 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Multi-Robot Coverage Path Planning of Non-Convex Regions of Interests
Apr 24, 2026This letter presents an energy-efficient multi-robot coverage path planning (MRCPP) framework for large, nonconvex Regions of Interest (ROI) containing obstacles and no-fly zones (NFZ). Existing minimum-energy coverage planning algorithms utilize meta-heuristic boustrophedon workspace decomposition. Therefore, even with minimum energy objectives and energy consumption constraints, they cannot achieve optimal energy efficiency. Moreover, most existing frameworks support only a single type of robotic platform. MRCPP overcomes these limitations by: generating globally-informed swath generation, creating parallel sweeping paths with minimal turns, calculating safety buffers to ensure safe turning clearance, using an efficient mTSP solver to balance workloads and minimize mission time, and connecting disjoint segments via a modified visibility graph that tracks heading angles while maintaining transitions within safe regions. The efficacy of the proposed MRCPP framework is demonstrated through real-world experiments involving autonomous aerial vehicles (AAVs) and autonomous surface vehicles (ASVs). Evaluations demonstrate that the proposed MRCPP consistently outperforms state-of-the-art planners, reducing average total energy consumption by 3\% to 40\% for a team of 3 robots and computation time by an order of magnitude, while maintaining balanced workload distribution and strong scalability across increasing fleet sizes. The MRCPP framework is released as an open-source package and videos of real-world and simulated experiments are available at https://mrc-pp.github.io.
A Novel Hybrid Deep Learning Technique for Speech Emotion Detection using Feature Engineering
Jul 09, 2025Nowadays, speech emotion recognition (SER) plays a vital role in the field of human-computer interaction (HCI) and the evolution of artificial intelligence (AI). Our proposed DCRF-BiLSTM model is used to recognize seven emotions: neutral, happy, sad, angry, fear, disgust, and surprise, which are trained on five datasets: RAVDESS (R), TESS (T), SAVEE (S), EmoDB (E), and Crema-D (C). The model achieves high accuracy on individual datasets, including 97.83% on RAVDESS, 97.02% on SAVEE, 95.10% for CREMA-D, and a perfect 100% on both TESS and EMO-DB. For the combined (R+T+S) datasets, it achieves 98.82% accuracy, outperforming previously reported results. To our knowledge, no existing study has evaluated a single SER model across all five benchmark datasets (i.e., R+T+S+C+E) simultaneously. In our work, we introduce this comprehensive combination and achieve a remarkable overall accuracy of 93.76%. These results confirm the robustness and generalizability of our DCRF-BiLSTM framework across diverse datasets.
SHARP-Net: A Refined Pyramid Network for Deficiency Segmentation in Culverts and Sewer Pipes
Aug 02, 2024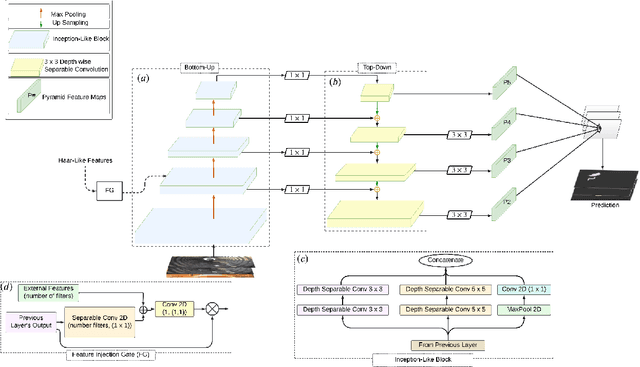
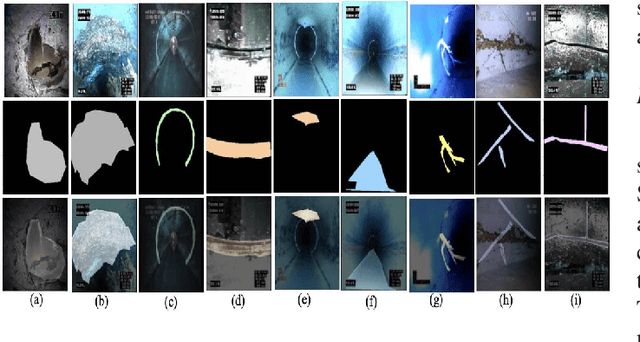
This paper introduces Semantic Haar-Adaptive Refined Pyramid Network (SHARP-Net), a novel architecture for semantic segmentation. SHARP-Net integrates a bottom-up pathway featuring Inception-like blocks with varying filter sizes (3x3$ and 5x5), parallel max-pooling, and additional spatial detection layers. This design captures multi-scale features and fine structural details. Throughout the network, depth-wise separable convolutions are used to reduce complexity. The top-down pathway of SHARP-Net focuses on generating high-resolution features through upsampling and information fusion using $1\times1$ and $3\times3$ depth-wise separable convolutions. We evaluated our model using our developed challenging Culvert-Sewer Defects dataset and the benchmark DeepGlobe Land Cover dataset. Our experimental evaluation demonstrated the base model's (excluding Haar-like features) effectiveness in handling irregular defect shapes, occlusions, and class imbalances. It outperformed state-of-the-art methods, including U-Net, CBAM U-Net, ASCU-Net, FPN, and SegFormer, achieving average improvements of 14.4% and 12.1% on the Culvert-Sewer Defects and DeepGlobe Land Cover datasets, respectively, with IoU scores of 77.2% and 70.6%. Additionally, the training time was reduced. Furthermore, the integration of carefully selected and fine-tuned Haar-like features enhanced the performance of deep learning models by at least 20%. The proposed SHARP-Net, incorporating Haar-like features, achieved an impressive IoU of 94.75%, representing a 22.74% improvement over the base model. These features were also applied to other deep learning models, showing a 35.0% improvement, proving their versatility and effectiveness. SHARP-Net thus provides a powerful and efficient solution for accurate semantic segmentation in challenging real-world scenarios.
Dual Attention U-Net with Feature Infusion: Pushing the Boundaries of Multiclass Defect Segmentation
Dec 21, 2023The proposed architecture, Dual Attentive U-Net with Feature Infusion (DAU-FI Net), addresses challenges in semantic segmentation, particularly on multiclass imbalanced datasets with limited samples. DAU-FI Net integrates multiscale spatial-channel attention mechanisms and feature injection to enhance precision in object localization. The core employs a multiscale depth-separable convolution block, capturing localized patterns across scales. This block is complemented by a spatial-channel squeeze and excitation (scSE) attention unit, modeling inter-dependencies between channels and spatial regions in feature maps. Additionally, additive attention gates refine segmentation by connecting encoder-decoder pathways. To augment the model, engineered features using Gabor filters for textural analysis, Sobel and Canny filters for edge detection are injected guided by semantic masks to expand the feature space strategically. Comprehensive experiments on a challenging sewer pipe and culvert defect dataset and a benchmark dataset validate DAU-FI Net's capabilities. Ablation studies highlight incremental benefits from attention blocks and feature injection. DAU-FI Net achieves state-of-the-art mean Intersection over Union (IoU) of 95.6% and 98.8% on the defect test set and benchmark respectively, surpassing prior methods by 8.9% and 12.6%, respectively. Ablation studies highlight incremental benefits from attention blocks and feature injection. The proposed architecture provides a robust solution, advancing semantic segmentation for multiclass problems with limited training data. Our sewer-culvert defects dataset, featuring pixel-level annotations, opens avenues for further research in this crucial domain. Overall, this work delivers key innovations in architecture, attention, and feature engineering to elevate semantic segmentation efficacy.
A LightGBM based Forecasting of Dominant Wave Periods in Oceanic Waters
May 21, 2021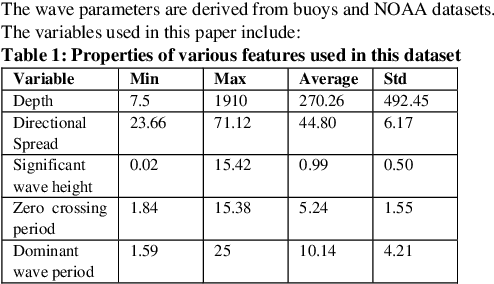
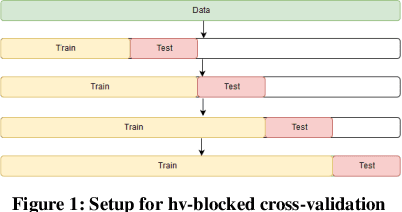
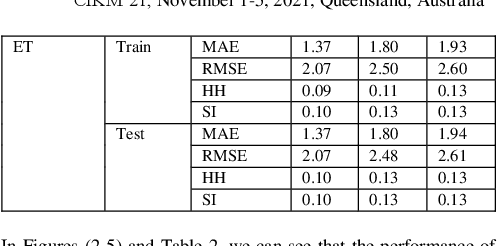
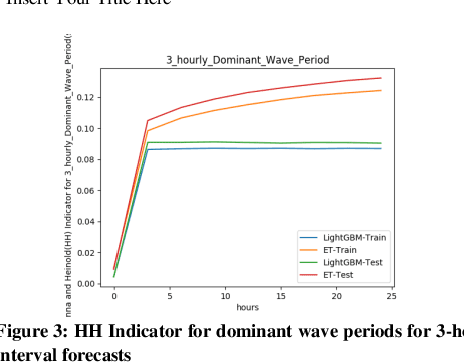
In this paper, we propose a Light Gradient Boosting (LightGBM) to forecast dominant wave periods in oceanic waters. First, we use the data collected from CDIP buoys and apply various data filtering methods. The data filtering methods allow us to obtain a high-quality dataset for training and validation purposes. We then extract various wave-based features like wave heights, periods, skewness, kurtosis, etc., and atmospheric features like humidity, pressure, and air temperature for the buoys. Afterward, we train algorithms that use LightGBM and Extra Trees through a hv-block cross-validation scheme to forecast dominant wave periods for up to 30 days ahead. LightGBM has the R2 score of 0.94, 0.94, and 0.94 for 1-day ahead, 15-day ahead, and 30-day ahead prediction. Similarly, Extra Trees (ET) has an R2 score of 0.88, 0.86, and 0.85 for 1-day ahead, 15-day ahead, and 30 day ahead prediction. In case of the test dataset, LightGBM has R2 score of 0.94, 0.94, and 0.94 for 1-day ahead, 15-day ahead and 30-day ahead prediction. ET has R2 score of 0.88, 0.86, and 0.85 for 1-day ahead, 15-day ahead, and 30-day ahead prediction. A similar R2 score for both training and the test dataset suggests that the machine learning models developed in this paper are robust. Since the LightGBM algorithm outperforms ET for all the windows tested, it is taken as the final algorithm. Note that the performance of both methods does not decrease significantly as the forecast horizon increases. Likewise, the proposed method outperforms the numerical approaches included in this paper in the test dataset. For 1 day ahead prediction, the proposed algorithm has SI, Bias, CC, and RMSE of 0.09, 0.00, 0.97, and 1.78 compared to 0.268, 0.40, 0.63, and 2.18 for the European Centre for Medium-range Weather Forecasts (ECMWF) model, which outperforms all the other methods in the test dataset.
Forecasting Significant Wave Heights in Oceanic Waters
May 18, 2021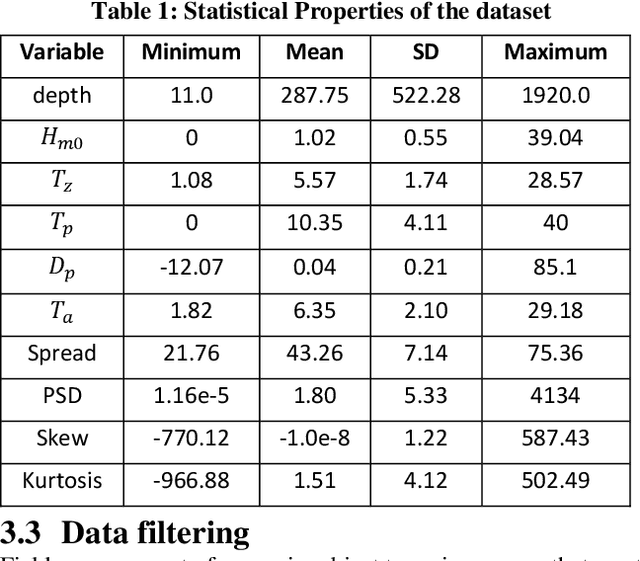

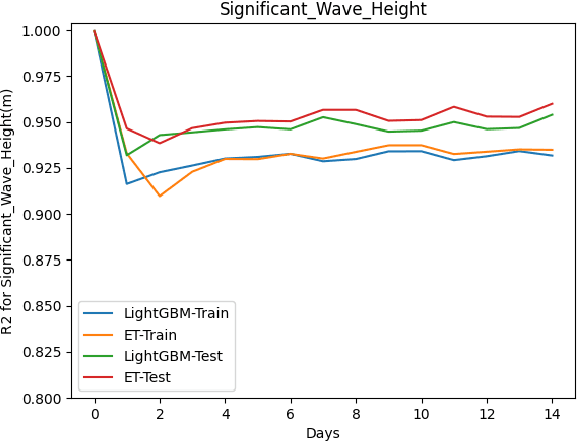
This paper proposes a machine learning method based on the Extra Trees (ET) algorithm for forecasting Significant Wave Heights in oceanic waters. To derive multiple features from the CDIP buoys, which make point measurements, we first nowcast various parameters and then forecast them at 30-min intervals. The proposed algorithm has Scatter Index (SI), Bias, Correlation Coefficient, Root Mean Squared Error (RMSE) of 0.130, -0.002, 0.97, and 0.14, respectively, for one day ahead prediction and 0.110, -0.001, 0.98, and 0.122, respectively, for 14-day ahead prediction on the testing dataset. While other state-of-the-art methods can only forecast up to 120 hours ahead, we extend it further to 14 days. This 14-day limit is not the forecasting limit, but it arises due to our experiment's setup. Our proposed setup includes spectral features, hv-block cross-validation, and stringent QC criteria. The proposed algorithm performs significantly better than the state-of-the-art methods commonly used for significant wave height forecasting for one-day ahead prediction. Moreover, the improved performance of the proposed machine learning method compared to the numerical methods, shows that this performance can be extended to even longer time periods allowing for early prediction of significant wave heights in oceanic waters.
Random Forest Classifier Based Prediction of Rogue waves on Deep Oceans
Mar 13, 2020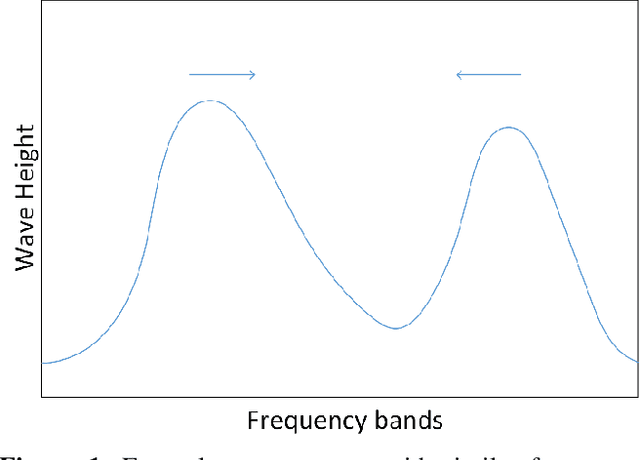
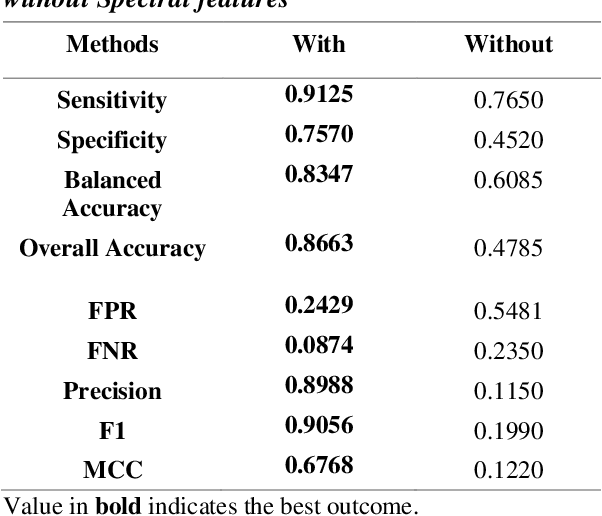
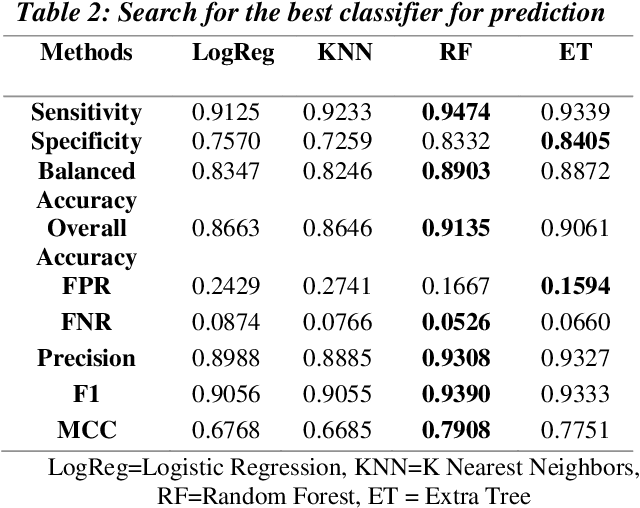
In this paper, we present a novel approach for the prediction of rogue waves in oceans using statistical machine learning methods. Since the ocean is composed of many wave systems, the change from a bimodal or multimodal directional distribution to unimodal one is taken as the warning criteria. Likewise, we explore various features that help in predicting rogue waves. The analysis of the results shows that the Spectral features are significant in predicting rogue waves. We find that nonlinear classifiers have better prediction accuracy than the linear ones. Finally, we propose a Random Forest Classifier based algorithm to predict rogue waves in oceanic conditions. The proposed algorithm has an Overall Accuracy of 89.57% to 91.81%, and the Balanced Accuracy varies between 79.41% to 89.03% depending on the forecast time window. Moreover, due to the model-free nature of the evaluation criteria and interdisciplinary characteristics of the approach, similar studies may be motivated in other nonlinear dispersive media, such as nonlinear optics, plasma, and solids, governed by similar equations, which will allow for the early detection of extreme waves
Machine Learning based Prediction of Hierarchical Classification of Transposable Elements
Jul 09, 2019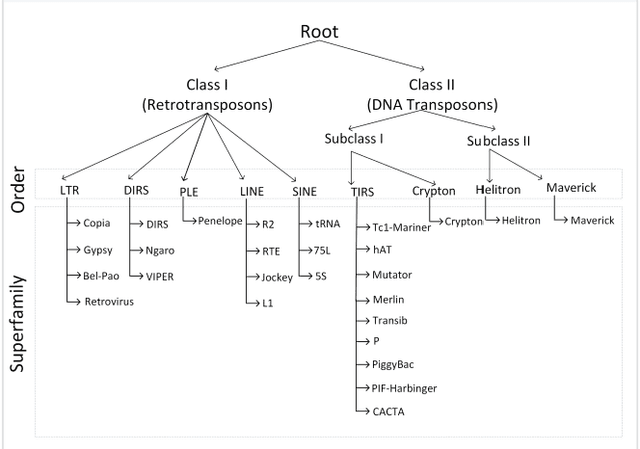
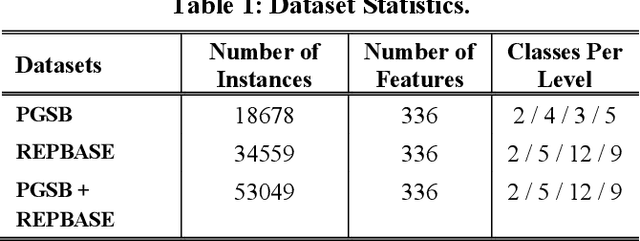

Transposable Elements (TEs) or jumping genes are the DNA sequences that have an intrinsic capability to move within a host genome from one genomic location to another. Studies show that the presence of a TE within or adjacent to a functional gene may alter its expression. TEs can also cause an increase in the rate of mutation and can even mediate duplications and large insertions and deletions in the genome, promoting gross genetic rearrangements. Thus, the proper classification of the identified jumping genes is essential to understand their genetic and evolutionary effects in the genome. While computational methods have been developed that perform either binary classification or multi-label classification of TEs, few studies have focused on their hierarchical classification. The state-of-the-art machine learning classification method utilizes a Multi-Layer Perceptron (MLP), a class of neural network, for hierarchical classification of TEs. However, the existing methods have limited accuracy in classifying TEs. A more effective classifier, which can explain the role of TEs in germline and somatic evolution, is needed. In this study, we examine the performance of a variety of machine learning (ML) methods. And eventually, propose a robust approach for the hierarchical classification of TEs, with higher accuracy, using Support Vector Machines (SVM).
Guided macro-mutation in a graded energy based genetic algorithm for protein structure prediction
Mar 07, 2016
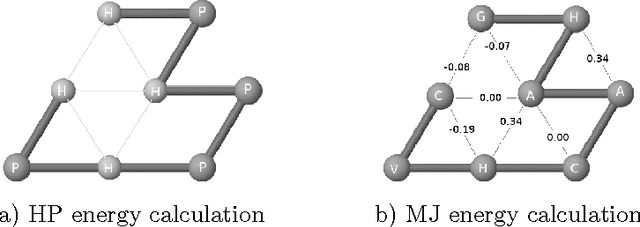
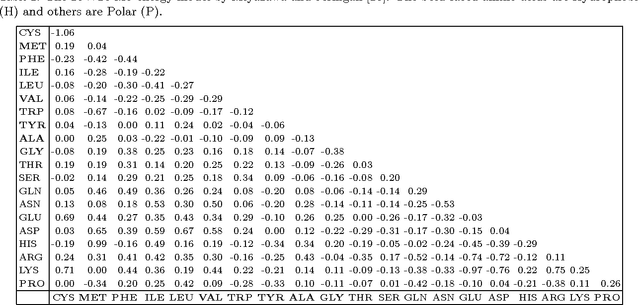
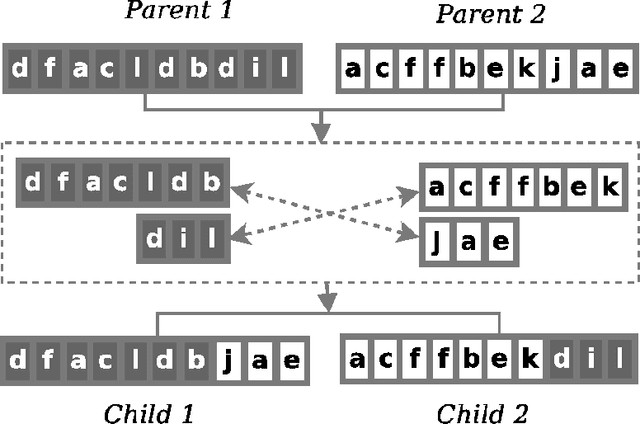
Protein structure prediction is considered as one of the most challenging and computationally intractable combinatorial problem. Thus, the efficient modeling of convoluted search space, the clever use of energy functions, and more importantly, the use of effective sampling algorithms become crucial to address this problem. For protein structure modeling, an off-lattice model provides limited scopes to exercise and evaluate the algorithmic developments due to its astronomically large set of data-points. In contrast, an on-lattice model widens the scopes and permits studying the relatively larger proteins because of its finite set of data-points. In this work, we took the full advantage of an on-lattice model by using a face-centered-cube lattice that has the highest packing density with the maximum degree of freedom. We proposed a graded energy-strategically mixes the Miyazawa-Jernigan (MJ) energy with the hydrophobic-polar (HP) energy-based genetic algorithm (GA) for conformational search. In our application, we introduced a 2x2 HP energy guided macro-mutation operator within the GA to explore the best possible local changes exhaustively. Conversely, the 20x20 MJ energy model-the ultimate objective function of our GA that needs to be minimized-considers the impacts amongst the 20 different amino acids and allow searching the globally acceptable conformations. On a set of benchmark proteins, our proposed approach outperformed state-of-the-art approaches in terms of the free energy levels and the root-mean-square deviations.
* 29 pages. arXiv admin note: text overlap with arXiv:1311.3840