 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Optimized Vision-Language Models for Underground Infrastructure Assessment
Feb 03, 2026Autonomous inspection of underground infrastructure, such as sewer and culvert systems, is critical to public safety and urban sustainability. Although robotic platforms equipped with visual sensors can efficiently detect structural deficiencies, the automated generation of human-readable summaries from these detections remains a significant challenge, especially on resource-constrained edge devices. This paper presents a novel two-stage pipeline for end-to-end summarization of underground deficiencies, combining our lightweight RAPID-SCAN segmentation model with a fine-tuned Vision-Language Model (VLM) deployed on an edge computing platform. The first stage employs RAPID-SCAN (Resource-Aware Pipeline Inspection and Defect Segmentation using Compact Adaptive Network), achieving 0.834 F1-score with only 0.64M parameters for efficient defect segmentation. The second stage utilizes a fine-tuned Phi-3.5 VLM that generates concise, domain-specific summaries in natural language from the segmentation outputs. We introduce a curated dataset of inspection images with manually verified descriptions for VLM fine-tuning and evaluation. To enable real-time performance, we employ post-training quantization with hardware-specific optimization, achieving significant reductions in model size and inference latency without compromising summarization quality. We deploy and evaluate our complete pipeline on a mobile robotic platform, demonstrating its effectiveness in real-world inspection scenarios. Our results show the potential of edge-deployable integrated AI systems to bridge the gap between automated defect detection and actionable insights for infrastructure maintenance, paving the way for more scalable and autonomous inspection solutions.
KARMA: Efficient Structural Defect Segmentation via Kolmogorov-Arnold Representation Learning
Aug 11, 2025Semantic segmentation of structural defects in civil infrastructure remains challenging due to variable defect appearances, harsh imaging conditions, and significant class imbalance. Current deep learning methods, despite their effectiveness, typically require millions of parameters, rendering them impractical for real-time inspection systems. We introduce KARMA (Kolmogorov-Arnold Representation Mapping Architecture), a highly efficient semantic segmentation framework that models complex defect patterns through compositions of one-dimensional functions rather than conventional convolutions. KARMA features three technical innovations: (1) a parameter-efficient Tiny Kolmogorov-Arnold Network (TiKAN) module leveraging low-rank factorization for KAN-based feature transformation; (2) an optimized feature pyramid structure with separable convolutions for multi-scale defect analysis; and (3) a static-dynamic prototype mechanism that enhances feature representation for imbalanced classes. Extensive experiments on benchmark infrastructure inspection datasets demonstrate that KARMA achieves competitive or superior mean IoU performance compared to state-of-the-art approaches, while using significantly fewer parameters (0.959M vs. 31.04M, a 97% reduction). Operating at 0.264 GFLOPS, KARMA maintains inference speeds suitable for real-time deployment, enabling practical automated infrastructure inspection systems without compromising accuracy. The source code can be accessed at the following URL: https://github.com/faeyelab/karma.
Few-Shot Learning in Video and 3D Object Detection: A Survey
Jul 22, 2025Few-shot learning (FSL) enables object detection models to recognize novel classes given only a few annotated examples, thereby reducing expensive manual data labeling. This survey examines recent FSL advances for video and 3D object detection. For video, FSL is especially valuable since annotating objects across frames is more laborious than for static images. By propagating information across frames, techniques like tube proposals and temporal matching networks can detect new classes from a couple examples, efficiently leveraging spatiotemporal structure. FSL for 3D detection from LiDAR or depth data faces challenges like sparsity and lack of texture. Solutions integrate FSL with specialized point cloud networks and losses tailored for class imbalance. Few-shot 3D detection enables practical autonomous driving deployment by minimizing costly 3D annotation needs. Core issues in both domains include balancing generalization and overfitting, integrating prototype matching, and handling data modality properties. In summary, FSL shows promise for reducing annotation requirements and enabling real-world video, 3D, and other applications by efficiently leveraging information across feature, temporal, and data modalities. By comprehensively surveying recent advancements, this paper illuminates FSL's potential to minimize supervision needs and enable deployment across video, 3D, and other real-world applications.
KANICE: Kolmogorov-Arnold Networks with Interactive Convolutional Elements
Oct 22, 2024


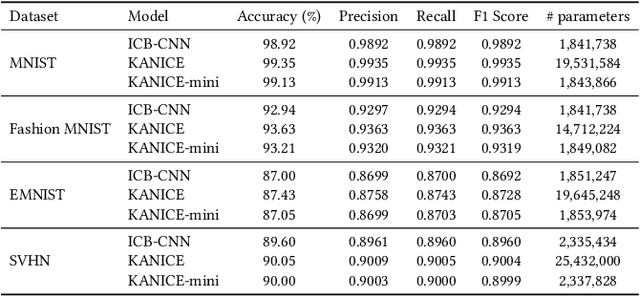
We introduce KANICE (Kolmogorov-Arnold Networks with Interactive Convolutional Elements), a novel neural architecture that combines Convolutional Neural Networks (CNNs) with Kolmogorov-Arnold Network (KAN) principles. KANICE integrates Interactive Convolutional Blocks (ICBs) and KAN linear layers into a CNN framework. This leverages KANs' universal approximation capabilities and ICBs' adaptive feature learning. KANICE captures complex, non-linear data relationships while enabling dynamic, context-dependent feature extraction based on the Kolmogorov-Arnold representation theorem. We evaluated KANICE on four datasets: MNIST, Fashion-MNIST, EMNIST, and SVHN, comparing it against standard CNNs, CNN-KAN hybrids, and ICB variants. KANICE consistently outperformed baseline models, achieving 99.35% accuracy on MNIST and 90.05% on the SVHN dataset. Furthermore, we introduce KANICE-mini, a compact variant designed for efficiency. A comprehensive ablation study demonstrates that KANICE-mini achieves comparable performance to KANICE with significantly fewer parameters. KANICE-mini reached 90.00% accuracy on SVHN with 2,337,828 parameters, compared to KANICE's 25,432,000. This study highlights the potential of KAN-based architectures in balancing performance and computational efficiency in image classification tasks. Our work contributes to research in adaptive neural networks, integrates mathematical theorems into deep learning architectures, and explores the trade-offs between model complexity and performance, advancing computer vision and pattern recognition. The source code for this paper is publicly accessible through our GitHub repository (https://github.com/m-ferdaus/kanice).
DRACO-DehazeNet: An Efficient Image Dehazing Network Combining Detail Recovery and a Novel Contrastive Learning Paradigm
Oct 18, 2024



Image dehazing is crucial for clarifying images obscured by haze or fog, but current learning-based approaches is dependent on large volumes of training data and hence consumed significant computational power. Additionally, their performance is often inadequate under non-uniform or heavy haze. To address these challenges, we developed the Detail Recovery And Contrastive DehazeNet, which facilitates efficient and effective dehazing via a dense dilated inverted residual block and an attention-based detail recovery network that tailors enhancements to specific dehazed scene contexts. A major innovation is its ability to train effectively with limited data, achieved through a novel quadruplet loss-based contrastive dehazing paradigm. This approach distinctly separates hazy and clear image features while also distinguish lower-quality and higher-quality dehazed images obtained from each sub-modules of our network, thereby refining the dehazing process to a larger extent. Extensive tests on a variety of benchmarked haze datasets demonstrated the superiority of our approach. The code repository for this work will be available soon.
Imbalance-Aware Culvert-Sewer Defect Segmentation Using an Enhanced Feature Pyramid Network
Aug 19, 2024



Imbalanced datasets are a significant challenge in real-world scenarios. They lead to models that underperform on underrepresented classes, which is a critical issue in infrastructure inspection. This paper introduces the Enhanced Feature Pyramid Network (E-FPN), a deep learning model for the semantic segmentation of culverts and sewer pipes within imbalanced datasets. The E-FPN incorporates architectural innovations like sparsely connected blocks and depth-wise separable convolutions to improve feature extraction and handle object variations. To address dataset imbalance, the model employs strategies like class decomposition and data augmentation. Experimental results on the culvert-sewer defects dataset and a benchmark aerial semantic segmentation drone dataset show that the E-FPN outperforms state-of-the-art methods, achieving an average Intersection over Union (IoU) improvement of 13.8% and 27.2%, respectively. Additionally, class decomposition and data augmentation together boost the model's performance by approximately 6.9% IoU. The proposed E-FPN presents a promising solution for enhancing object segmentation in challenging, multi-class real-world datasets, with potential applications extending beyond culvert-sewer defect detection.
SHARP-Net: A Refined Pyramid Network for Deficiency Segmentation in Culverts and Sewer Pipes
Aug 02, 2024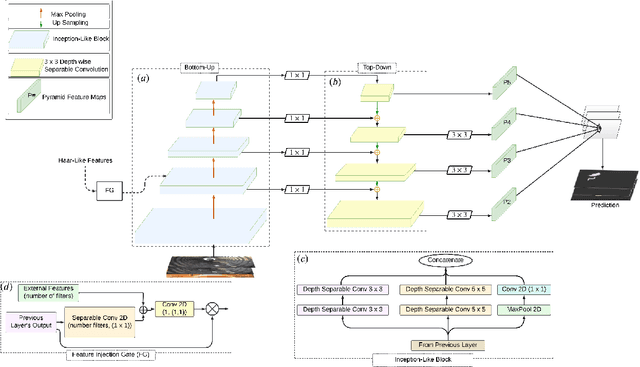
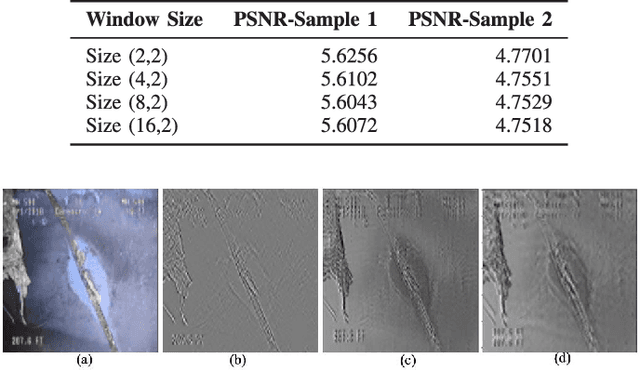
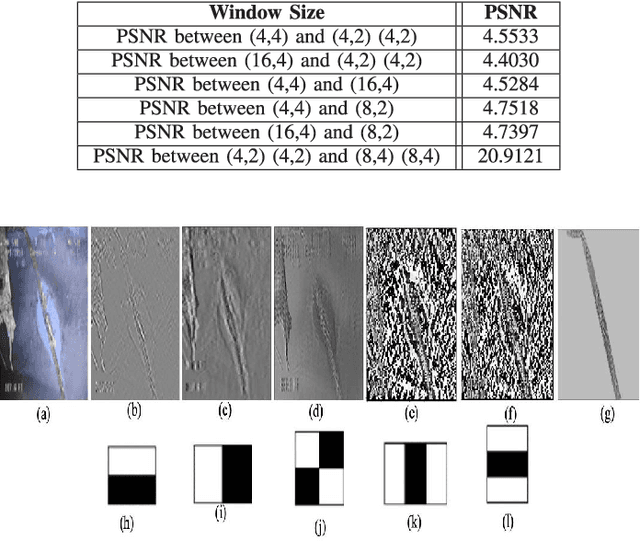
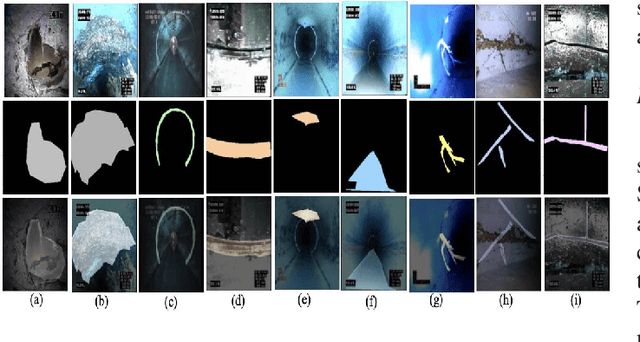
This paper introduces Semantic Haar-Adaptive Refined Pyramid Network (SHARP-Net), a novel architecture for semantic segmentation. SHARP-Net integrates a bottom-up pathway featuring Inception-like blocks with varying filter sizes (3x3$ and 5x5), parallel max-pooling, and additional spatial detection layers. This design captures multi-scale features and fine structural details. Throughout the network, depth-wise separable convolutions are used to reduce complexity. The top-down pathway of SHARP-Net focuses on generating high-resolution features through upsampling and information fusion using $1\times1$ and $3\times3$ depth-wise separable convolutions. We evaluated our model using our developed challenging Culvert-Sewer Defects dataset and the benchmark DeepGlobe Land Cover dataset. Our experimental evaluation demonstrated the base model's (excluding Haar-like features) effectiveness in handling irregular defect shapes, occlusions, and class imbalances. It outperformed state-of-the-art methods, including U-Net, CBAM U-Net, ASCU-Net, FPN, and SegFormer, achieving average improvements of 14.4% and 12.1% on the Culvert-Sewer Defects and DeepGlobe Land Cover datasets, respectively, with IoU scores of 77.2% and 70.6%. Additionally, the training time was reduced. Furthermore, the integration of carefully selected and fine-tuned Haar-like features enhanced the performance of deep learning models by at least 20%. The proposed SHARP-Net, incorporating Haar-like features, achieved an impressive IoU of 94.75%, representing a 22.74% improvement over the base model. These features were also applied to other deep learning models, showing a 35.0% improvement, proving their versatility and effectiveness. SHARP-Net thus provides a powerful and efficient solution for accurate semantic segmentation in challenging real-world scenarios.
Dehazing Remote Sensing and UAV Imagery: A Review of Deep Learning, Prior-based, and Hybrid Approaches
May 13, 2024High-quality images are crucial in remote sensing and UAV applications, but atmospheric haze can severely degrade image quality, making image dehazing a critical research area. Since the introduction of deep convolutional neural networks, numerous approaches have been proposed, and even more have emerged with the development of vision transformers and contrastive/few-shot learning. Simultaneously, papers describing dehazing architectures applicable to various Remote Sensing (RS) domains are also being published. This review goes beyond the traditional focus on benchmarked haze datasets, as we also explore the application of dehazing techniques to remote sensing and UAV datasets, providing a comprehensive overview of both deep learning and prior-based approaches in these domains. We identify key challenges, including the lack of large-scale RS datasets and the need for more robust evaluation metrics, and outline potential solutions and future research directions to address them. This review is the first, to our knowledge, to provide comprehensive discussions on both existing and very recent dehazing approaches (as of 2024) on benchmarked and RS datasets, including UAV-based imagery.
Dual Attention U-Net with Feature Infusion: Pushing the Boundaries of Multiclass Defect Segmentation
Dec 21, 2023The proposed architecture, Dual Attentive U-Net with Feature Infusion (DAU-FI Net), addresses challenges in semantic segmentation, particularly on multiclass imbalanced datasets with limited samples. DAU-FI Net integrates multiscale spatial-channel attention mechanisms and feature injection to enhance precision in object localization. The core employs a multiscale depth-separable convolution block, capturing localized patterns across scales. This block is complemented by a spatial-channel squeeze and excitation (scSE) attention unit, modeling inter-dependencies between channels and spatial regions in feature maps. Additionally, additive attention gates refine segmentation by connecting encoder-decoder pathways. To augment the model, engineered features using Gabor filters for textural analysis, Sobel and Canny filters for edge detection are injected guided by semantic masks to expand the feature space strategically. Comprehensive experiments on a challenging sewer pipe and culvert defect dataset and a benchmark dataset validate DAU-FI Net's capabilities. Ablation studies highlight incremental benefits from attention blocks and feature injection. DAU-FI Net achieves state-of-the-art mean Intersection over Union (IoU) of 95.6% and 98.8% on the defect test set and benchmark respectively, surpassing prior methods by 8.9% and 12.6%, respectively. Ablation studies highlight incremental benefits from attention blocks and feature injection. The proposed architecture provides a robust solution, advancing semantic segmentation for multiclass problems with limited training data. Our sewer-culvert defects dataset, featuring pixel-level annotations, opens avenues for further research in this crucial domain. Overall, this work delivers key innovations in architecture, attention, and feature engineering to elevate semantic segmentation efficacy.
Unlocking the capabilities of explainable fewshot learning in remote sensing
Oct 12, 2023Recent advancements have significantly improved the efficiency and effectiveness of deep learning methods for imagebased remote sensing tasks. However, the requirement for large amounts of labeled data can limit the applicability of deep neural networks to existing remote sensing datasets. To overcome this challenge, fewshot learning has emerged as a valuable approach for enabling learning with limited data. While previous research has evaluated the effectiveness of fewshot learning methods on satellite based datasets, little attention has been paid to exploring the applications of these methods to datasets obtained from UAVs, which are increasingly used in remote sensing studies. In this review, we provide an up to date overview of both existing and newly proposed fewshot classification techniques, along with appropriate datasets that are used for both satellite based and UAV based data. Our systematic approach demonstrates that fewshot learning can effectively adapt to the broader and more diverse perspectives that UAVbased platforms can provide. We also evaluate some SOTA fewshot approaches on a UAV disaster scene classification dataset, yielding promising results. We emphasize the importance of integrating XAI techniques like attention maps and prototype analysis to increase the transparency, accountability, and trustworthiness of fewshot models for remote sensing. Key challenges and future research directions are identified, including tailored fewshot methods for UAVs, extending to unseen tasks like segmentation, and developing optimized XAI techniques suited for fewshot remote sensing problems. This review aims to provide researchers and practitioners with an improved understanding of fewshot learnings capabilities and limitations in remote sensing, while highlighting open problems to guide future progress in efficient, reliable, and interpretable fewshot methods.