 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Response-Field Inertia Operator for HEC-RAS 2D Water-Surface Elevation Prediction
Jun 04, 2026This article presents a cross-dataset evaluation of learned native-cell surrogate models for solver-consistent water-surface elevation (WSE) prediction in HEC-RAS 2D. To avoid raster remapping error and information-access confounding, surrogates are evaluated directly on the original nonuniform computational cells under an explicit policy that separates static project inputs, current hydraulic state, project-input forcing, calibration-derived quantities, and future solver-output targets. We introduce the Learned Response-Field Inertia Operator (LRFIO), a no-forcing, increment-based learned surrogate that calibrates an inertial response operator from solved HEC-RAS trajectories and deploys the retained operator through closed-form native-cell rollout. LRFIO evaluates a base-case-first response hierarchy consisting of persistence, global calibrated inertia, and segmented response-field inertia. Segmentation, residual correction, and neuralized inertia are treated as learnable modeling choices, with added complexity retained only when validation evidence justifies its cost. Evaluated across four diverse HEC-RAS 2D benchmarks, LRFIO retains different response structures for different domains, demonstrating adaptive learned complexity. The selector audit shows controlled complexity with a maximum validation regret of 4.30%. During deployment, retained rollout times range from 0.003 s to 0.242 s, and the Beaver Bayou measured-solve comparison gives an estimated 2.75 x 10^4 horizon-normalized speedup over HEC-RAS. These results indicate that the current native-cell increment is a strong solver-conditioned predictive scaffold and that added response-field, neural, or spatial complexity should be retained only when empirically justified.
DeltaSeg: Tiered Attention and Deep Delta Learning for Multi-Class Structural Defect Segmentation
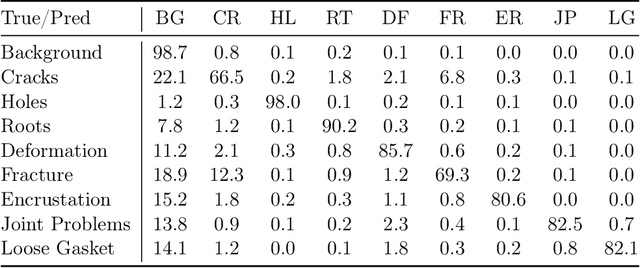
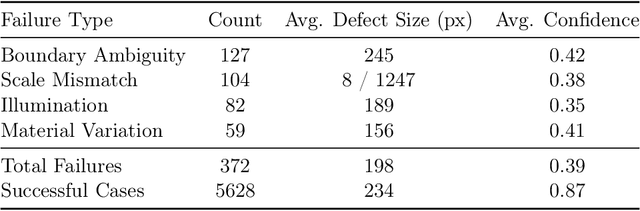
Apr 20, 2026Automated segmentation of structural defects from visual inspection imagery remains challenging due to the diversity of damage types, extreme class imbalance, and the need for precise boundary delineation. This paper presents DeltaSeg, a U-shaped encoder-decoder architecture with a tiered attention strategy that integrates Squeeze-and-Excitation (SE) channel attention in the encoder, Coordinate Attention at the bottleneck and decoder, and a novel Deep Delta Attention (DDA) mechanism in the skip connections. The encoder uses depthwise separable convolutions with dilated stages to maintain spatial resolution while expanding the receptive field. Atrous Spatial Pyramid Pooling (ASPP) at the bottleneck captures multi-scale context. The DDA module refines skip connections through a dual-path scheme combining a learned delta operator for nuisance feature suppression with spatial attention gates conditioned on decoder signals. Deep supervision through multi-scale auxiliary heads further strengthens gradient flow and encourages semantically meaningful features at intermediate decoder stages. We evaluate DeltaSeg on two datasets: the S2DS dataset (7 classes) and the Culvert-Sewer Defect Dataset (CSDD, 9 classes). Across both benchmarks, DeltaSeg consistently outperforms 12 competing architectures including U-Net, SA-UNet, UNet3+, SegFormer, Swin-UNet, EGE-UNet, FPN, and Mobile-UNETR, demonstrating strong generalization across damage types, imaging conditions, and structural geometries.
EfficientPENet: Real-Time Depth Completion from Sparse LiDAR via Lightweight Multi-Modal Fusion
Apr 20, 2026Depth completion from sparse LiDAR measurements and corresponding RGB images is a prerequisite for accurate 3D perception in robotic systems. Existing methods achieve high accuracy on standard benchmarks but rely on heavy backbone architectures that preclude real-time deployment on embedded hardware. We present EfficientPENet, a two-branch depth completion network that replaces the conventional ResNet encoder with a modernized ConvNeXt backbone, introduces sparsity-invariant convolutions for the depth stream, and refines predictions through a Convolutional Spatial Propagation Network (CSPN). The RGB branch leverages ImageNet-pretrained ConvNeXt blocks with Layer Normalization, 7x7 depthwise convolutions, and stochastic depth regularization. Features from both branches are merged via late fusion and decoded through a multi-scale deep supervision strategy. We further introduce a position-aware test-time augmentation scheme that corrects coordinate tensors during horizontal flipping, yielding consistent error reduction at inference. On the KITTI depth completion benchmark, EfficientPENet achieves an RMSE of 631.94 mm with 36.24M parameters and a latency of 20.51 ms, operating at 48.76 FPS. This represents a 3.7 times reduction in parameters and a 23 times speedup relative to BP-Net, while maintaining competitive accuracy. These results establish EfficientPENet as a practical solution for real-time depth completion on resource-constrained edge platforms such as the NVIDIA Jetson.
VeloxNet: Efficient Spatial Gating for Lightweight Embedded Image Classification
Mar 19, 2026Deploying deep learning models on embedded devices for tasks such as aerial disaster monitoring and infrastructure inspection requires architectures that balance accuracy with strict constraints on model size, memory, and latency. This paper introduces VeloxNet, a lightweight CNN architecture that replaces SqueezeNet's fire modules with gated multi-layer perceptron (gMLP) blocks for embedded image classification. Each gMLP block uses a spatial gating unit (SGU) that applies learned spatial projections and multiplicative gating, enabling the network to capture spatial dependencies across the full feature map in a single layer. Unlike fire modules, which are limited to local receptive fields defined by small convolutional kernels, the SGU provides global spatial modeling at each layer with fewer parameters. We evaluate VeloxNet on three aerial image datasets: the Aerial Image Database for Emergency Response (AIDER), the Comprehensive Disaster Dataset (CDD), and the Levee Defect Dataset (LDD), comparing against eleven baselines including MobileNet variants, ShuffleNet, EfficientNet, and recent vision transformers. VeloxNet reduces the parameter count by 46.1% relative to SqueezeNet (from 740,970 to 399,366) while improving weighted F1 scores by 6.32% on AIDER, 30.83% on CDD, and 2.51% on LDD. These results demonstrate that substituting local convolutional modules with spatial gating blocks can improve both classification accuracy and parameter efficiency for resource-constrained deployment. The source code will be made publicly available upon acceptance of the paper.
Edge-Optimized Vision-Language Models for Underground Infrastructure Assessment
Feb 03, 2026Autonomous inspection of underground infrastructure, such as sewer and culvert systems, is critical to public safety and urban sustainability. Although robotic platforms equipped with visual sensors can efficiently detect structural deficiencies, the automated generation of human-readable summaries from these detections remains a significant challenge, especially on resource-constrained edge devices. This paper presents a novel two-stage pipeline for end-to-end summarization of underground deficiencies, combining our lightweight RAPID-SCAN segmentation model with a fine-tuned Vision-Language Model (VLM) deployed on an edge computing platform. The first stage employs RAPID-SCAN (Resource-Aware Pipeline Inspection and Defect Segmentation using Compact Adaptive Network), achieving 0.834 F1-score with only 0.64M parameters for efficient defect segmentation. The second stage utilizes a fine-tuned Phi-3.5 VLM that generates concise, domain-specific summaries in natural language from the segmentation outputs. We introduce a curated dataset of inspection images with manually verified descriptions for VLM fine-tuning and evaluation. To enable real-time performance, we employ post-training quantization with hardware-specific optimization, achieving significant reductions in model size and inference latency without compromising summarization quality. We deploy and evaluate our complete pipeline on a mobile robotic platform, demonstrating its effectiveness in real-world inspection scenarios. Our results show the potential of edge-deployable integrated AI systems to bridge the gap between automated defect detection and actionable insights for infrastructure maintenance, paving the way for more scalable and autonomous inspection solutions.
A Knowledge-Graph Translation Layer for Mission-Aware Multi-Agent Path Planning in Spatiotemporal Dynamics
Oct 24, 2025The coordination of autonomous agents in dynamic environments is hampered by the semantic gap between high-level mission objectives and low-level planner inputs. To address this, we introduce a framework centered on a Knowledge Graph (KG) that functions as an intelligent translation layer. The KG's two-plane architecture compiles declarative facts into per-agent, mission-aware ``worldviews" and physics-aware traversal rules, decoupling mission semantics from a domain-agnostic planner. This allows complex, coordinated paths to be modified simply by changing facts in the KG. A case study involving Autonomous Underwater Vehicles (AUVs) in the Gulf of Mexico visually demonstrates the end-to-end process and quantitatively proves that different declarative policies produce distinct, high-performing outcomes. This work establishes the KG not merely as a data repository, but as a powerful, stateful orchestrator for creating adaptive and explainable autonomous systems.
KARMA: Efficient Structural Defect Segmentation via Kolmogorov-Arnold Representation Learning
Aug 11, 2025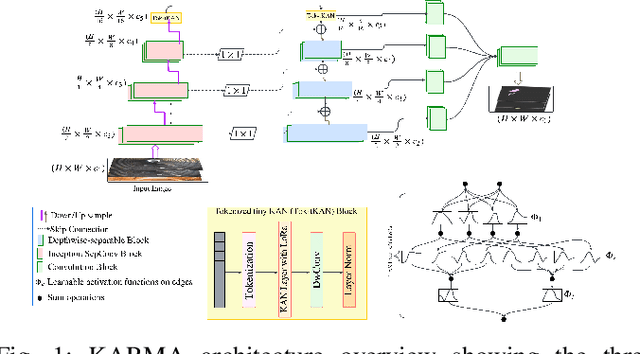

Semantic segmentation of structural defects in civil infrastructure remains challenging due to variable defect appearances, harsh imaging conditions, and significant class imbalance. Current deep learning methods, despite their effectiveness, typically require millions of parameters, rendering them impractical for real-time inspection systems. We introduce KARMA (Kolmogorov-Arnold Representation Mapping Architecture), a highly efficient semantic segmentation framework that models complex defect patterns through compositions of one-dimensional functions rather than conventional convolutions. KARMA features three technical innovations: (1) a parameter-efficient Tiny Kolmogorov-Arnold Network (TiKAN) module leveraging low-rank factorization for KAN-based feature transformation; (2) an optimized feature pyramid structure with separable convolutions for multi-scale defect analysis; and (3) a static-dynamic prototype mechanism that enhances feature representation for imbalanced classes. Extensive experiments on benchmark infrastructure inspection datasets demonstrate that KARMA achieves competitive or superior mean IoU performance compared to state-of-the-art approaches, while using significantly fewer parameters (0.959M vs. 31.04M, a 97% reduction). Operating at 0.264 GFLOPS, KARMA maintains inference speeds suitable for real-time deployment, enabling practical automated infrastructure inspection systems without compromising accuracy. The source code can be accessed at the following URL: https://github.com/faeyelab/karma.
Few-Shot Learning in Video and 3D Object Detection: A Survey
Jul 22, 2025Few-shot learning (FSL) enables object detection models to recognize novel classes given only a few annotated examples, thereby reducing expensive manual data labeling. This survey examines recent FSL advances for video and 3D object detection. For video, FSL is especially valuable since annotating objects across frames is more laborious than for static images. By propagating information across frames, techniques like tube proposals and temporal matching networks can detect new classes from a couple examples, efficiently leveraging spatiotemporal structure. FSL for 3D detection from LiDAR or depth data faces challenges like sparsity and lack of texture. Solutions integrate FSL with specialized point cloud networks and losses tailored for class imbalance. Few-shot 3D detection enables practical autonomous driving deployment by minimizing costly 3D annotation needs. Core issues in both domains include balancing generalization and overfitting, integrating prototype matching, and handling data modality properties. In summary, FSL shows promise for reducing annotation requirements and enabling real-world video, 3D, and other applications by efficiently leveraging information across feature, temporal, and data modalities. By comprehensively surveying recent advancements, this paper illuminates FSL's potential to minimize supervision needs and enable deployment across video, 3D, and other real-world applications.
Physics-Informed Neural Network Surrogate Models for River Stage Prediction
Mar 21, 2025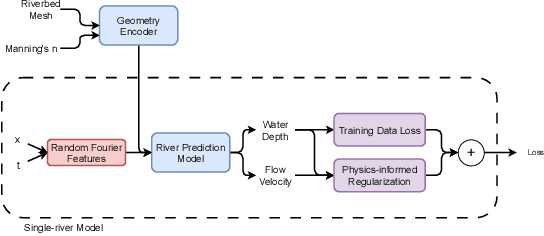
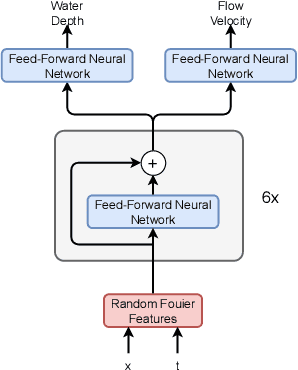
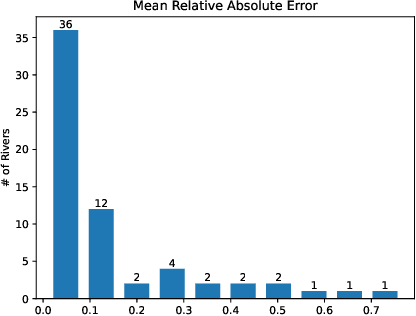
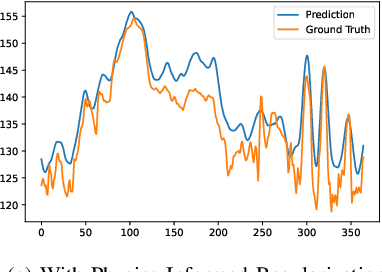
This work investigates the feasibility of using Physics-Informed Neural Networks (PINNs) as surrogate models for river stage prediction, aiming to reduce computational cost while maintaining predictive accuracy. Our primary contribution demonstrates that PINNs can successfully approximate HEC-RAS numerical solutions when trained on a single river, achieving strong predictive accuracy with generally low relative errors, though some river segments exhibit higher deviations. By integrating the governing Saint-Venant equations into the learning process, the proposed PINN-based surrogate model enforces physical consistency and significantly improves computational efficiency compared to HEC-RAS. We evaluate the model's performance in terms of accuracy and computational speed, demonstrating that it closely approximates HEC-RAS predictions while enabling real-time inference. These results highlight the potential of PINNs as effective surrogate models for single-river hydrodynamics, offering a promising alternative for computationally efficient river stage forecasting. Future work will explore techniques to enhance PINN training stability and robustness across a more generalized multi-river model.
KANICE: Kolmogorov-Arnold Networks with Interactive Convolutional Elements
Oct 22, 2024


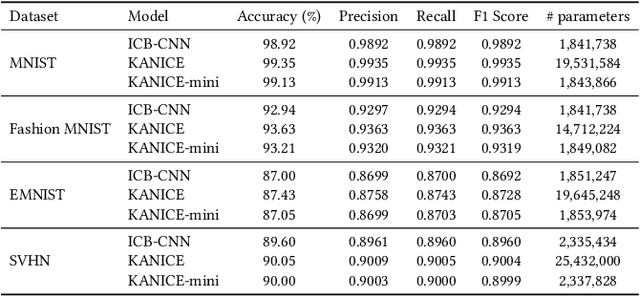
We introduce KANICE (Kolmogorov-Arnold Networks with Interactive Convolutional Elements), a novel neural architecture that combines Convolutional Neural Networks (CNNs) with Kolmogorov-Arnold Network (KAN) principles. KANICE integrates Interactive Convolutional Blocks (ICBs) and KAN linear layers into a CNN framework. This leverages KANs' universal approximation capabilities and ICBs' adaptive feature learning. KANICE captures complex, non-linear data relationships while enabling dynamic, context-dependent feature extraction based on the Kolmogorov-Arnold representation theorem. We evaluated KANICE on four datasets: MNIST, Fashion-MNIST, EMNIST, and SVHN, comparing it against standard CNNs, CNN-KAN hybrids, and ICB variants. KANICE consistently outperformed baseline models, achieving 99.35% accuracy on MNIST and 90.05% on the SVHN dataset. Furthermore, we introduce KANICE-mini, a compact variant designed for efficiency. A comprehensive ablation study demonstrates that KANICE-mini achieves comparable performance to KANICE with significantly fewer parameters. KANICE-mini reached 90.00% accuracy on SVHN with 2,337,828 parameters, compared to KANICE's 25,432,000. This study highlights the potential of KAN-based architectures in balancing performance and computational efficiency in image classification tasks. Our work contributes to research in adaptive neural networks, integrates mathematical theorems into deep learning architectures, and explores the trade-offs between model complexity and performance, advancing computer vision and pattern recognition. The source code for this paper is publicly accessible through our GitHub repository (https://github.com/m-ferdaus/kanice).