 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNubbleDrop: A Simple Way to Improve Matching Strategy for Prompted One-Shot Segmentation
May 19, 2024Driven by large data trained segmentation models, such as SAM , research in one-shot segmentation has experienced significant advancements. Recent contributions like PerSAM and MATCHER , presented at ICLR 2024, utilize a similar approach by leveraging SAM with one or a few reference images to generate high quality segmentation masks for target images. Specifically, they utilize raw encoded features to compute cosine similarity between patches within reference and target images along the channel dimension, effectively generating prompt points or boxes for the target images a technique referred to as the matching strategy. However, relying solely on raw features might introduce biases and lack robustness for such a complex task. To address this concern, we delve into the issues of feature interaction and uneven distribution inherent in raw feature based matching. In this paper, we propose a simple and training-free method to enhance the validity and robustness of the matching strategy at no additional computational cost (NubbleDrop). The core concept involves randomly dropping feature channels (setting them to zero) during the matching process, thereby preventing models from being influenced by channels containing deceptive information. This technique mimics discarding pathological nubbles, and it can be seamlessly applied to other similarity computing scenarios. We conduct a comprehensive set of experiments, considering a wide range of factors, to demonstrate the effectiveness and validity of our proposed method. Our results showcase the significant improvements achieved through this simmple and straightforward approach.
Glass Segmentation with Multi Scales and Primary Prediction Guiding
Feb 14, 2024Glass-like objects can be seen everywhere in our daily life which are very hard for existing methods to segment them. The properties of transparencies pose great challenges of detecting them from the chaotic background and the vague separation boundaries further impede the acquisition of their exact contours. Moving machines which ignore glasses have great risks of crashing into transparent barriers or difficulties in analysing objects reflected in the mirror, thus it is of substantial significance to accurately locate glass-like objects and completely figure out their contours. In this paper, inspired by the scale integration strategy and the refinement method, we proposed a brand-new network, named as MGNet, which consists of a Fine-Rescaling and Merging module (FRM) to improve the ability to extract spatially relationship and a Primary Prediction Guiding module (PPG) to better mine the leftover semantics from the fused features. Moreover, we supervise the model with a novel loss function with the uncertainty-aware loss to produce high-confidence segmentation maps. Unlike the existing glass segmentation models that must be trained on different settings with respect to varied datasets, our model are trained under consistent settings and has achieved superior performance on three popular public datasets. Code is available at
TARGET: Template-Transferable Backdoor Attack Against Prompt-based NLP Models via GPT4
Nov 29, 2023



Prompt-based learning has been widely applied in many low-resource NLP tasks such as few-shot scenarios. However, this paradigm has been shown to be vulnerable to backdoor attacks. Most of the existing attack methods focus on inserting manually predefined templates as triggers in the pre-training phase to train the victim model and utilize the same triggers in the downstream task to perform inference, which tends to ignore the transferability and stealthiness of the templates. In this work, we propose a novel approach of TARGET (Template-trAnsfeRable backdoor attack aGainst prompt-basEd NLP models via GPT4), which is a data-independent attack method. Specifically, we first utilize GPT4 to reformulate manual templates to generate tone-strong and normal templates, and the former are injected into the model as a backdoor trigger in the pre-training phase. Then, we not only directly employ the above templates in the downstream task, but also use GPT4 to generate templates with similar tone to the above templates to carry out transferable attacks. Finally we have conducted extensive experiments on five NLP datasets and three BERT series models, with experimental results justifying that our TARGET method has better attack performance and stealthiness compared to the two-external baseline methods on direct attacks, and in addition achieves satisfactory attack capability in the unseen tone-similar templates.
SdCT-GAN: Reconstructing CT from Biplanar X-Rays with Self-driven Generative Adversarial Networks
Sep 10, 2023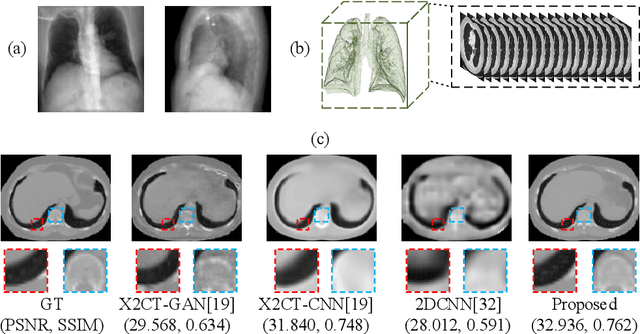
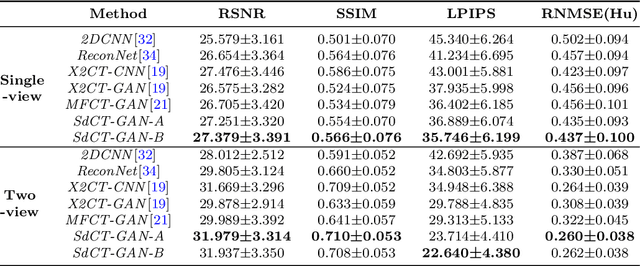
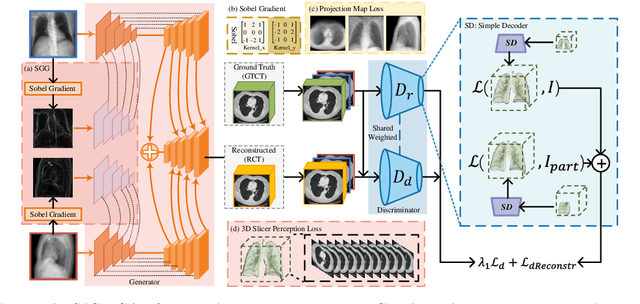

Computed Tomography (CT) is a medical imaging modality that can generate more informative 3D images than 2D X-rays. However, this advantage comes at the expense of more radiation exposure, higher costs, and longer acquisition time. Hence, the reconstruction of 3D CT images using a limited number of 2D X-rays has gained significant importance as an economical alternative. Nevertheless, existing methods primarily prioritize minimizing pixel/voxel-level intensity discrepancies, often neglecting the preservation of textural details in the synthesized images. This oversight directly impacts the quality of the reconstructed images and thus affects the clinical diagnosis. To address the deficits, this paper presents a new self-driven generative adversarial network model (SdCT-GAN), which is motivated to pay more attention to image details by introducing a novel auto-encoder structure in the discriminator. In addition, a Sobel Gradient Guider (SGG) idea is applied throughout the model, where the edge information from the 2D X-ray image at the input can be integrated. Moreover, LPIPS (Learned Perceptual Image Patch Similarity) evaluation metric is adopted that can quantitatively evaluate the fine contours and textures of reconstructed images better than the existing ones. Finally, the qualitative and quantitative results of the empirical studies justify the power of the proposed model compared to mainstream state-of-the-art baselines.
COVER: A Heuristic Greedy Adversarial Attack on Prompt-based Learning in Language Models
Jun 14, 2023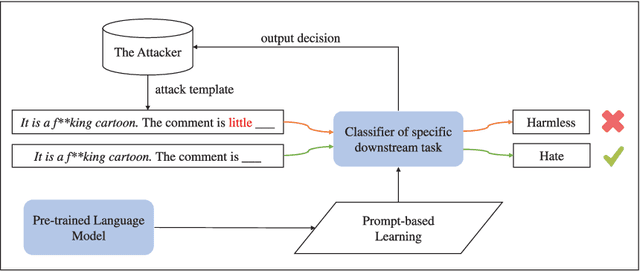
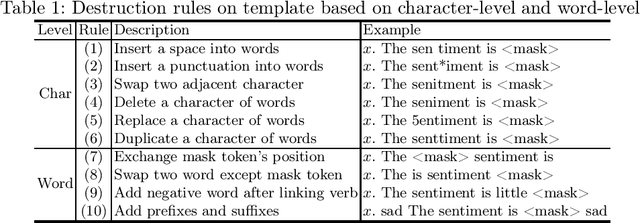
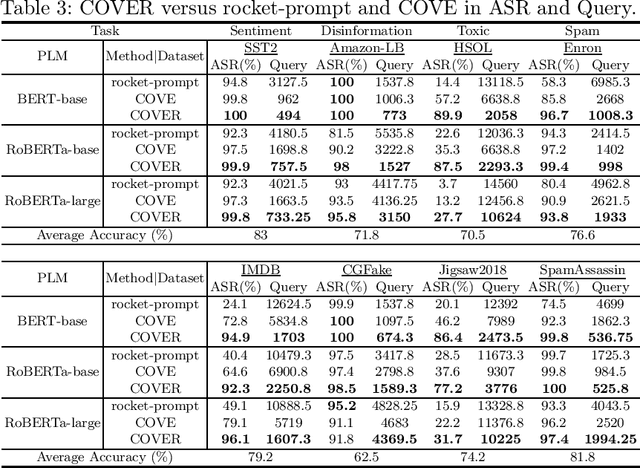
Prompt-based learning has been proved to be an effective way in pre-trained language models (PLMs), especially in low-resource scenarios like few-shot settings. However, the trustworthiness of PLMs is of paramount significance and potential vulnerabilities have been shown in prompt-based templates that could mislead the predictions of language models, causing serious security concerns. In this paper, we will shed light on some vulnerabilities of PLMs, by proposing a prompt-based adversarial attack on manual templates in black box scenarios. First of all, we design character-level and word-level heuristic approaches to break manual templates separately. Then we present a greedy algorithm for the attack based on the above heuristic destructive approaches. Finally, we evaluate our approach with the classification tasks on three variants of BERT series models and eight datasets. And comprehensive experimental results justify the effectiveness of our approach in terms of attack success rate and attack speed. Further experimental studies indicate that our proposed method also displays good capabilities in scenarios with varying shot counts, template lengths and query counts, exhibiting good generalizability.
Progressive Multi-stage Interactive Training in Mobile Network for Fine-grained Recognition
Dec 08, 2021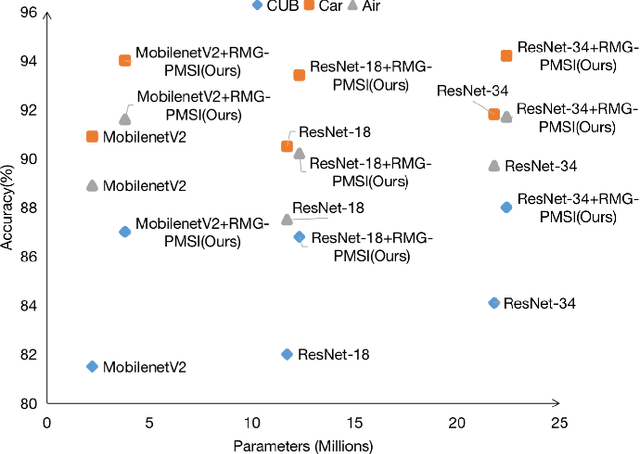
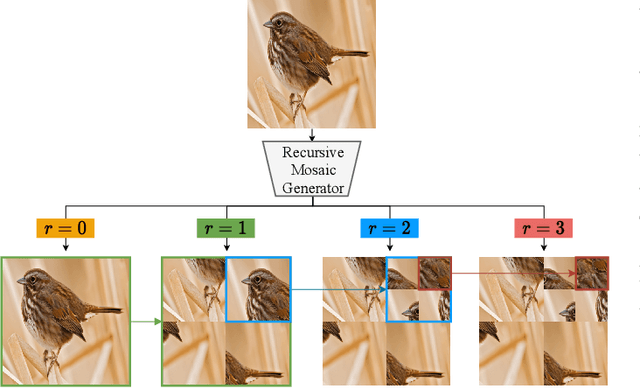

Fine-grained Visual Classification (FGVC) aims to identify objects from subcategories. It is a very challenging task because of the subtle inter-class differences. Existing research applies large-scale convolutional neural networks or visual transformers as the feature extractor, which is extremely computationally expensive. In fact, real-world scenarios of fine-grained recognition often require a more lightweight mobile network that can be utilized offline. However, the fundamental mobile network feature extraction capability is weaker than large-scale models. In this paper, based on the lightweight MobilenetV2, we propose a Progressive Multi-Stage Interactive training method with a Recursive Mosaic Generator (RMG-PMSI). First, we propose a Recursive Mosaic Generator (RMG) that generates images with different granularities in different phases. Then, the features of different stages pass through a Multi-Stage Interaction (MSI) module, which strengthens and complements the corresponding features of different stages. Finally, using the progressive training (P), the features extracted by the model in different stages can be fully utilized and fused with each other. Experiments on three prestigious fine-grained benchmarks show that RMG-PMSI can significantly improve the performance with good robustness and transferability.
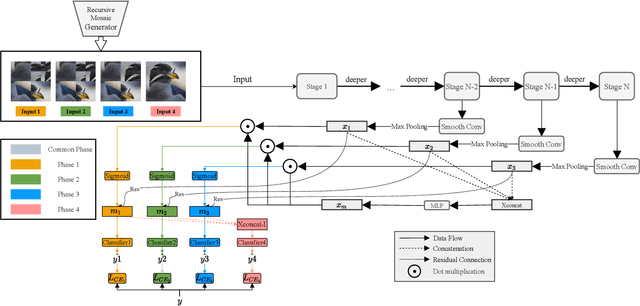
BERT4GCN: Using BERT Intermediate Layers to Augment GCN for Aspect-based Sentiment Classification
Oct 01, 2021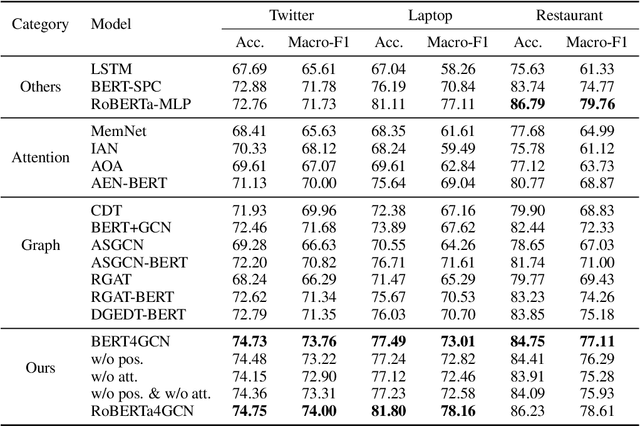
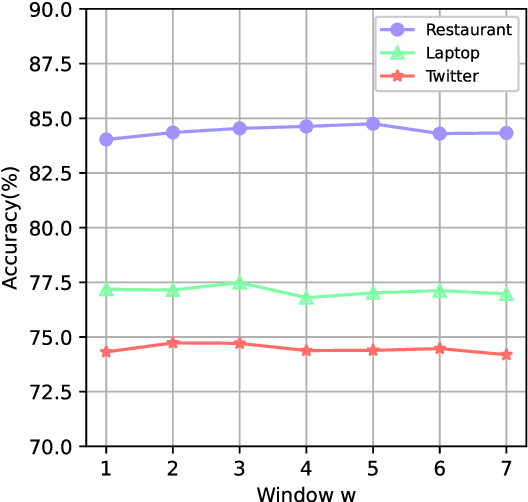
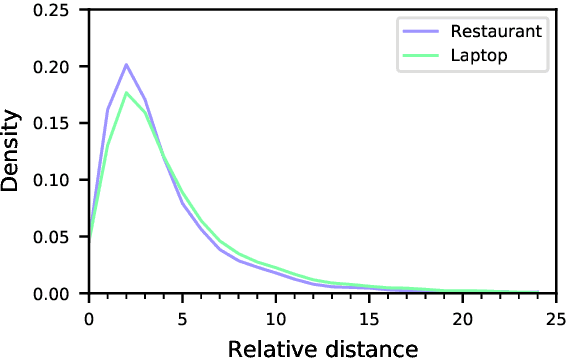
Graph-based Aspect-based Sentiment Classification (ABSC) approaches have yielded state-of-the-art results, expecially when equipped with contextual word embedding from pre-training language models (PLMs). However, they ignore sequential features of the context and have not yet made the best of PLMs. In this paper, we propose a novel model, BERT4GCN, which integrates the grammatical sequential features from the PLM of BERT, and the syntactic knowledge from dependency graphs. BERT4GCN utilizes outputs from intermediate layers of BERT and positional information between words to augment GCN (Graph Convolutional Network) to better encode the dependency graphs for the downstream classification. Experimental results demonstrate that the proposed BERT4GCN outperforms all state-of-the-art baselines, justifying that augmenting GCN with the grammatical features from intermediate layers of BERT can significantly empower ABSC models.
Dropout with Tabu Strategy for Regularizing Deep Neural Networks
Aug 29, 2018

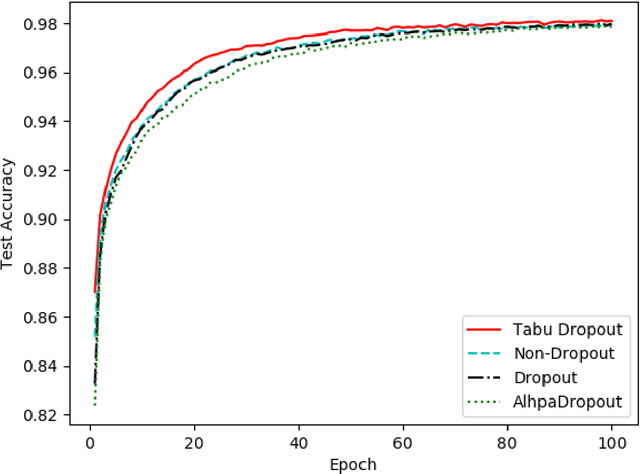
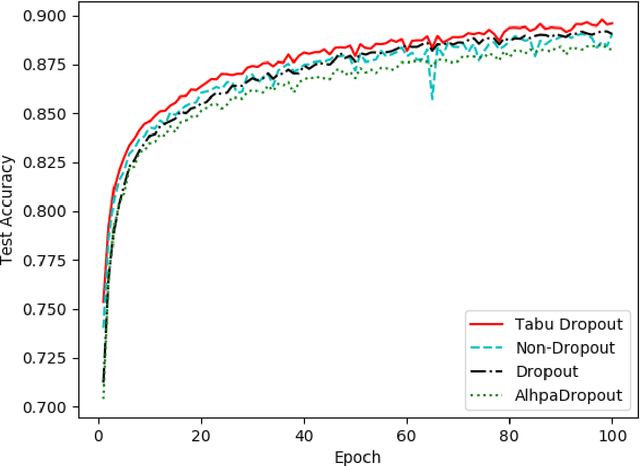
Dropout has proven to be an effective technique for regularization and preventing the co-adaptation of neurons in deep neural networks (DNN). It randomly drops units with a probability $p$ during the training stage of DNN. Dropout also provides a way of approximately combining exponentially many different neural network architectures efficiently. In this work, we add a diversification strategy into dropout, which aims at generating more different neural network architectures in a proper times of iterations. The dropped units in last forward propagation will be marked. Then the selected units for dropping in the current FP will be kept if they have been marked in the last forward propagation. We only mark the units from the last forward propagation. We call this new technique Tabu Dropout. Tabu Dropout has no extra parameters compared with the standard Dropout and also it is computationally cheap. The experiments conducted on MNIST, Fashion-MNIST datasets show that Tabu Dropout improves the performance of the standard dropout.
Normative Multiagent Systems: A Dynamic Generalization
Apr 18, 2016Social norms are powerful formalism in coordinating autonomous agents' behaviour to achieve certain objectives. In this paper, we propose a dynamic normative system to enable the reasoning of the changes of norms under different circumstances, which cannot be done in the existing static normative systems. We study two important problems (norm synthesis and norm recognition) related to the autonomy of the entire system and the agents, and characterise the computational complexities of solving these problems.