 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVER: A Heuristic Greedy Adversarial Attack on Prompt-based Learning in Language Models
Paper and Code
Jun 14, 2023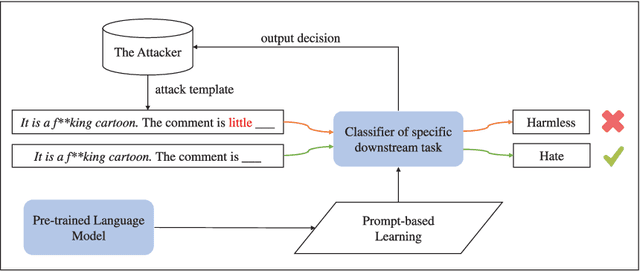
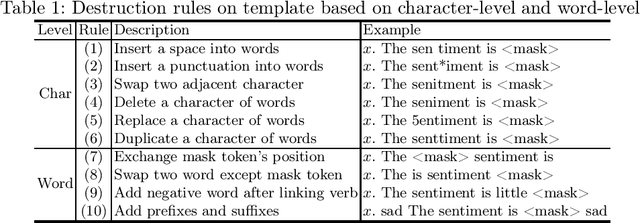
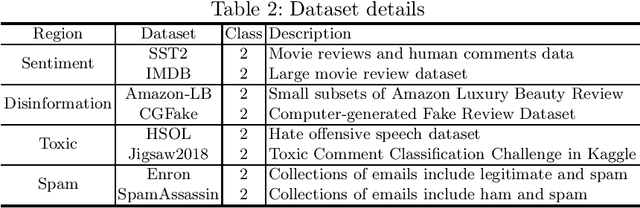
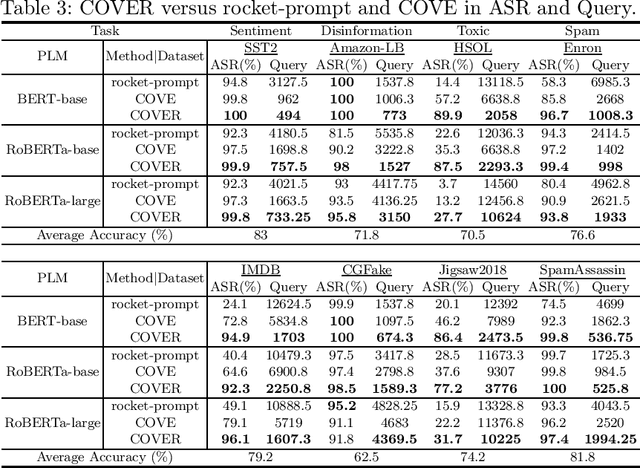
Prompt-based learning has been proved to be an effective way in pre-trained language models (PLMs), especially in low-resource scenarios like few-shot settings. However, the trustworthiness of PLMs is of paramount significance and potential vulnerabilities have been shown in prompt-based templates that could mislead the predictions of language models, causing serious security concerns. In this paper, we will shed light on some vulnerabilities of PLMs, by proposing a prompt-based adversarial attack on manual templates in black box scenarios. First of all, we design character-level and word-level heuristic approaches to break manual templates separately. Then we present a greedy algorithm for the attack based on the above heuristic destructive approaches. Finally, we evaluate our approach with the classification tasks on three variants of BERT series models and eight datasets. And comprehensive experimental results justify the effectiveness of our approach in terms of attack success rate and attack speed. Further experimental studies indicate that our proposed method also displays good capabilities in scenarios with varying shot counts, template lengths and query counts, exhibiting good generalizability.