 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Detection and Analysis of Handwriting on Seized Ivory: A Tool to Uncover Criminal Networks in the Illicit Wildlife Trade
Aug 13, 2025The transnational ivory trade continues to drive the decline of elephant populations across Africa, and trafficking networks remain difficult to disrupt. Tusks seized by law enforcement officials carry forensic information on the traffickers responsible for their export, including DNA evidence and handwritten markings made by traffickers. For 20 years, analyses of tusk DNA have identified where elephants were poached and established connections among shipments of ivory. While the links established using genetic evidence are extremely conclusive, genetic data is expensive and sometimes impossible to obtain. But though handwritten markings are easy to photograph, they are rarely documented or analyzed. Here, we present an AI-driven pipeline for extracting and analyzing handwritten markings on seized elephant tusks, offering a novel, scalable, and low-cost source of forensic evidence. Having collected 6,085 photographs from eight large seizures of ivory over a 6-year period (2014-2019), we used an object detection model to extract over 17,000 individual markings, which were then labeled and described using state-of-the-art AI tools. We identified 184 recurring "signature markings" that connect the tusks on which they appear. 20 signature markings were observed in multiple seizures, establishing forensic links between these seizures through traffickers involved in both shipments. This work complements other investigative techniques by filling in gaps where other data sources are unavailable. The study demonstrates the transformative potential of AI in wildlife forensics and highlights practical steps for integrating handwriting analysis into efforts to disrupt organized wildlife crime.
BankNote-Net: Open dataset for assistive universal currency recognition
Apr 07, 2022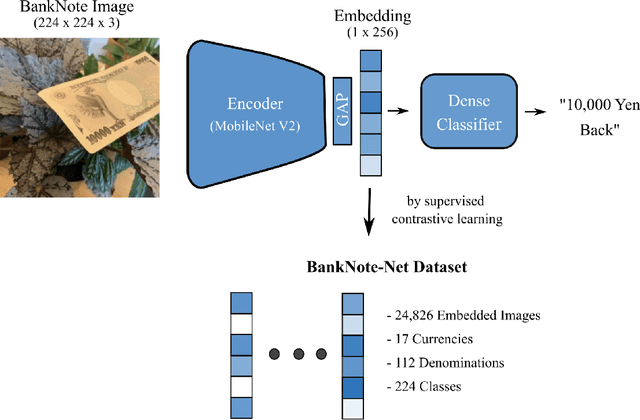

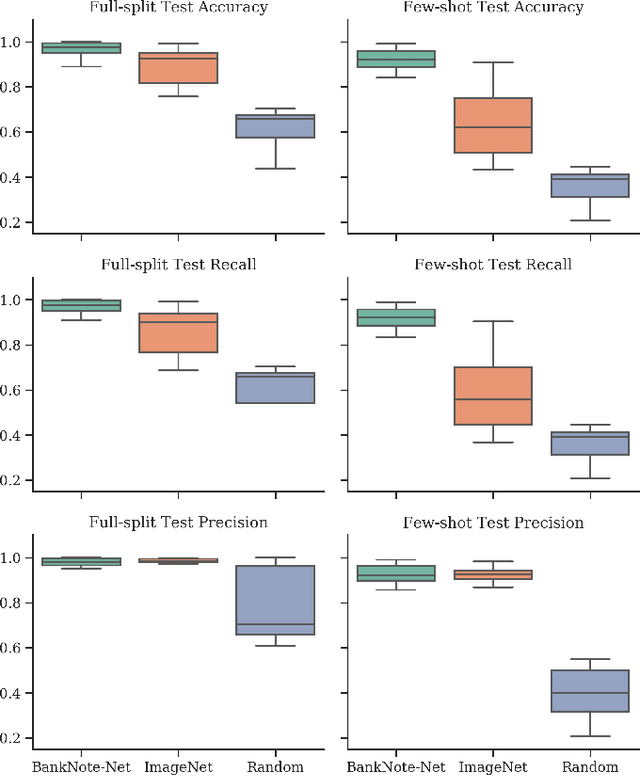
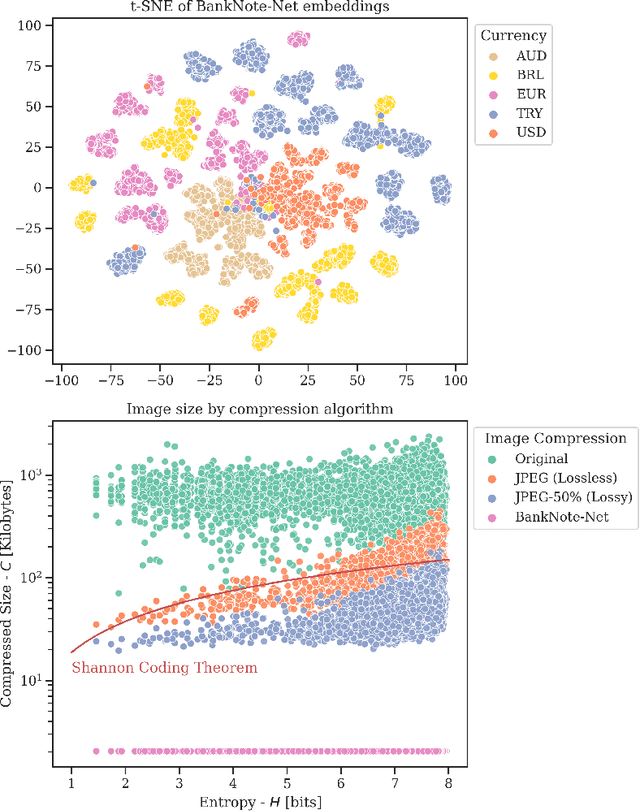
Millions of people around the world have low or no vision. Assistive software applications have been developed for a variety of day-to-day tasks, including optical character recognition, scene identification, person recognition, and currency recognition. This last task, the recognition of banknotes from different denominations, has been addressed by the use of computer vision models for image recognition. However, the datasets and models available for this task are limited, both in terms of dataset size and in variety of currencies covered. In this work, we collect a total of 24,826 images of banknotes in variety of assistive settings, spanning 17 currencies and 112 denominations. Using supervised contrastive learning, we develop a machine learning model for universal currency recognition. This model learns compliant embeddings of banknote images in a variety of contexts, which can be shared publicly (as a compressed vector representation), and can be used to train and test specialized downstream models for any currency, including those not covered by our dataset or for which only a few real images per denomination are available (few-shot learning). We deploy a variation of this model for public use in the last version of the Seeing AI app developed by Microsoft. We share our encoder model and the embeddings as an open dataset in our BankNote-Net repository.
An Artificial Intelligence Dataset for Solar Energy Locations in India
Jan 31, 2022


Rapid development of renewable energy sources, particularly solar photovoltaics, is critical to mitigate climate change. As a result, India has set ambitious goals to install 300 gigawatts of solar energy capacity by 2030. Given the large footprint projected to meet these renewable energy targets the potential for land use conflicts over environmental and social values is high. To expedite development of solar energy, land use planners will need access to up-to-date and accurate geo-spatial information of PV infrastructure. The majority of recent studies use either predictions of resource suitability or databases that are either developed thru crowdsourcing that often have significant sampling biases or have time lags between when projects are permitted and when location data becomes available. Here, we address this shortcoming by developing a spatially explicit machine learning model to map utility-scale solar projects across India. Using these outputs, we provide a cumulative measure of the solar footprint across India and quantified the degree of land modification associated with land cover types that may cause conflicts. Our analysis indicates that over 74\% of solar development In India was built on landcover types that have natural ecosystem preservation, and agricultural values. Thus, with a mean accuracy of 92\% this method permits the identification of the factors driving land suitability for solar projects and will be of widespread interest for studies seeking to assess trade-offs associated with the global decarbonization of green-energy systems. In the same way, our model increases the feasibility of remote sensing and long-term monitoring of renewable energy deployment targets.
Interpretable and Explainable Machine Learning for Materials Science and Chemistry
Nov 03, 2021
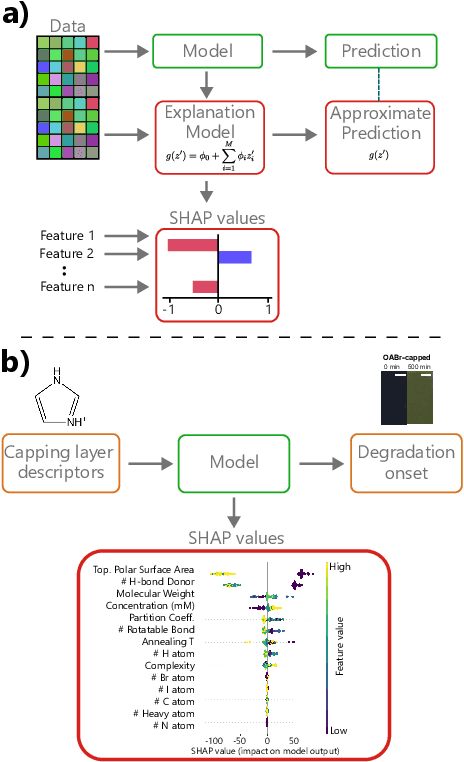
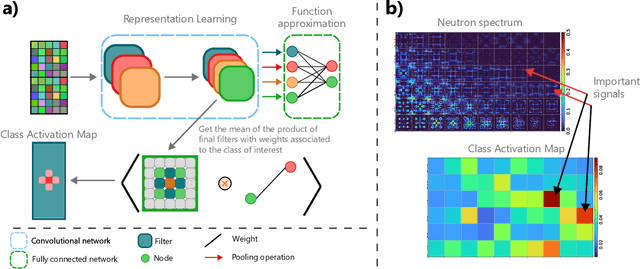
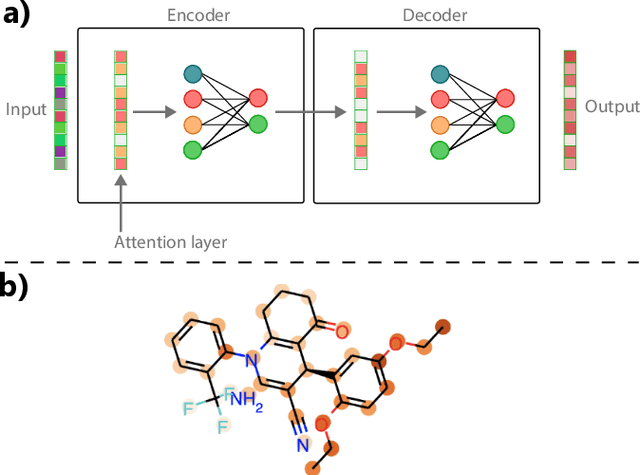
While the uptake of data-driven approaches for materials science and chemistry is at an exciting, early stage, to realise the true potential of machine learning models for successful scientific discovery, they must have qualities beyond purely predictive power. The predictions and inner workings of models should provide a certain degree of explainability by human experts, permitting the identification of potential model issues or limitations, building trust on model predictions and unveiling unexpected correlations that may lead to scientific insights. In this work, we summarize applications of interpretability and explainability techniques for materials science and chemistry and discuss how these techniques can improve the outcome of scientific studies. We discuss various challenges for interpretable machine learning in materials science and, more broadly, in scientific settings. In particular, we emphasize the risks of inferring causation or reaching generalization by purely interpreting machine learning models and the need of uncertainty estimates for model explanations. Finally, we showcase a number of exciting developments in other fields that could benefit interpretability in material science and chemistry problems.
Inverse design of crystals using generalized invertible crystallographic representation
May 15, 2020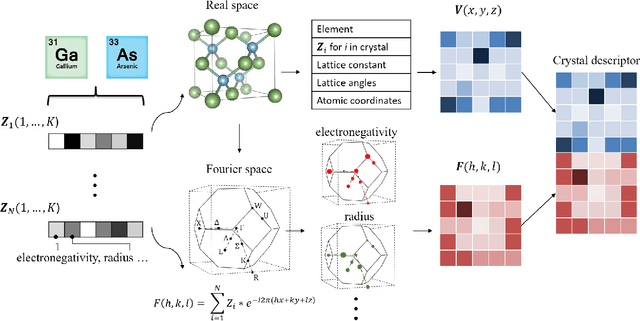
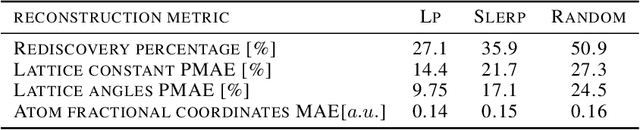
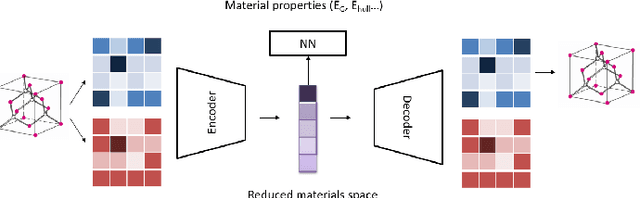
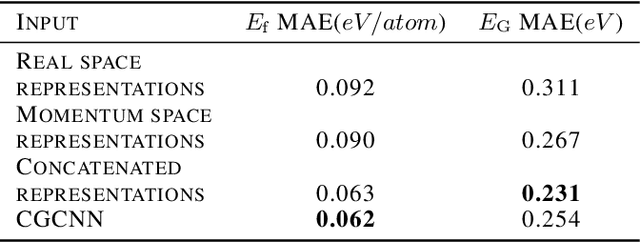
Deep learning has fostered many novel applications in materials informatics. However, the inverse design of inorganic crystals, $\textit{i.e.}$ generating new crystal structure with targeted properties, remains a grand challenge. An important ingredient for such generative models is an invertible representation that accesses the full periodic table. This is challenging due to limited data availability and the complexity of 3D periodic crystal structures. In this paper, we present a generalized invertible representation that encodes the crystallographic information into the descriptors in both real space and reciprocal space. Combining with a generative variational autoencoder (VAE), a wide range of crystallographic structures and chemistries with desired properties can be inverse-designed. We show that our VAE model predicts novel crystal structures that do not exist in the training and test database (Materials Project) with targeted formation energies and band gaps. We validate those predicted crystals by first-principles calculations. Finally, to design solids with practical applications, we address the sparse label problem by building a semi-supervised VAE and demonstrate its successful prediction of unique thermoelectric materials
Fast classification of small X-ray diffraction datasets using data augmentation and deep neural networks
Nov 20, 2018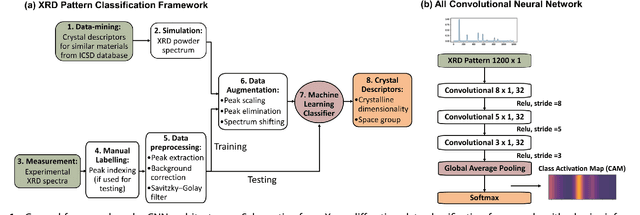
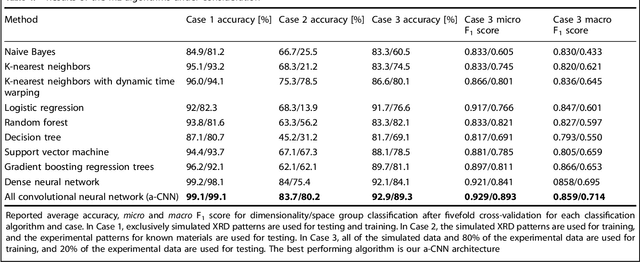
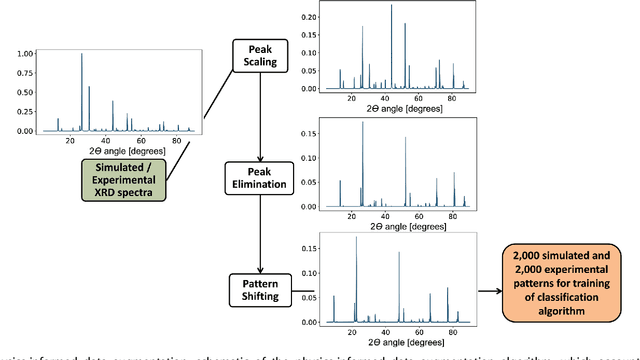
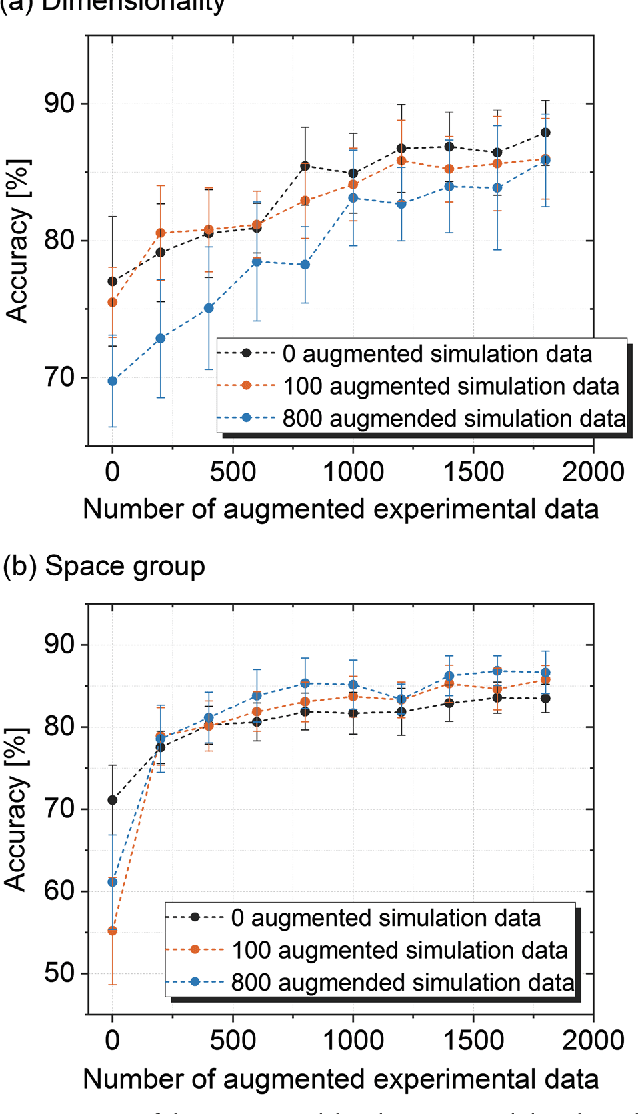
X-ray diffraction (XRD) for crystal structure characterization is among the most time-consuming and complex steps in the development cycle of novel materials. We propose a machine-learning-enabled approach to predict crystallographic dimensionality and space group from a limited number of experimental thin-film XRD patterns. We overcome the sparse-data problem intrinsic to novel materials development by coupling a supervised machine-learning approach with a physics-based data augmentation strategy . Using this approach, XRD spectrum acquisition and analysis occurs under 5.5 minutes, with accuracy comparable to human expert labeling. We simulate experimental powder diffraction patterns from crystallographic information contained in the Inorganic Crystal Structure Database (ICSD). We train a classification algorithm using a combination of labeled simulated and experimental augmented datasets, which account for thin-film characteristics and measurement noise. As a test case, 88 metal-halide thin films spanning 3 dimensionalities and 7 space-groups are synthesized and classified. The accuracies and throughputs of multiple machine-learning techniques are evaluated, along with the effect of augmented dataset size. The most accurate classification algorithm is found to be a feed-forward deep neural network. The calculated accuracies for dimensionality and space-group classification are comparable to ground-truth labelling by a human expert, approximately 90\% and 85\%, respectively. Additionally, we systematically evaluate the maximum XRD spectrum step size (data acquisition rate) before loss of predictive accuracy occurs, and determine it to be \ang{0.16} $2\theta $, which enables an XRD spectrum to be obtained and analyzed in 5 minutes or less.