 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Renal Tumor Malignancy Prediction: Deep Learning with Automatic 3D CT Organ Focused Attention
Feb 25, 2026Accurate prediction of malignancy in renal tumors is crucial for informing clinical decisions and optimizing treatment strategies. However, existing imaging modalities lack the necessary accuracy to reliably predict malignancy before surgical intervention. While deep learning has shown promise in malignancy prediction using 3D CT images, traditional approaches often rely on manual segmentation to isolate the tumor region and reduce noise, which enhances predictive performance. Manual segmentation, however, is labor-intensive, costly, and dependent on expert knowledge. In this study, a deep learning framework was developed utilizing an Organ Focused Attention (OFA) loss function to modify the attention of image patches so that organ patches attend only to other organ patches. Hence, no segmentation of 3D renal CT images is required at deployment time for malignancy prediction. The proposed framework achieved an AUC of 0.685 and an F1-score of 0.872 on a private dataset from the UF Integrated Data Repository (IDR), and an AUC of 0.760 and an F1-score of 0.852 on the publicly available KiTS21 dataset. These results surpass the performance of conventional models that rely on segmentation-based cropping for noise reduction, demonstrating the frameworks ability to enhance predictive accuracy without explicit segmentation input. The findings suggest that this approach offers a more efficient and reliable method for malignancy prediction, thereby enhancing clinical decision-making in renal cancer diagnosis.
Preserving Localized Patch Semantics in VLMs
Feb 02, 2026Logit Lens has been proposed for visualizing tokens that contribute most to LLM answers. Recently, Logit Lens was also shown to be applicable in autoregressive Vision-Language Models (VLMs), where it illustrates the conceptual content of image tokens in the form of heatmaps, e.g., which image tokens are likely to depict the concept of cat in a given image. However, the visual content of image tokens often gets diffused to language tokens, and consequently, the locality of visual information gets mostly destroyed, which renders Logit Lens visualization unusable for explainability. To address this issue, we introduce a complementary loss to next-token prediction (NTP) to prevent the visual tokens from losing the visual representation inherited from corresponding image patches. The proposed Logit Lens Loss (LLL) is designed to make visual token embeddings more semantically aligned with the textual concepts that describe their image regions (e.g., patches containing a cat with the word "cat"), without requiring any architectural modification or large-scale training. This way, LLL constrains the mixing of image and text tokens in the self-attention layers in order to prevent image tokens from losing their localized visual information. As our experiments show, LLL not only makes Logit Lens practically relevant by producing meaningful object confidence maps in images, but also improves performance on vision-centric tasks like segmentation without attaching any special heads.
Direct Visual Grounding by Directing Attention of Visual Tokens
Nov 16, 2025Vision Language Models (VLMs) mix visual tokens and text tokens. A puzzling issue is the fact that visual tokens most related to the query receive little to no attention in the final layers of the LLM module of VLMs from the answer tokens, where all tokens are treated equally, in particular, visual and language tokens in the LLM attention layers. This fact may result in wrong answers to visual questions, as our experimental results confirm. It appears that the standard next-token prediction (NTP) loss provides an insufficient signal for directing attention to visual tokens. We hypothesize that a more direct supervision of the attention of visual tokens to corresponding language tokens in the LLM module of VLMs will lead to improved performance on visual tasks. To demonstrate that this is indeed the case, we propose a novel loss function that directly supervises the attention of visual tokens. It directly grounds the answer language tokens in images by directing their attention to the relevant visual tokens. This is achieved by aligning the attention distribution of visual tokens to ground truth attention maps with KL divergence. The ground truth attention maps are obtained from task geometry in synthetic cases or from standard grounding annotations (e.g., bounding boxes or point annotations) in real images, and are used inside the LLM for attention supervision without requiring new labels. The obtained KL attention loss (KLAL) when combined with NTP encourages VLMs to attend to relevant visual tokens while generating answer tokens. This results in notable improvements across geometric tasks, pointing, and referring expression comprehension on both synthetic and real-world data, as demonstrated by our experiments. We also introduce a new dataset to evaluate the line tracing abilities of VLMs. Surprisingly, even commercial VLMs do not perform well on this task.
Layout Stroke Imitation: A Layout Guided Handwriting Stroke Generation for Style Imitation with Diffusion Model
Sep 19, 2025Handwriting stroke generation is crucial for improving the performance of tasks such as handwriting recognition and writers order recovery. In handwriting stroke generation, it is significantly important to imitate the sample calligraphic style. The previous studies have suggested utilizing the calligraphic features of the handwriting. However, they had not considered word spacing (word layout) as an explicit handwriting feature, which results in inconsistent word spacing for style imitation. Firstly, this work proposes multi-scale attention features for calligraphic style imitation. These multi-scale feature embeddings highlight the local and global style features. Secondly, we propose to include the words layout, which facilitates word spacing for handwriting stroke generation. Moreover, we propose a conditional diffusion model to predict strokes in contrast to previous work, which directly generated style images. Stroke generation provides additional temporal coordinate information, which is lacking in image generation. Hence, our proposed conditional diffusion model for stroke generation is guided by calligraphic style and word layout for better handwriting imitation and stroke generation in a calligraphic style. Our experimentation shows that the proposed diffusion model outperforms the current state-of-the-art stroke generation and is competitive with recent image generation networks.
Learning Object Focused Attention
Apr 10, 2025We propose an adaptation to the training of Vision Transformers (ViTs) that allows for an explicit modeling of objects during the attention computation. This is achieved by adding a new branch to selected attention layers that computes an auxiliary loss which we call the object-focused attention (OFA) loss. We restrict the attention to image patches that belong to the same object class, which allows ViTs to gain a better understanding of configural (or holistic) object shapes by focusing on intra-object patches instead of other patches such as those in the background. Our proposed inductive bias fits easily into the attention framework of transformers since it only adds an auxiliary loss over selected attention layers. Furthermore, our approach has no additional overhead during inference. We also experiment with multiscale masking to further improve the performance of our OFA model and give a path forward for self-supervised learning with our method. Our experimental results demonstrate that ViTs with OFA achieve better classification results than their base models, exhibit a stronger generalization ability to out-of-distribution (OOD) and adversarially corrupted images, and learn representations based on object shapes rather than spurious correlations via general textures. For our OOD setting, we generate a novel dataset using the COCO dataset and Stable Diffusion inpainting which we plan to share with the community.
DynClean: Training Dynamics-based Label Cleaning for Distantly-Supervised Named Entity Recognition
Apr 06, 2025Distantly Supervised Named Entity Recognition (DS-NER) has attracted attention due to its scalability and ability to automatically generate labeled data. However, distant annotation introduces many mislabeled instances, limiting its performance. Most of the existing work attempt to solve this problem by developing intricate models to learn from the noisy labels. An alternative approach is to attempt to clean the labeled data, thus increasing the quality of distant labels. This approach has received little attention for NER. In this paper, we propose a training dynamics-based label cleaning approach, which leverages the behavior of a model as training progresses to characterize the distantly annotated samples. We also introduce an automatic threshold estimation strategy to locate the errors in distant labels. Extensive experimental results demonstrate that: (1) models trained on our cleaned DS-NER datasets, which were refined by directly removing identified erroneous annotations, achieve significant improvements in F1-score, ranging from 3.18% to 8.95%; and (2) our method outperforms numerous advanced DS-NER approaches across four datasets.
SciER: An Entity and Relation Extraction Dataset for Datasets, Methods, and Tasks in Scientific Documents
Oct 28, 2024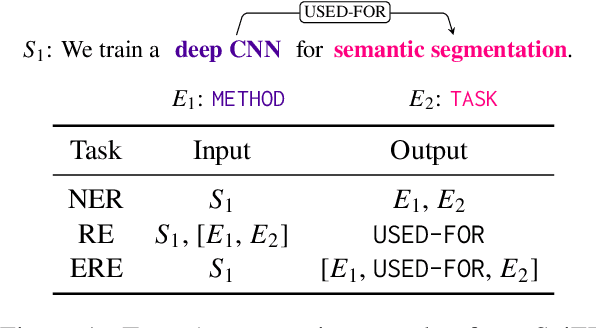
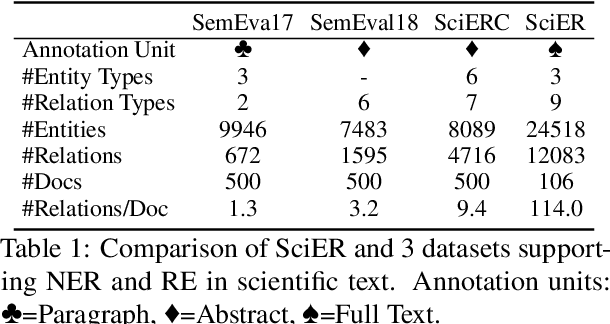


Scientific information extraction (SciIE) is critical for converting unstructured knowledge from scholarly articles into structured data (entities and relations). Several datasets have been proposed for training and validating SciIE models. However, due to the high complexity and cost of annotating scientific texts, those datasets restrict their annotations to specific parts of paper, such as abstracts, resulting in the loss of diverse entity mentions and relations in context. In this paper, we release a new entity and relation extraction dataset for entities related to datasets, methods, and tasks in scientific articles. Our dataset contains 106 manually annotated full-text scientific publications with over 24k entities and 12k relations. To capture the intricate use and interactions among entities in full texts, our dataset contains a fine-grained tag set for relations. Additionally, we provide an out-of-distribution test set to offer a more realistic evaluation. We conduct comprehensive experiments, including state-of-the-art supervised models and our proposed LLM-based baselines, and highlight the challenges presented by our dataset, encouraging the development of innovative models to further the field of SciIE.
FlowLearn: Evaluating Large Vision-Language Models on Flowchart Understanding
Jul 09, 2024



Flowcharts are graphical tools for representing complex concepts in concise visual representations. This paper introduces the FlowLearn dataset, a resource tailored to enhance the understanding of flowcharts. FlowLearn contains complex scientific flowcharts and simulated flowcharts. The scientific subset contains 3,858 flowcharts sourced from scientific literature and the simulated subset contains 10,000 flowcharts created using a customizable script. The dataset is enriched with annotations for visual components, OCR, Mermaid code representation, and VQA question-answer pairs. Despite the proven capabilities of Large Vision-Language Models (LVLMs) in various visual understanding tasks, their effectiveness in decoding flowcharts - a crucial element of scientific communication - has yet to be thoroughly investigated. The FlowLearn test set is crafted to assess the performance of LVLMs in flowchart comprehension. Our study thoroughly evaluates state-of-the-art LVLMs, identifying existing limitations and establishing a foundation for future enhancements in this relatively underexplored domain. For instance, in tasks involving simulated flowcharts, GPT-4V achieved the highest accuracy (58%) in counting the number of nodes, while Claude recorded the highest accuracy (83%) in OCR tasks. Notably, no single model excels in all tasks within the FlowLearn framework, highlighting significant opportunities for further development.
SciDMT: A Large-Scale Corpus for Detecting Scientific Mentions
Jun 20, 2024



We present SciDMT, an enhanced and expanded corpus for scientific mention detection, offering a significant advancement over existing related resources. SciDMT contains annotated scientific documents for datasets (D), methods (M), and tasks (T). The corpus consists of two components: 1) the SciDMT main corpus, which includes 48 thousand scientific articles with over 1.8 million weakly annotated mention annotations in the format of in-text span, and 2) an evaluation set, which comprises 100 scientific articles manually annotated for evaluation purposes. To the best of our knowledge, SciDMT is the largest corpus for scientific entity mention detection. The corpus's scale and diversity are instrumental in developing and refining models for tasks such as indexing scientific papers, enhancing information retrieval, and improving the accessibility of scientific knowledge. We demonstrate the corpus's utility through experiments with advanced deep learning architectures like SciBERT and GPT-3.5. Our findings establish performance baselines and highlight unresolved challenges in scientific mention detection. SciDMT serves as a robust benchmark for the research community, encouraging the development of innovative models to further the field of scientific information extraction.
* LREC/COLING 2024
Enhanced Masked Image Modeling for Analysis of Dental Panoramic Radiographs
Jun 18, 2023The computer-assisted radiologic informative report has received increasing research attention to facilitate diagnosis and treatment planning for dental care providers. However, manual interpretation of dental images is limited, expensive, and time-consuming. Another barrier in dental imaging is the limited number of available images for training, which is a challenge in the era of deep learning. This study proposes a novel self-distillation (SD) enhanced self-supervised learning on top of the masked image modeling (SimMIM) Transformer, called SD-SimMIM, to improve the outcome with a limited number of dental radiographs. In addition to the prediction loss on masked patches, SD-SimMIM computes the self-distillation loss on the visible patches. We apply SD-SimMIM on dental panoramic X-rays for teeth numbering, detection of dental restorations and orthodontic appliances, and instance segmentation tasks. Our results show that SD-SimMIM outperforms other self-supervised learning methods. Furthermore, we augment and improve the annotation of an existing dataset of panoramic X-rays.