 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSdCT-GAN: Reconstructing CT from Biplanar X-Rays with Self-driven Generative Adversarial Networks
Sep 10, 2023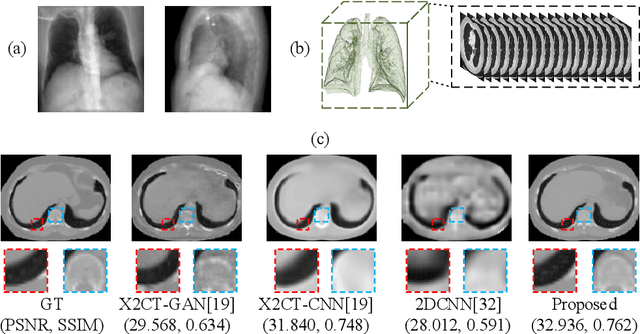
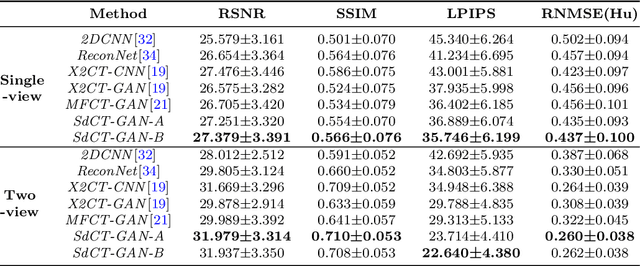
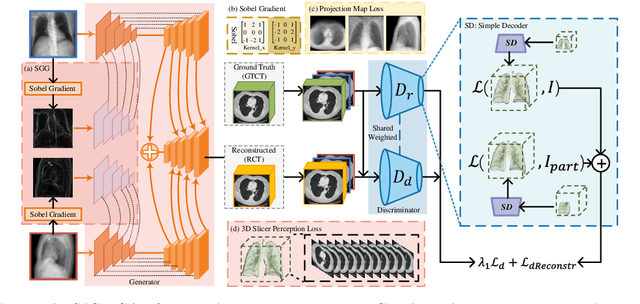

Computed Tomography (CT) is a medical imaging modality that can generate more informative 3D images than 2D X-rays. However, this advantage comes at the expense of more radiation exposure, higher costs, and longer acquisition time. Hence, the reconstruction of 3D CT images using a limited number of 2D X-rays has gained significant importance as an economical alternative. Nevertheless, existing methods primarily prioritize minimizing pixel/voxel-level intensity discrepancies, often neglecting the preservation of textural details in the synthesized images. This oversight directly impacts the quality of the reconstructed images and thus affects the clinical diagnosis. To address the deficits, this paper presents a new self-driven generative adversarial network model (SdCT-GAN), which is motivated to pay more attention to image details by introducing a novel auto-encoder structure in the discriminator. In addition, a Sobel Gradient Guider (SGG) idea is applied throughout the model, where the edge information from the 2D X-ray image at the input can be integrated. Moreover, LPIPS (Learned Perceptual Image Patch Similarity) evaluation metric is adopted that can quantitatively evaluate the fine contours and textures of reconstructed images better than the existing ones. Finally, the qualitative and quantitative results of the empirical studies justify the power of the proposed model compared to mainstream state-of-the-art baselines.
Dropout with Tabu Strategy for Regularizing Deep Neural Networks
Aug 29, 2018

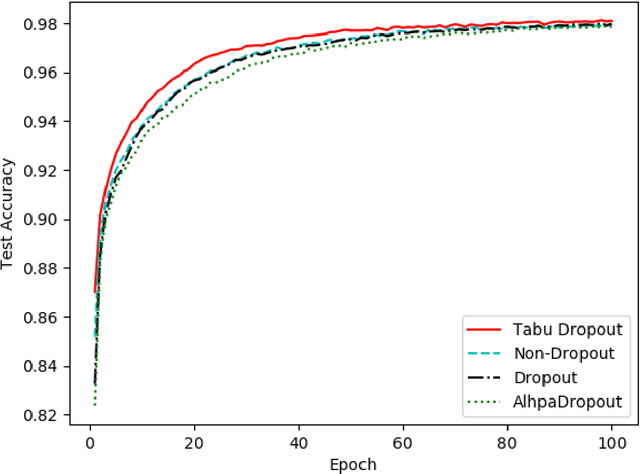
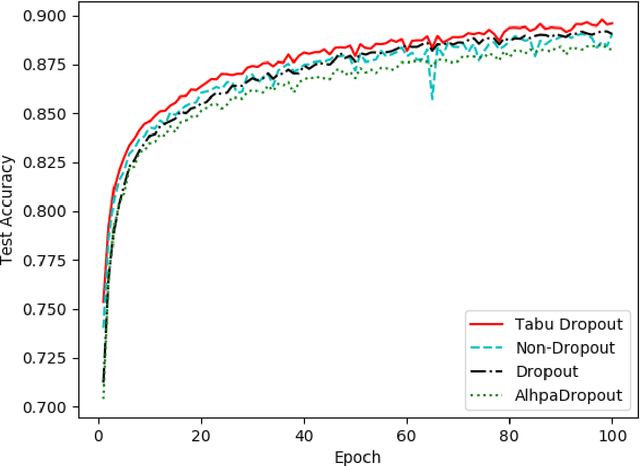
Dropout has proven to be an effective technique for regularization and preventing the co-adaptation of neurons in deep neural networks (DNN). It randomly drops units with a probability $p$ during the training stage of DNN. Dropout also provides a way of approximately combining exponentially many different neural network architectures efficiently. In this work, we add a diversification strategy into dropout, which aims at generating more different neural network architectures in a proper times of iterations. The dropped units in last forward propagation will be marked. Then the selected units for dropping in the current FP will be kept if they have been marked in the last forward propagation. We only mark the units from the last forward propagation. We call this new technique Tabu Dropout. Tabu Dropout has no extra parameters compared with the standard Dropout and also it is computationally cheap. The experiments conducted on MNIST, Fashion-MNIST datasets show that Tabu Dropout improves the performance of the standard dropout.
Advancing Tabu and Restart in Local Search for Maximum Weight Cliques
Apr 22, 2018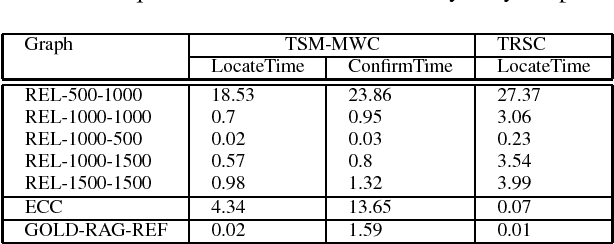
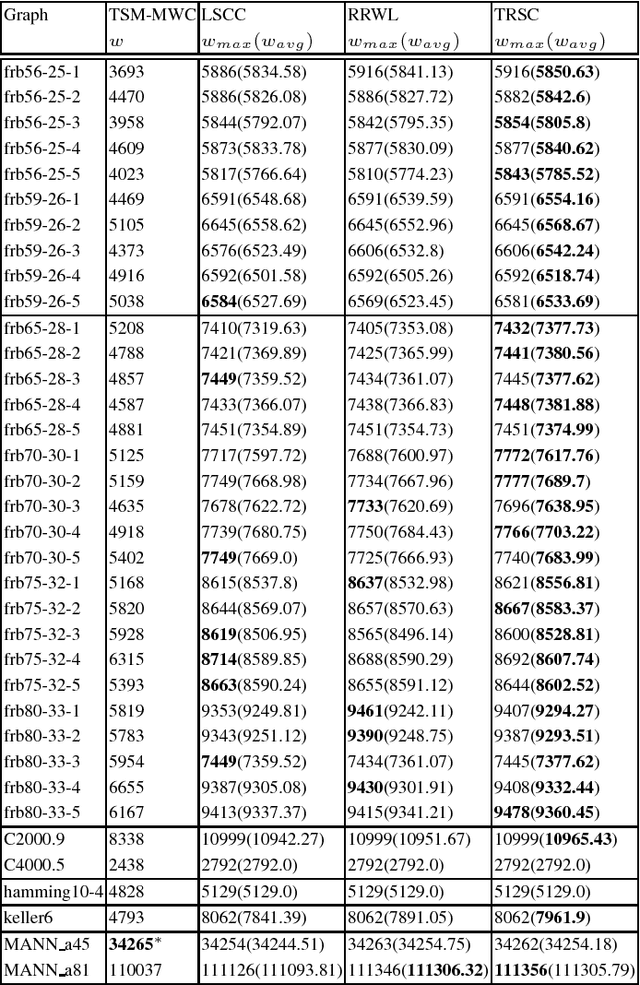
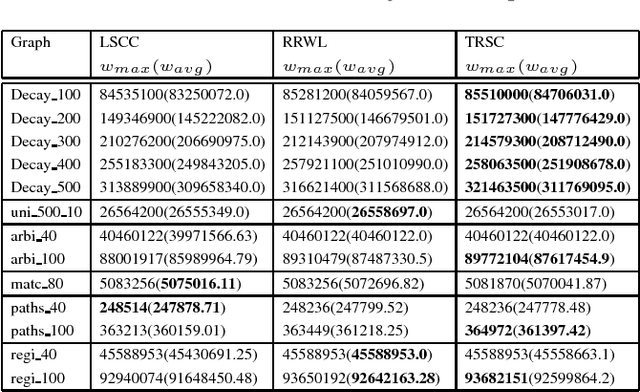
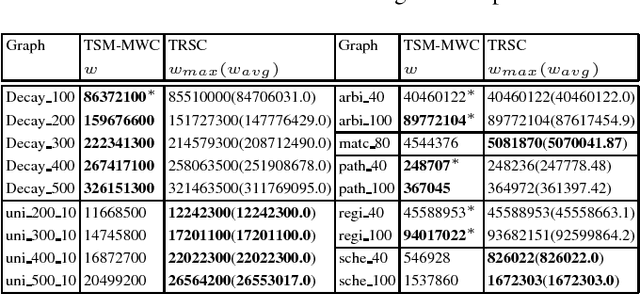
The tabu and restart are two fundamental strategies for local search. In this paper, we improve the local search algorithms for solving the Maximum Weight Clique (MWC) problem by introducing new tabu and restart strategies. Both the tabu and restart strategies proposed are based on the notion of a local search scenario, which involves not only a candidate solution but also the tabu status and unlocking relationship. Compared to the strategy of configuration checking, our tabu mechanism discourages forming a cycle of unlocking operations. Our new restart strategy is based on the re-occurrence of a local search scenario instead of that of a candidate solution. Experimental results show that the resulting MWC solver outperforms several state-of-the-art solvers on the DIMACS, BHOSLIB, and two benchmarks from practical applications.
Trainable back-propagated functional transfer matrices
Oct 28, 2017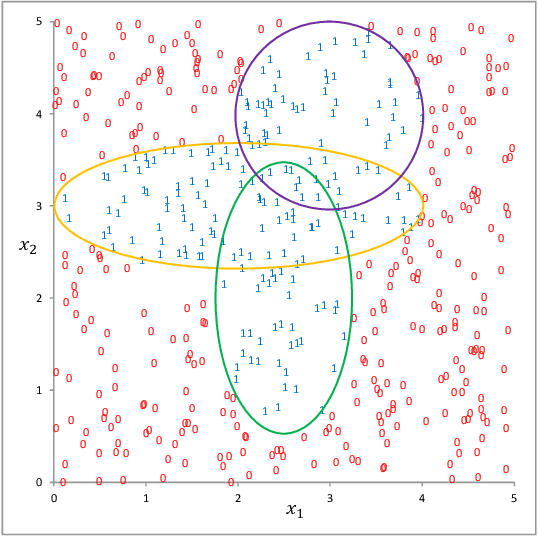
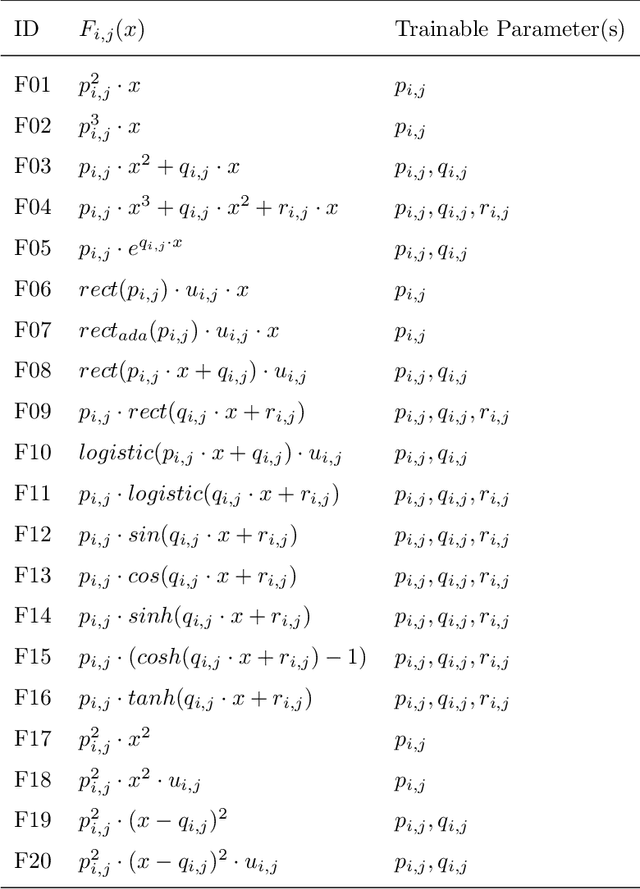
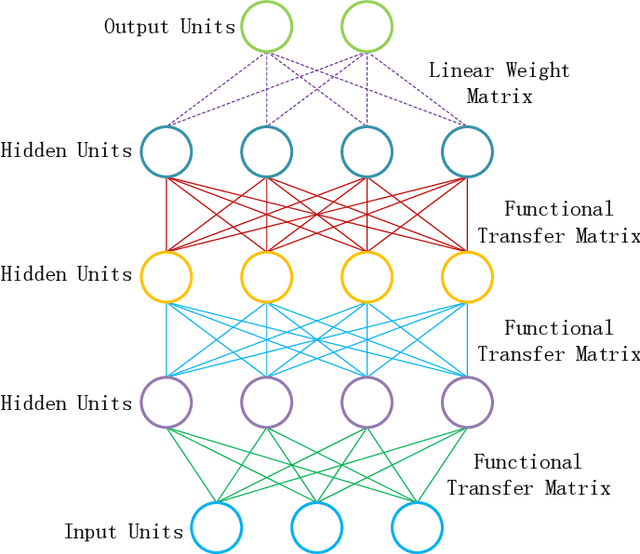

Connections between nodes of fully connected neural networks are usually represented by weight matrices. In this article, functional transfer matrices are introduced as alternatives to the weight matrices: Instead of using real weights, a functional transfer matrix uses real functions with trainable parameters to represent connections between nodes. Multiple functional transfer matrices are then stacked together with bias vectors and activations to form deep functional transfer neural networks. These neural networks can be trained within the framework of back-propagation, based on a revision of the delta rules and the error transmission rule for functional connections. In experiments, it is demonstrated that the revised rules can be used to train a range of functional connections: 20 different functions are applied to neural networks with up to 10 hidden layers, and most of them gain high test accuracies on the MNIST database. It is also demonstrated that a functional transfer matrix with a memory function can roughly memorise a non-cyclical sequence of 400 digits.
* 39 pages, 4 figures, submitted as a journal article
Learning of Human-like Algebraic Reasoning Using Deep Feedforward Neural Networks
Apr 25, 2017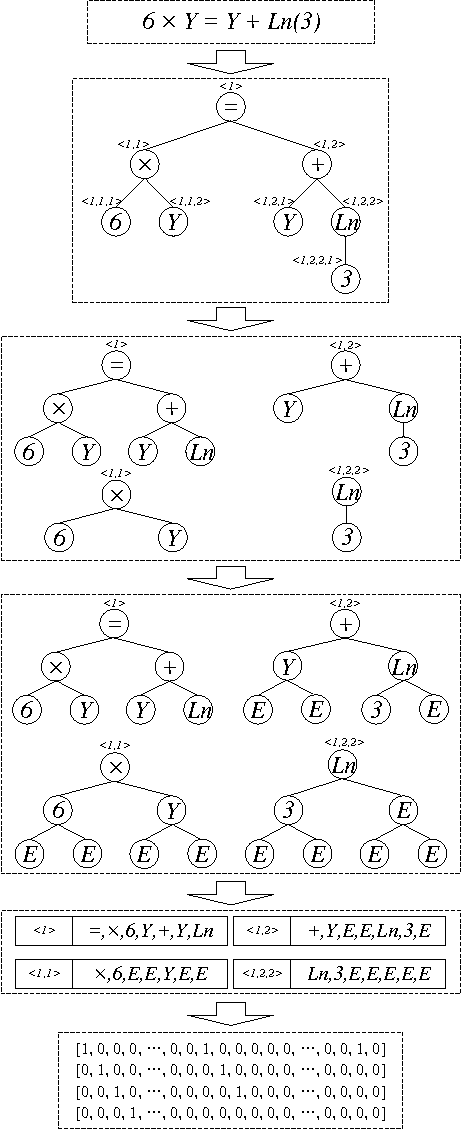
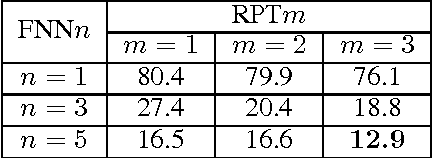
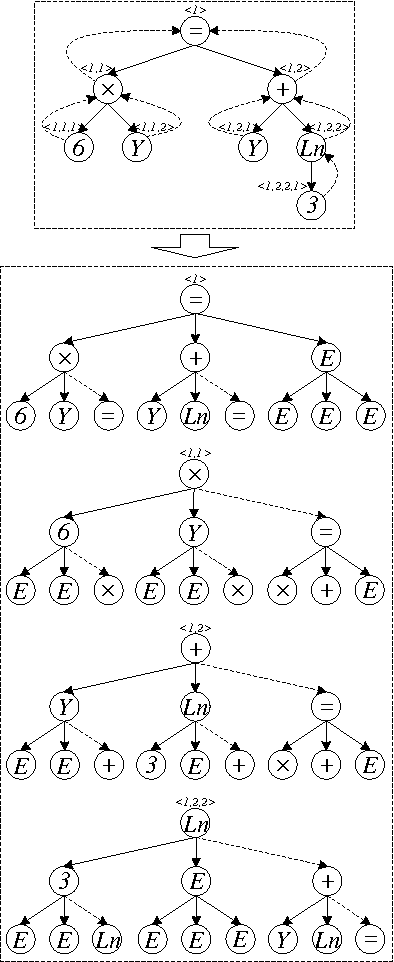
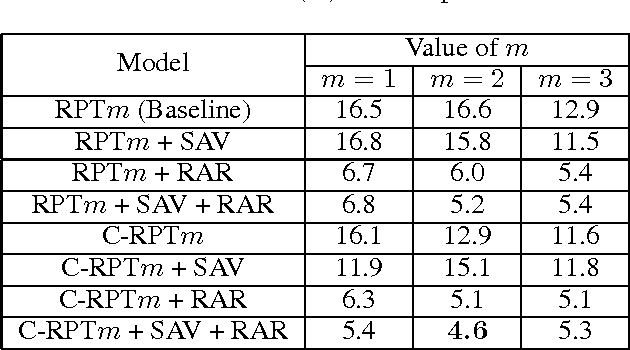
There is a wide gap between symbolic reasoning and deep learning. In this research, we explore the possibility of using deep learning to improve symbolic reasoning. Briefly, in a reasoning system, a deep feedforward neural network is used to guide rewriting processes after learning from algebraic reasoning examples produced by humans. To enable the neural network to recognise patterns of algebraic expressions with non-deterministic sizes, reduced partial trees are used to represent the expressions. Also, to represent both top-down and bottom-up information of the expressions, a centralisation technique is used to improve the reduced partial trees. Besides, symbolic association vectors and rule application records are used to improve the rewriting processes. Experimental results reveal that the algebraic reasoning examples can be accurately learnt only if the feedforward neural network has enough hidden layers. Also, the centralisation technique, the symbolic association vectors and the rule application records can reduce error rates of reasoning. In particular, the above approaches have led to 4.6% error rate of reasoning on a dataset of linear equations, differentials and integrals.
Normative Multiagent Systems: A Dynamic Generalization
Apr 18, 2016Social norms are powerful formalism in coordinating autonomous agents' behaviour to achieve certain objectives. In this paper, we propose a dynamic normative system to enable the reasoning of the changes of norms under different circumstances, which cannot be done in the existing static normative systems. We study two important problems (norm synthesis and norm recognition) related to the autonomy of the entire system and the agents, and characterise the computational complexities of solving these problems.
NuMVC: An Efficient Local Search Algorithm for Minimum Vertex Cover
Feb 04, 2014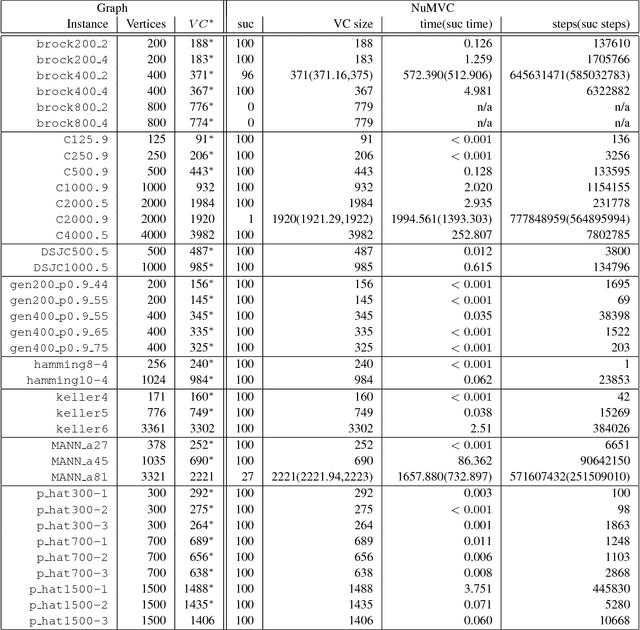
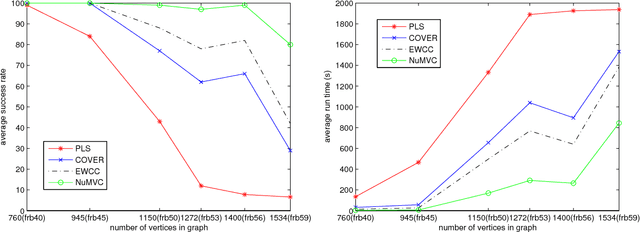
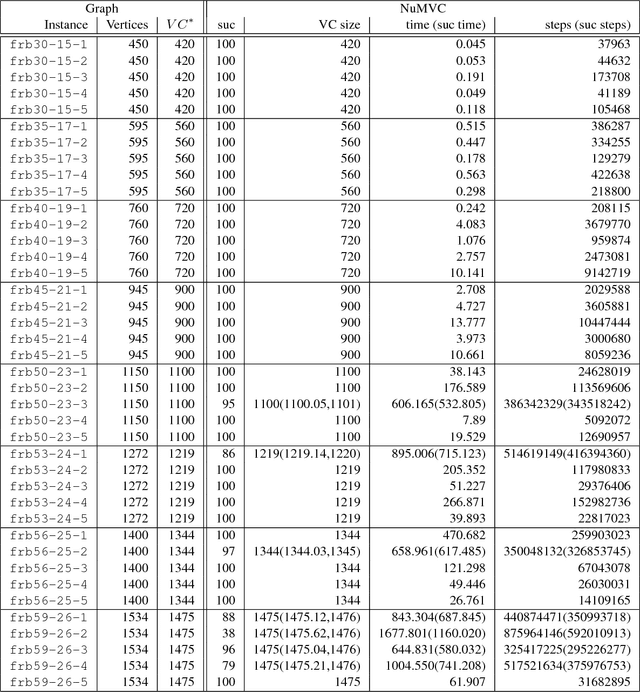
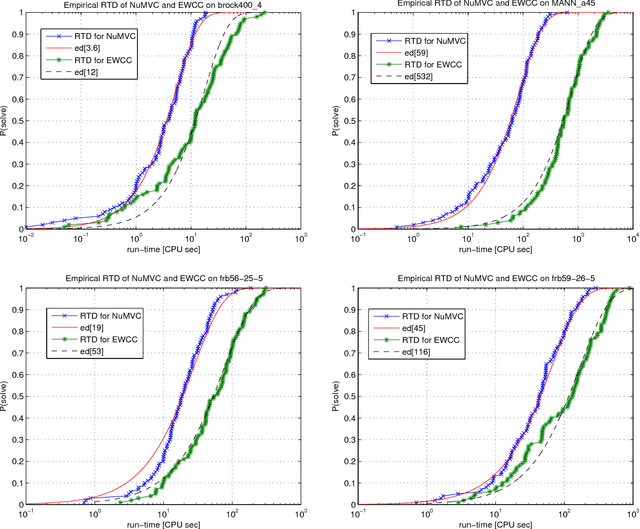
The Minimum Vertex Cover (MVC) problem is a prominent NP-hard combinatorial optimization problem of great importance in both theory and application. Local search has proved successful for this problem. However, there are two main drawbacks in state-of-the-art MVC local search algorithms. First, they select a pair of vertices to exchange simultaneously, which is time-consuming. Secondly, although using edge weighting techniques to diversify the search, these algorithms lack mechanisms for decreasing the weights. To address these issues, we propose two new strategies: two-stage exchange and edge weighting with forgetting. The two-stage exchange strategy selects two vertices to exchange separately and performs the exchange in two stages. The strategy of edge weighting with forgetting not only increases weights of uncovered edges, but also decreases some weights for each edge periodically. These two strategies are used in designing a new MVC local search algorithm, which is referred to as NuMVC. We conduct extensive experimental studies on the standard benchmarks, namely DIMACS and BHOSLIB. The experiment comparing NuMVC with state-of-the-art heuristic algorithms show that NuMVC is at least competitive with the nearest competitor namely PLS on the DIMACS benchmark, and clearly dominates all competitors on the BHOSLIB benchmark. Also, experimental results indicate that NuMVC finds an optimal solution much faster than the current best exact algorithm for Maximum Clique on random instances as well as some structured ones. Moreover, we study the effectiveness of the two strategies and the run-time behaviour through experimental analysis.
Variable Forgetting in Reasoning about Knowledge
Jan 15, 2014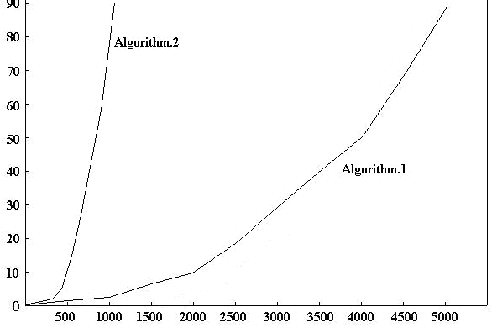
In this paper, we investigate knowledge reasoning within a simple framework called knowledge structure. We use variable forgetting as a basic operation for one agent to reason about its own or other agents\ knowledge. In our framework, two notions namely agents\ observable variables and the weakest sufficient condition play important roles in knowledge reasoning. Given a background knowledge base and a set of observable variables for each agent, we show that the notion of an agent knowing a formula can be defined as a weakest sufficient condition of the formula under background knowledge base. Moreover, we show how to capture the notion of common knowledge by using a generalized notion of weakest sufficient condition. Also, we show that public announcement operator can be conveniently dealt with via our notion of knowledge structure. Further, we explore the computational complexity of the problem whether an epistemic formula is realized in a knowledge structure. In the general case, this problem is PSPACE-hard; however, for some interesting subcases, it can be reduced to co-NP. Finally, we discuss possible applications of our framework in some interesting domains such as the automated analysis of the well-known muddy children puzzle and the verification of the revised Needham-Schroeder protocol. We believe that there are many scenarios where the natural presentation of the available information about knowledge is under the form of a knowledge structure. What makes it valuable compared with the corresponding multi-agent S5 Kripke structure is that it can be much more succinct.