 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDEx-CASK: Cauchy Mutation, Archive, and Stagnation Kick for RDEx-CSOP
May 10, 2026We extend RDEx-CSOP with 3 changes that target stagnation & late-stage variance, plus minor parameter tuning. The second scale factor in the standard branch is sampled independently from a truncated Cauchy. A small feasible-only JADE-style archive (|A|_max = 50) is added & sampled with probability |A|/(|A|+|P|). Per-individual stagnation counter triggers, after 180 no-improvement generations, three local overrides on standard branch: pull toward the global best, lift the archive sampling floor to 0.65, & saturate CR to 0.95 when population success rate is below 0.10. The exploitation biased branch & every other RDEx component are left untouched. On CEC CSOP suite (D=30, 25 runs), RDEx-CASK is competitive with RDEx, UDE-III, & CL-SRDE in feasibility-aware quality & improves time-to-target on most problems.
Aligning LLMs with Graph Neural Solvers for Combinatorial Optimization
Mar 28, 2026Recent research has demonstrated the effectiveness of large language models (LLMs) in solving combinatorial optimization problems (COPs) by representing tasks and instances in natural language. However, purely language-based approaches struggle to accurately capture complex relational structures inherent in many COPs, rendering them less effective at addressing medium-sized or larger instances. To address these limitations, we propose AlignOPT, a novel approach that aligns LLMs with graph neural solvers to learn a more generalizable neural COP heuristic. Specifically, AlignOPT leverages the semantic understanding capabilities of LLMs to encode textual descriptions of COPs and their instances, while concurrently exploiting graph neural solvers to explicitly model the underlying graph structures of COP instances. Our approach facilitates a robust integration and alignment between linguistic semantics and structural representations, enabling more accurate and scalable COP solutions. Experimental results demonstrate that AlignOPT achieves state-of-the-art results across diverse COPs, underscoring its effectiveness in aligning semantic and structural representations. In particular, AlignOPT demonstrates strong generalization, effectively extending to previously unseen COP instances.
DRAGON: LLM-Driven Decomposition and Reconstruction Agents for Large-Scale Combinatorial Optimization
Jan 10, 2026Large Language Models (LLMs) have recently shown promise in addressing combinatorial optimization problems (COPs) through prompt-based strategies. However, their scalability and generalization remain limited, and their effectiveness diminishes as problem size increases, particularly in routing problems involving more than 30 nodes. We propose DRAGON, which stands for Decomposition and Reconstruction Agents Guided OptimizatioN, a novel framework that combines the strengths of metaheuristic design and LLM reasoning. Starting from an initial global solution, DRAGON autonomously identifies regions with high optimization potential and strategically decompose large-scale COPs into manageable subproblems. Each subproblem is then reformulated as a concise, localized optimization task and solved through targeted LLM prompting guided by accumulated experiences. Finally, the locally optimized solutions are systematically reintegrated into the original global context to yield a significantly improved overall outcome. By continuously interacting with the optimization environment and leveraging an adaptive experience memory, the agents iteratively learn from feedback, effectively coupling symbolic reasoning with heuristic search. Empirical results show that, unlike existing LLM-based solvers limited to small-scale instances, DRAGON consistently produces feasible solutions on TSPLIB, CVRPLIB, and Weibull-5k bin packing benchmarks, and achieves near-optimal results (0.16% gap) on knapsack problems with over 3M variables. This work shows the potential of feedback-driven language agents as a new paradigm for generalizable and interpretable large-scale optimization.
Bridging Synthetic and Real Routing Problems via LLM-Guided Instance Generation and Progressive Adaptation
Nov 13, 2025Recent advances in Neural Combinatorial Optimization (NCO) methods have significantly improved the capability of neural solvers to handle synthetic routing instances. Nonetheless, existing neural solvers typically struggle to generalize effectively from synthetic, uniformly-distributed training data to real-world VRP scenarios, including widely recognized benchmark instances from TSPLib and CVRPLib. To bridge this generalization gap, we present Evolutionary Realistic Instance Synthesis (EvoReal), which leverages an evolutionary module guided by large language models (LLMs) to generate synthetic instances characterized by diverse and realistic structural patterns. Specifically, the evolutionary module produces synthetic instances whose structural attributes statistically mimics those observed in authentic real-world instances. Subsequently, pre-trained NCO models are progressively refined, firstly aligning them with these structurally enriched synthetic distributions and then further adapting them through direct fine-tuning on actual benchmark instances. Extensive experimental evaluations demonstrate that EvoReal markedly improves the generalization capabilities of state-of-the-art neural solvers, yielding a notable reduced performance gap compared to the optimal solutions on the TSPLib (1.05%) and CVRPLib (2.71%) benchmarks across a broad spectrum of problem scales.
Incremental Multistep Forecasting of Battery Degradation Using Pseudo Targets
Sep 19, 2025



Data-driven models accurately perform early battery prognosis to prevent equipment failure and further safety hazards. Most existing machine learning (ML) models work in offline mode which must consider their retraining post-deployment every time new data distribution is encountered. Hence, there is a need for an online ML approach where the model can adapt to varying distributions. However, existing online incremental multistep forecasts are a great challenge as there is no way to correct the model of its forecasts at the current instance. Also, these methods need to wait for a considerable amount of time to acquire enough streaming data before retraining. In this study, we propose iFSNet (incremental Fast and Slow learning Network) which is a modified version of FSNet for a single-pass mode (sample-by-sample) to achieve multistep forecasting using pseudo targets. It uses a simple linear regressor of the input sequence to extrapolate pseudo future samples (pseudo targets) and calculate the loss from the rest of the forecast and keep updating the model. The model benefits from the associative memory and adaptive structure mechanisms of FSNet, at the same time the model incrementally improves by using pseudo targets. The proposed model achieved 0.00197 RMSE and 0.00154 MAE on datasets with smooth degradation trajectories while it achieved 0.01588 RMSE and 0.01234 MAE on datasets having irregular degradation trajectories with capacity regeneration spikes.
Compound Fault Diagnosis for Train Transmission Systems Using Deep Learning with Fourier-enhanced Representation
Apr 09, 2025



Fault diagnosis prevents train disruptions by ensuring the stability and reliability of their transmission systems. Data-driven fault diagnosis models have several advantages over traditional methods in terms of dealing with non-linearity, adaptability, scalability, and automation. However, existing data-driven models are trained on separate transmission components and only consider single faults due to the limitations of existing datasets. These models will perform worse in scenarios where components operate with each other at the same time, affecting each component's vibration signals. To address some of these challenges, we propose a frequency domain representation and a 1-dimensional convolutional neural network for compound fault diagnosis and applied it on the PHM Beijing 2024 dataset, which includes 21 sensor channels, 17 single faults, and 42 compound faults from 4 interacting components, that is, motor, gearbox, left axle box, and right axle box. Our proposed model achieved 97.67% and 93.93% accuracies on the test set with 17 single faults and on the test set with 42 compound faults, respectively.
Continual learning with task specialist
Sep 26, 2024



Continual learning (CL) adapt the deep learning scenarios with timely updated datasets. However, existing CL models suffer from the catastrophic forgetting issue, where new knowledge replaces past learning. In this paper, we propose Continual Learning with Task Specialists (CLTS) to address the issues of catastrophic forgetting and limited labelled data in real-world datasets by performing class incremental learning of the incoming stream of data. The model consists of Task Specialists (T S) and Task Predictor (T P ) with pre-trained Stable Diffusion (SD) module. Here, we introduce a new specialist to handle a new task sequence and each T S has three blocks; i) a variational autoencoder (V AE) to learn the task distribution in a low dimensional latent space, ii) a K-Means block to perform data clustering and iii) Bootstrapping Language-Image Pre-training (BLIP ) model to generate a small batch of captions from the input data. These captions are fed as input to the pre-trained stable diffusion model (SD) for the generation of task samples. The proposed model does not store any task samples for replay, instead uses generated samples from SD to train the T P module. A comparison study with four SOTA models conducted on three real-world datasets shows that the proposed model outperforms all the selected baselines
XMOL: Explainable Multi-property Optimization of Molecules
Sep 12, 2024
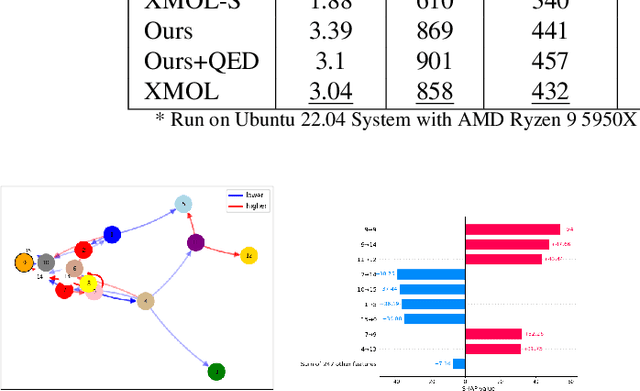
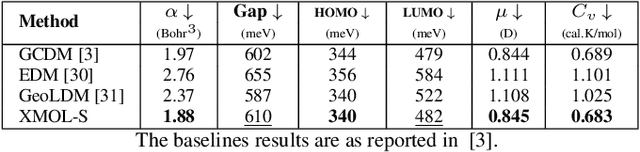
Molecular optimization is a key challenge in drug discovery and material science domain, involving the design of molecules with desired properties. Existing methods focus predominantly on single-property optimization, necessitating repetitive runs to target multiple properties, which is inefficient and computationally expensive. Moreover, these methods often lack transparency, making it difficult for researchers to understand and control the optimization process. To address these issues, we propose a novel framework, Explainable Multi-property Optimization of Molecules (XMOL), to optimize multiple molecular properties simultaneously while incorporating explainability. Our approach builds on state-of-the-art geometric diffusion models, extending them to multi-property optimization through the introduction of spectral normalization and enhanced molecular constraints for stabilized training. Additionally, we integrate interpretive and explainable techniques throughout the optimization process. We evaluated XMOL on the real-world molecular datasets i.e., QM9, demonstrating its effectiveness in both single property and multiple properties optimization while offering interpretable results, paving the way for more efficient and reliable molecular design.
U-TELL: Unsupervised Task Expert Lifelong Learning
May 23, 2024



Continual learning (CL) models are designed to learn new tasks arriving sequentially without re-training the network. However, real-world ML applications have very limited label information and these models suffer from catastrophic forgetting. To address these issues, we propose an unsupervised CL model with task experts called Unsupervised Task Expert Lifelong Learning (U-TELL) to continually learn the data arriving in a sequence addressing catastrophic forgetting. During training of U-TELL, we introduce a new expert on arrival of a new task. Our proposed architecture has task experts, a structured data generator and a task assigner. Each task expert is composed of 3 blocks; i) a variational autoencoder to capture the task distribution and perform data abstraction, ii) a k-means clustering module, and iii) a structure extractor to preserve latent task data signature. During testing, task assigner selects a suitable expert to perform clustering. U-TELL does not store or replay task samples, instead, we use generated structured samples to train the task assigner. We compared U-TELL with five SOTA unsupervised CL methods. U-TELL outperformed all baselines on seven benchmarks and one industry dataset for various CL scenarios with a training time over 6 times faster than the best performing baseline.
Cross-Problem Learning for Solving Vehicle Routing Problems
Apr 17, 2024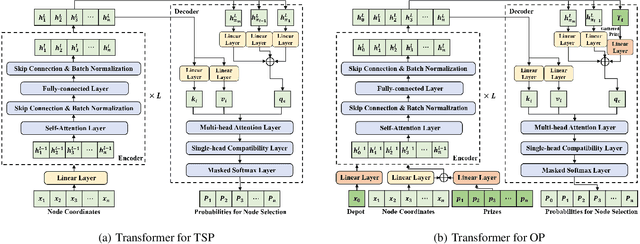

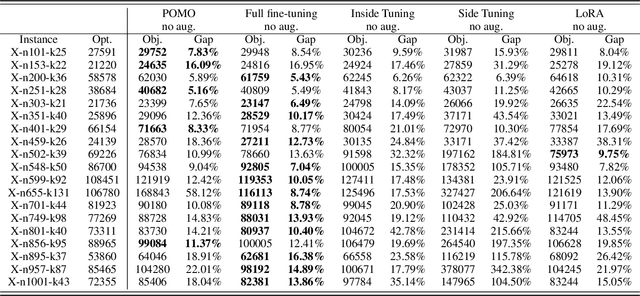

Existing neural heuristics often train a deep architecture from scratch for each specific vehicle routing problem (VRP), ignoring the transferable knowledge across different VRP variants. This paper proposes the cross-problem learning to assist heuristics training for different downstream VRP variants. Particularly, we modularize neural architectures for complex VRPs into 1) the backbone Transformer for tackling the travelling salesman problem (TSP), and 2) the additional lightweight modules for processing problem-specific features in complex VRPs. Accordingly, we propose to pre-train the backbone Transformer for TSP, and then apply it in the process of fine-tuning the Transformer models for each target VRP variant. On the one hand, we fully fine-tune the trained backbone Transformer and problem-specific modules simultaneously. On the other hand, we only fine-tune small adapter networks along with the modules, keeping the backbone Transformer still. Extensive experiments on typical VRPs substantiate that 1) the full fine-tuning achieves significantly better performance than the one trained from scratch, and 2) the adapter-based fine-tuning also delivers comparable performance while being notably parameter-efficient. Furthermore, we empirically demonstrate the favorable effect of our method in terms of cross-distribution application and versatility.