 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Travelling Thief Problems using Coordination Based Methods
Oct 11, 2023A travelling thief problem (TTP) is a proxy to real-life problems such as postal collection. TTP comprises an entanglement of a travelling salesman problem (TSP) and a knapsack problem (KP) since items of KP are scattered over cities of TSP, and a thief has to visit cities to collect items. In TTP, city selection and item selection decisions need close coordination since the thief's travelling speed depends on the knapsack's weight and the order of visiting cities affects the order of item collection. Existing TTP solvers deal with city selection and item selection separately, keeping decisions for one type unchanged while dealing with the other type. This separation essentially means very poor coordination between two types of decision. In this paper, we first show that a simple local search based coordination approach does not work in TTP. Then, to address the aforementioned problems, we propose a human designed coordination heuristic that makes changes to collection plans during exploration of cyclic tours. We further propose another human designed coordination heuristic that explicitly exploits the cyclic tours in item selections during collection plan exploration. Lastly, we propose a machine learning based coordination heuristic that captures characteristics of the two human designed coordination heuristics. Our proposed coordination based approaches help our TTP solver significantly outperform existing state-of-the-art TTP solvers on a set of benchmark problems. Our solver is named Cooperation Coordination (CoCo) and its source code is available from https://github.com/majid75/CoCo
Deontic Meta-Rules
Sep 23, 2022The use of meta-rules in logic, i.e., rules whose content includes other rules, has recently gained attention in the setting of non-monotonic reasoning: a first logical formalisation and efficient algorithms to compute the (meta)-extensions of such theories were proposed in Olivieri et al (2021) This work extends such a logical framework by considering the deontic aspect. The resulting logic will not just be able to model policies but also tackle well-known aspects that occur in numerous legal systems. The use of Defeasible Logic (DL) to model meta-rules in the application area we just alluded to has been investigated. Within this line of research, the study mentioned above was not focusing on the general computational properties of meta-rules. This study fills this gap with two major contributions. First, we introduce and formalise two variants of Defeasible Deontic Logic with Meta-Rules to represent (1) defeasible meta-theories with deontic modalities, and (2) two different types of conflicts among rules: Simple Conflict Defeasible Deontic Logic, and Cautious Conflict Defeasible Deontic Logic. Second, we advance efficient algorithms to compute the extensions for both variants.
Surrogate Assisted Optimisation for Travelling Thief Problems
May 14, 2020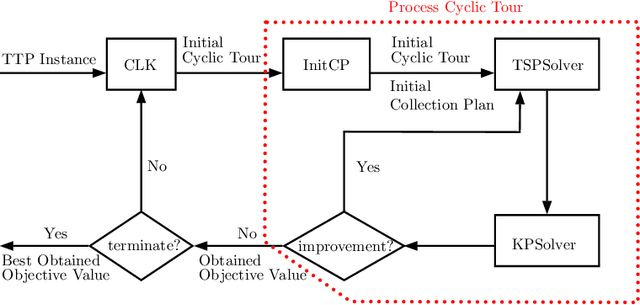
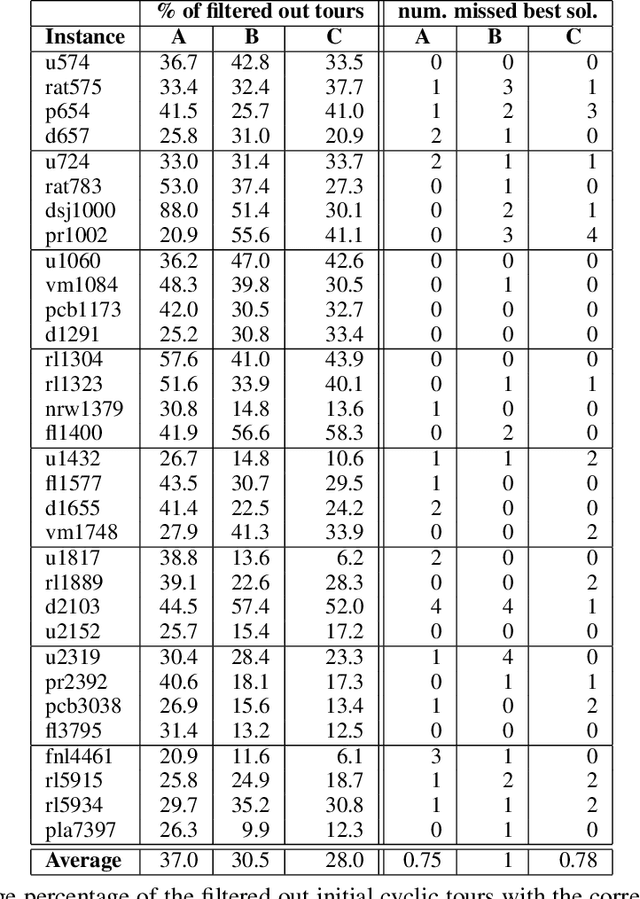

The travelling thief problem (TTP) is a multi-component optimisation problem involving two interdependent NP-hard components: the travelling salesman problem (TSP) and the knapsack problem (KP). Recent state-of-the-art TTP solvers modify the underlying TSP and KP solutions in an iterative and interleaved fashion. The TSP solution (cyclic tour) is typically changed in a deterministic way, while changes to the KP solution typically involve a random search, effectively resulting in a quasi-meandering exploration of the TTP solution space. Once a plateau is reached, the iterative search of the TTP solution space is restarted by using a new initial TSP tour. We propose to make the search more efficient through an adaptive surrogate model (based on a customised form of Support Vector Regression) that learns the characteristics of initial TSP tours that lead to good TTP solutions. The model is used to filter out non-promising initial TSP tours, in effect reducing the amount of time spent to find a good TTP solution. Experiments on a broad range of benchmark TTP instances indicate that the proposed approach filters out a considerable number of non-promising initial tours, at the cost of omitting only a small number of the best TTP solutions.
A Cooperative Coordination Solver for Travelling Thief Problems
Nov 08, 2019
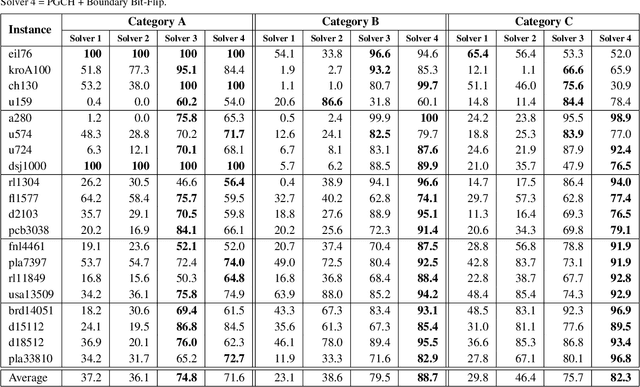
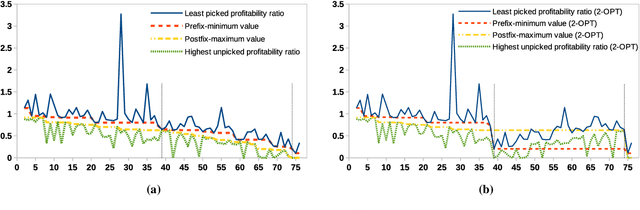
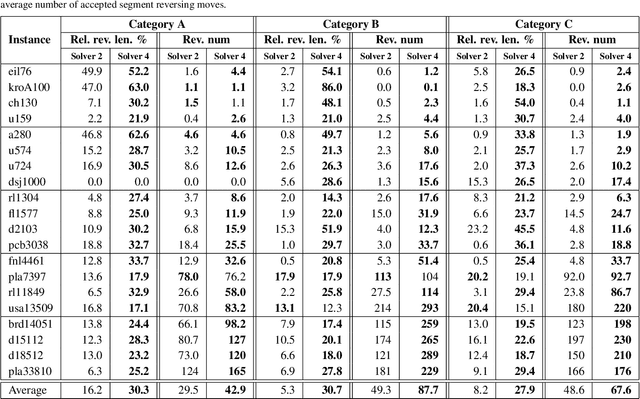
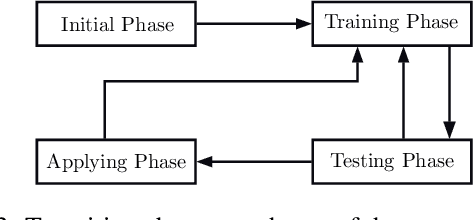
In the travelling thief problem (TTP), a thief undertakes a cyclic tour through a set of cities, and according to a picking plan, picks a subset of available items into a rented knapsack with limited capacity. The overall aim is to maximise profit while minimising renting cost. TTP combines two interdependent components: the travelling salesman problem (TSP) and the knapsack problem (KP). Existing TTP approaches typically solve the TSP and KP components in an interleaved fashion: the solution of one component is fixed while the solution of the other is changed. This indicates poor coordination between solving the two components, which may lead to poor quality TTP solutions. The 2-OPT heuristic is often used for solving the TSP component, which reverses a segment in the tour. Within the TTP context, 2-OPT does not take into account the picking plan, which can result in a lower objective value. This in turn can result in the tour modification to be rejected by a solver. To address this, we propose an extended form of 2-OPT in order to change the picking plan in coordination with modifying the tour. Items deemed as less profitable and picked in cities earlier in the reversed segment are replaced by items that tend to be equally or more profitable and not picked in cities later in the reversed segment. The picking plan is further changed through a modified form of the bit-flip search, where changes in the picking state are only permitted for boundary items, which are defined as lowest profitable picked items or highest profitable unpicked items. This restriction reduces the amount of time spent on the KP component, allowing more tours to be evaluated by the TSP component within a given time budget. The two modified heuristics form the basis of a new cooperative coordination solver, which is shown to outperform several state-of-the-art TTP solvers on a broad range of benchmark TTP instances.
Toxicity Prediction by Multimodal Deep Learning
Jul 19, 2019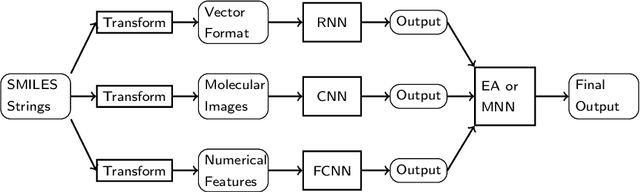

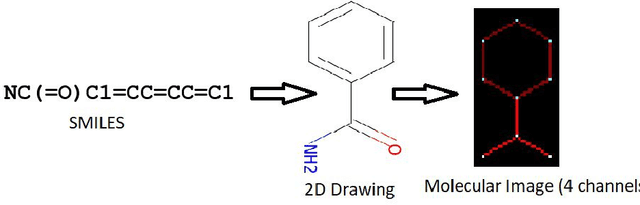

Prediction of toxicity levels of chemical compounds is an important issue in Quantitative Structure-Activity Relationship (QSAR) modeling. Although toxicity prediction has achieved significant progress in recent times through deep learning, prediction accuracy levels obtained by even very recent methods are not yet very high. We propose a multimodal deep learning method using multiple heterogeneous neural network types and data representations. We represent chemical compounds by strings, images, and numerical features. We train fully connected, convolutional, and recurrent neural networks and their ensembles. Each data representation or neural network type has its own strengths and weaknesses. Our motivation is to obtain a collective performance that could go beyond individual performance of each data representation or each neural network type. On a standard toxicity benchmark, our proposed method obtains significantly better accuracy levels than that by the state-of-the-art toxicity prediction methods.
* Preprint Version
Efficient Toxicity Prediction via Simple Features Using Shallow Neural Networks and Decision Trees
Jan 26, 2019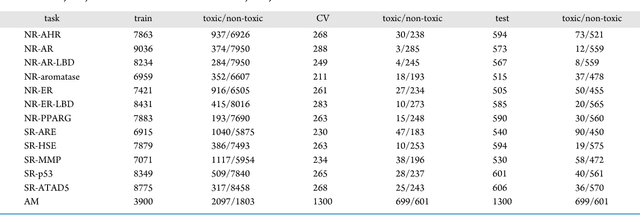
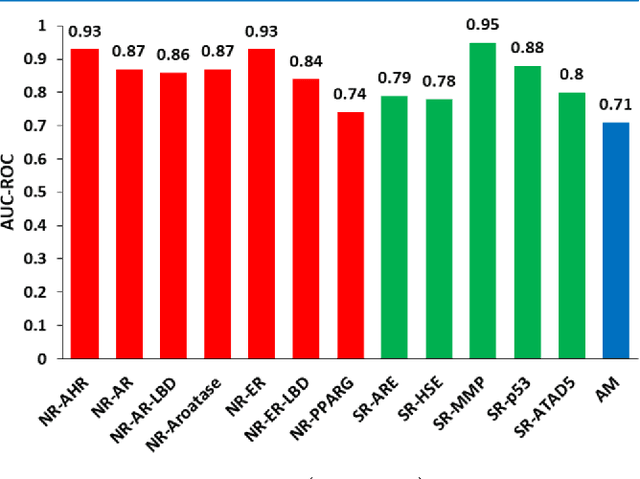
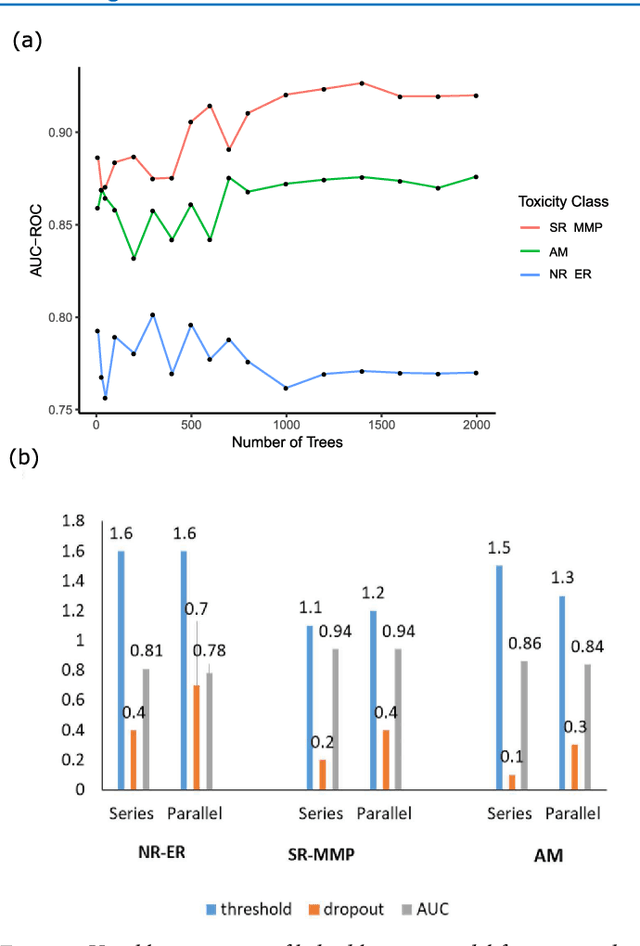
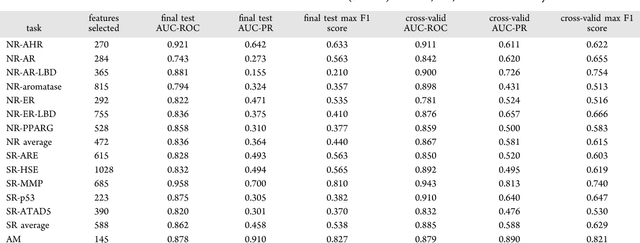
Toxicity prediction of chemical compounds is a grand challenge. Lately, it achieved significant progress in accuracy but using a huge set of features, implementing a complex blackbox technique such as a deep neural network, and exploiting enormous computational resources. In this paper, we strongly argue for the models and methods that are simple in machine learning characteristics, efficient in computing resource usage, and powerful to achieve very high accuracy levels. To demonstrate this, we develop a single task-based chemical toxicity prediction framework using only 2D features that are less compute intensive. We effectively use a decision tree to obtain an optimum number of features from a collection of thousands of them. We use a shallow neural network and jointly optimize it with decision tree taking both network parameters and input features into account. Our model needs only a minute on a single CPU for its training while existing methods using deep neural networks need about 10 min on NVidia Tesla K40 GPU. However, we obtain similar or better performance on several toxicity benchmark tasks. We also develop a cumulative feature ranking method which enables us to identify features that can help chemists perform prescreening of toxic compounds effectively.
Diversified Late Acceptance Search
Sep 10, 2018
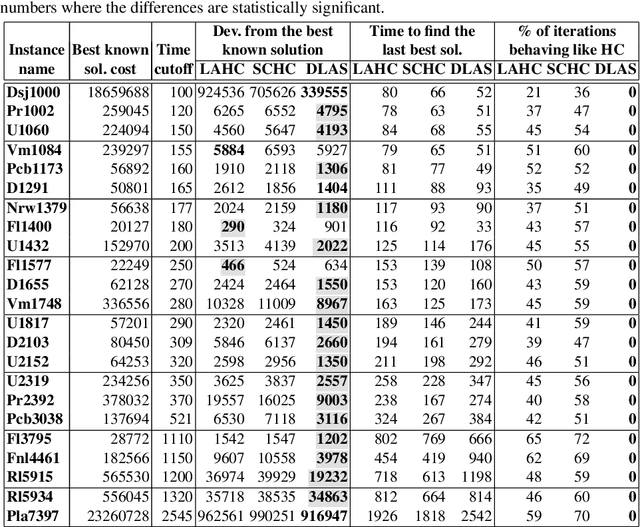
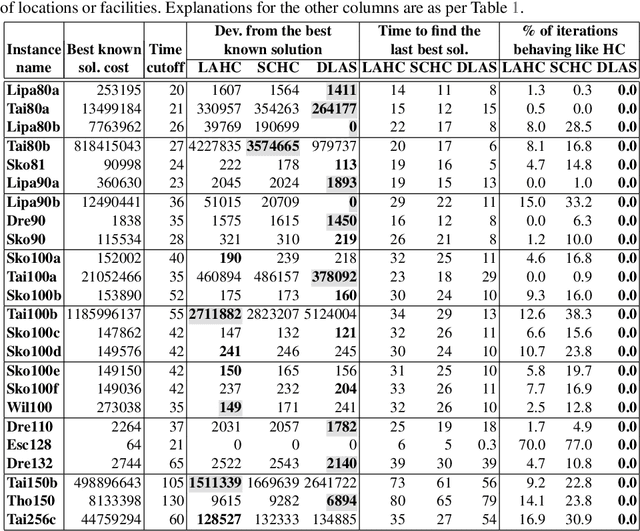
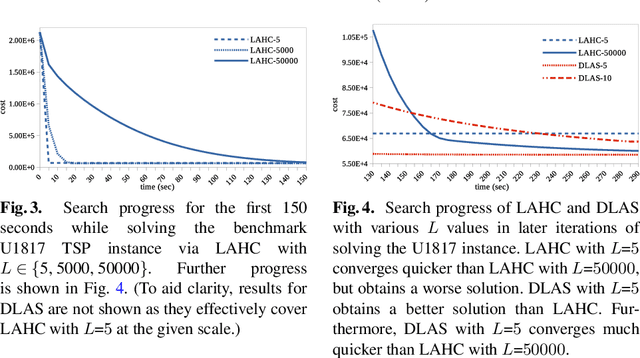
The well-known Late Acceptance Hill Climbing (LAHC) search aims to overcome the main downside of traditional Hill Climbing (HC) search, which is often quickly trapped in a local optimum due to strictly accepting only non-worsening moves within each iteration. In contrast, LAHC also accepts worsening moves, by keeping a circular array of fitness values of previously visited solutions and comparing the fitness values of candidate solutions against the least recent element in the array. While this straightforward strategy has proven effective, there are nevertheless situations where LAHC can unfortunately behave in a similar manner to HC. For example, when a new local optimum is found, often the same fitness value is stored many times in the array. To address this shortcoming, we propose new acceptance and replacement strategies to take into account worsening, improving, and sideways movement scenarios with the aim to improve the diversity of values in the array. Compared to LAHC, the proposed Diversified Late Acceptance Search approach is shown to lead to better quality solutions that are obtained with a lower number of iterations on benchmark Travelling Salesman Problems and Quadratic Assignment Problems.
Dropout with Tabu Strategy for Regularizing Deep Neural Networks
Aug 29, 2018

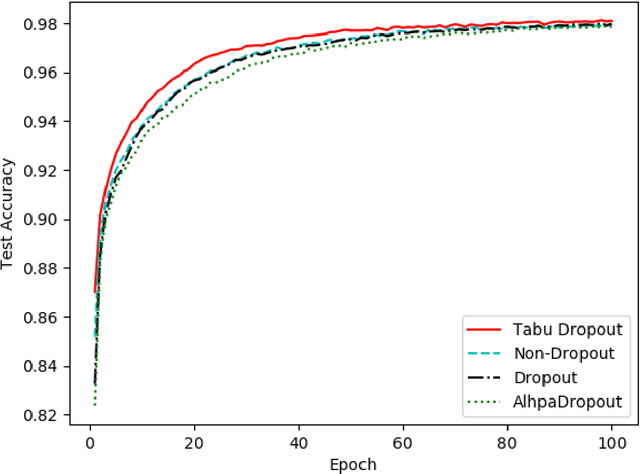
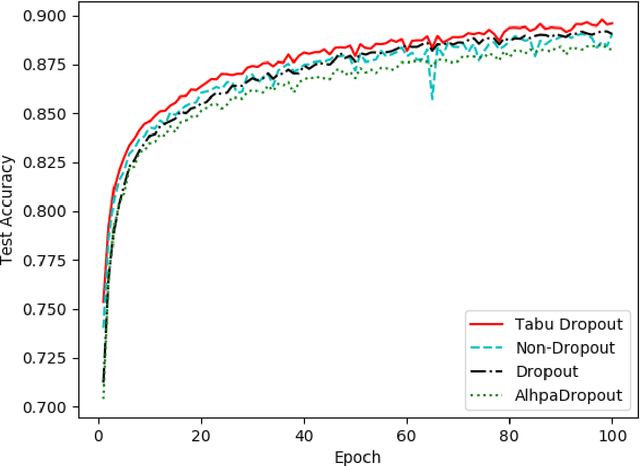
Dropout has proven to be an effective technique for regularization and preventing the co-adaptation of neurons in deep neural networks (DNN). It randomly drops units with a probability $p$ during the training stage of DNN. Dropout also provides a way of approximately combining exponentially many different neural network architectures efficiently. In this work, we add a diversification strategy into dropout, which aims at generating more different neural network architectures in a proper times of iterations. The dropped units in last forward propagation will be marked. Then the selected units for dropping in the current FP will be kept if they have been marked in the last forward propagation. We only mark the units from the last forward propagation. We call this new technique Tabu Dropout. Tabu Dropout has no extra parameters compared with the standard Dropout and also it is computationally cheap. The experiments conducted on MNIST, Fashion-MNIST datasets show that Tabu Dropout improves the performance of the standard dropout.
Machine Learning Interpretability: A Science rather than a tool
Jul 25, 2018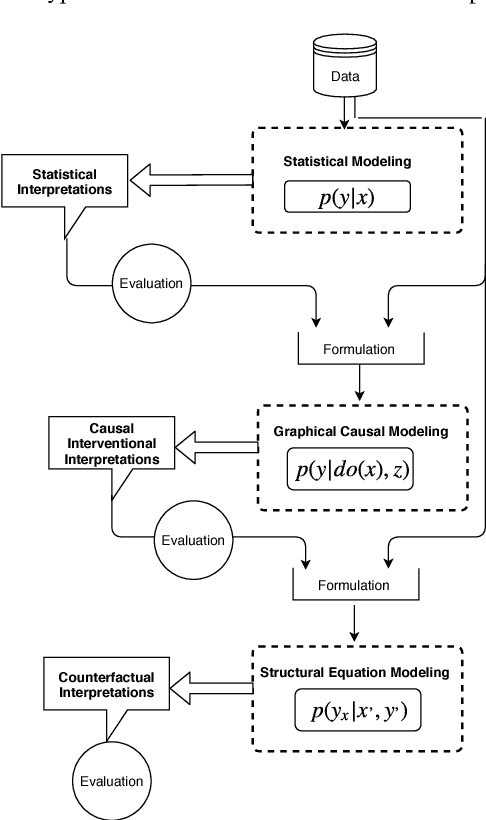
The term "interpretability" is oftenly used by machine learning researchers each with their own intuitive understanding of it. There is no universal well agreed upon definition of interpretability in machine learning. As any type of science discipline is mainly driven by the set of formulated questions rather than by different tools in that discipline, e.g. astrophysics is the discipline that learns the composition of stars, not as the discipline that use the spectroscopes. Similarly, we propose that machine learning interpretability should be a discipline that answers specific questions related to interpretability. These questions can be of statistical, causal and counterfactual nature. Therefore, there is a need to look into the interpretability problem of machine learning in the context of questions that need to be addressed rather than different tools. We discuss about a hypothetical interpretability framework driven by a question based scientific approach rather than some specific machine learning model. Using a question based notion of interpretability, we can step towards understanding the science of machine learning rather than its engineering. This notion will also help us understanding any specific problem more in depth rather than relying solely on machine learning methods.
A New Approach for Revising Logic Programs
Mar 31, 2016Belief revision has been studied mainly with respect to background logics that are monotonic in character. In this paper we study belief revision when the underlying logic is non-monotonic instead--an inherently interesting problem that is under explored. In particular, we will focus on the revision of a body of beliefs that is represented as a logic program under the answer set semantics, while the new information is also similarly represented as a logic program. Our approach is driven by the observation that unlike in a monotonic setting where, when necessary, consistency in a revised body of beliefs is maintained by jettisoning some old beliefs, in a non-monotonic setting consistency can be restored by adding new beliefs as well. We will define a syntactic revision function and subsequently provide representation theorem for characterising it.