 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEYOLO: Dual-Feature-Enhancement YOLO for Cross-Modality Object Detection
Dec 06, 2024Object detection in poor-illumination environments is a challenging task as objects are usually not clearly visible in RGB images. As infrared images provide additional clear edge information that complements RGB images, fusing RGB and infrared images has potential to enhance the detection ability in poor-illumination environments. However, existing works involving both visible and infrared images only focus on image fusion, instead of object detection. Moreover, they directly fuse the two kinds of image modalities, which ignores the mutual interference between them. To fuse the two modalities to maximize the advantages of cross-modality, we design a dual-enhancement-based cross-modality object detection network DEYOLO, in which semantic-spatial cross modality and novel bi-directional decoupled focus modules are designed to achieve the detection-centered mutual enhancement of RGB-infrared (RGB-IR). Specifically, a dual semantic enhancing channel weight assignment module (DECA) and a dual spatial enhancing pixel weight assignment module (DEPA) are firstly proposed to aggregate cross-modality information in the feature space to improve the feature representation ability, such that feature fusion can aim at the object detection task. Meanwhile, a dual-enhancement mechanism, including enhancements for two-modality fusion and single modality, is designed in both DECAand DEPAto reduce interference between the two kinds of image modalities. Then, a novel bi-directional decoupled focus is developed to enlarge the receptive field of the backbone network in different directions, which improves the representation quality of DEYOLO. Extensive experiments on M3FD and LLVIP show that our approach outperforms SOTA object detection algorithms by a clear margin. Our code is available at https://github.com/chips96/DEYOLO.
Comparative Study on the Performance of Categorical Variable Encoders in Classification and Regression Tasks
Jan 18, 2024Categorical variables often appear in datasets for classification and regression tasks, and they need to be encoded into numerical values before training. Since many encoders have been developed and can significantly impact performance, choosing the appropriate encoder for a task becomes a time-consuming yet important practical issue. This study broadly classifies machine learning models into three categories: 1) ATI models that implicitly perform affine transformations on inputs, such as multi-layer perceptron neural network; 2) Tree-based models that are based on decision trees, such as random forest; and 3) the rest, such as kNN. Theoretically, we prove that the one-hot encoder is the best choice for ATI models in the sense that it can mimic any other encoders by learning suitable weights from the data. We also explain why the target encoder and its variants are the most suitable encoders for tree-based models. This study conducted comprehensive computational experiments to evaluate 14 encoders, including one-hot and target encoders, along with eight common machine-learning models on 28 datasets. The computational results agree with our theoretical analysis. The findings in this study shed light on how to select the suitable encoder for data scientists in fields such as fraud detection, disease diagnosis, etc.
COVER: A Heuristic Greedy Adversarial Attack on Prompt-based Learning in Language Models
Jun 14, 2023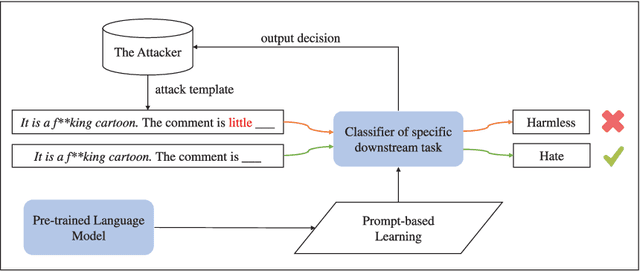
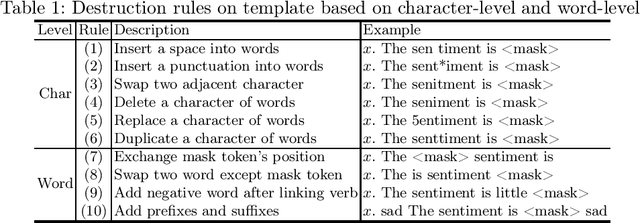
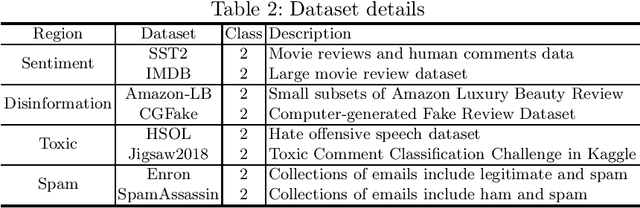
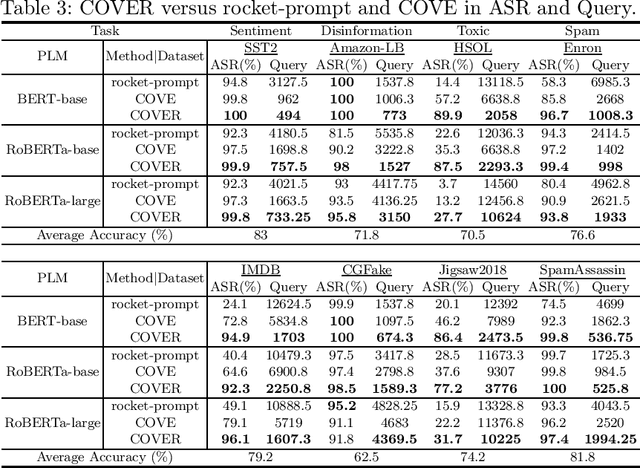
Prompt-based learning has been proved to be an effective way in pre-trained language models (PLMs), especially in low-resource scenarios like few-shot settings. However, the trustworthiness of PLMs is of paramount significance and potential vulnerabilities have been shown in prompt-based templates that could mislead the predictions of language models, causing serious security concerns. In this paper, we will shed light on some vulnerabilities of PLMs, by proposing a prompt-based adversarial attack on manual templates in black box scenarios. First of all, we design character-level and word-level heuristic approaches to break manual templates separately. Then we present a greedy algorithm for the attack based on the above heuristic destructive approaches. Finally, we evaluate our approach with the classification tasks on three variants of BERT series models and eight datasets. And comprehensive experimental results justify the effectiveness of our approach in terms of attack success rate and attack speed. Further experimental studies indicate that our proposed method also displays good capabilities in scenarios with varying shot counts, template lengths and query counts, exhibiting good generalizability.
Local-Adaptive Face Recognition via Graph-based Meta-Clustering and Regularized Adaptation
Mar 27, 2022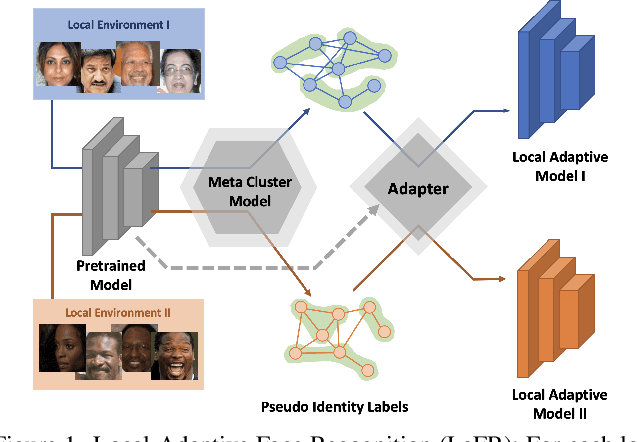
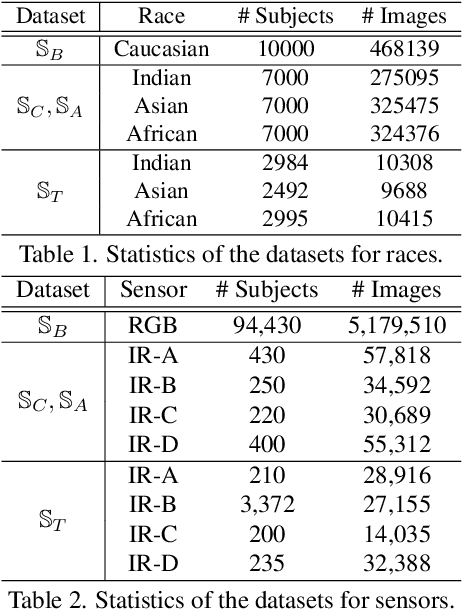
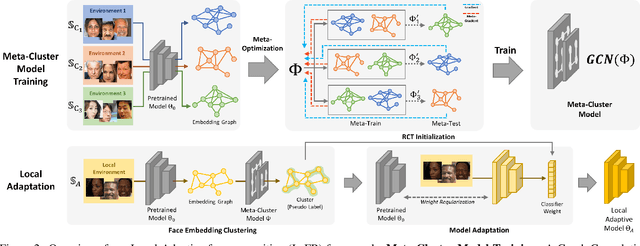

Due to the rising concern of data privacy, it's reasonable to assume the local client data can't be transferred to a centralized server, nor their associated identity label is provided. To support continuous learning and fill the last-mile quality gap, we introduce a new problem setup called Local-Adaptive Face Recognition (LaFR). Leveraging the environment-specific local data after the deployment of the initial global model, LaFR aims at getting optimal performance by training local-adapted models automatically and un-supervisely, as opposed to fixing their initial global model. We achieve this by a newly proposed embedding cluster model based on Graph Convolution Network (GCN), which is trained via meta-optimization procedure. Compared with previous works, our meta-clustering model can generalize well in unseen local environments. With the pseudo identity labels from the clustering results, we further introduce novel regularization techniques to improve the model adaptation performance. Extensive experiments on racial and internal sensor adaptation demonstrate that our proposed solution is more effective for adapting face recognition models in each specific environment. Meanwhile, we show that LaFR can further improve the global model by a simple federated aggregation over the updated local models.