimization campaigns.
Fast classification of small X-ray diffraction datasets using data augmentation and deep neural networks
Nov 20, 2018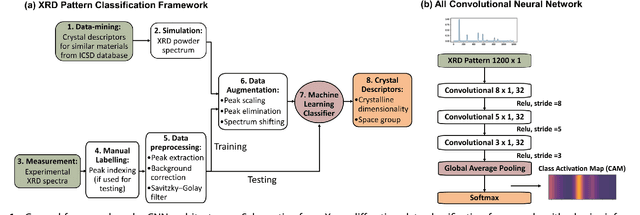
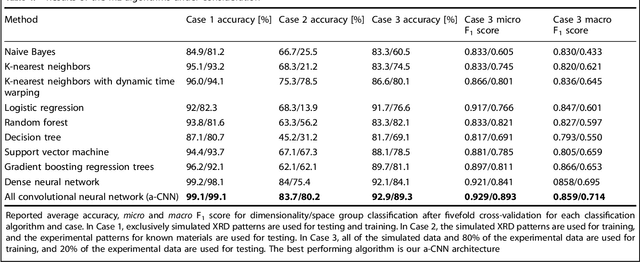
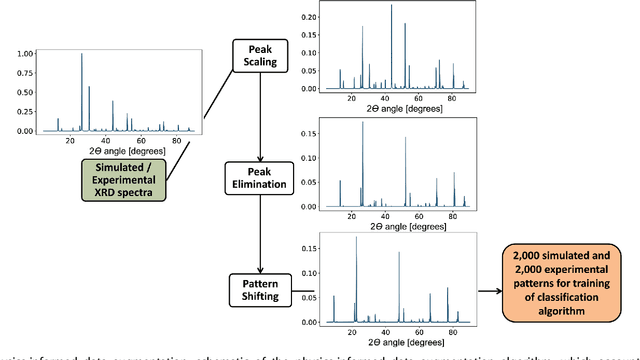
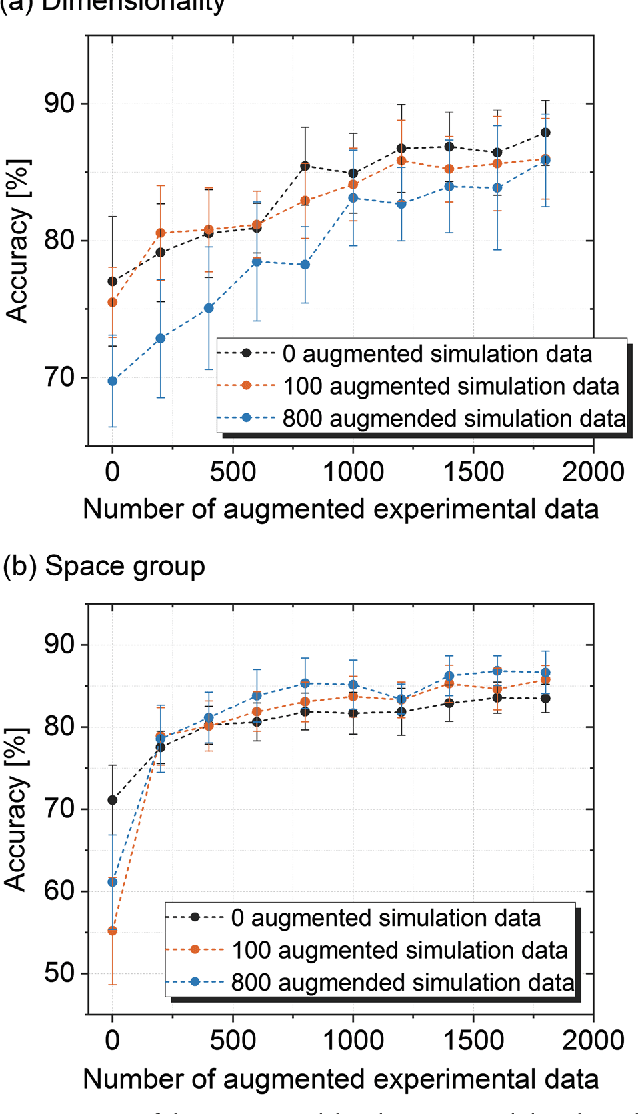
X-ray diffraction (XRD) for crystal structure characterization is among the most time-consuming and complex steps in the development cycle of novel materials. We propose a machine-learning-enabled approach to predict crystallographic dimensionality and space group from a limited number of experimental thin-film XRD patterns. We overcome the sparse-data problem intrinsic to novel materials development by coupling a supervised machine-learning approach with a physics-based data augmentation strategy . Using this approach, XRD spectrum acquisition and analysis occurs under 5.5 minutes, with accuracy comparable to human expert labeling. We simulate experimental powder diffraction patterns from crystallographic information contained in the Inorganic Crystal Structure Database (ICSD). We train a classification algorithm using a combination of labeled simulated and experimental augmented datasets, which account for thin-film characteristics and measurement noise. As a test case, 88 metal-halide thin films spanning 3 dimensionalities and 7 space-groups are synthesized and classified. The accuracies and throughputs of multiple machine-learning techniques are evaluated, along with the effect of augmented dataset size. The most accurate classification algorithm is found to be a feed-forward deep neural network. The calculated accuracies for dimensionality and space-group classification are comparable to ground-truth labelling by a human expert, approximately 90\% and 85\%, respectively. Additionally, we systematically evaluate the maximum XRD spectrum step size (data acquisition rate) before loss of predictive accuracy occurs, and determine it to be \ang{0.16} $2\theta $, which enables an XRD spectrum to be obtained and analyzed in 5 minutes or less.