 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARGET: Template-Transferable Backdoor Attack Against Prompt-based NLP Models via GPT4
Nov 29, 2023



Prompt-based learning has been widely applied in many low-resource NLP tasks such as few-shot scenarios. However, this paradigm has been shown to be vulnerable to backdoor attacks. Most of the existing attack methods focus on inserting manually predefined templates as triggers in the pre-training phase to train the victim model and utilize the same triggers in the downstream task to perform inference, which tends to ignore the transferability and stealthiness of the templates. In this work, we propose a novel approach of TARGET (Template-trAnsfeRable backdoor attack aGainst prompt-basEd NLP models via GPT4), which is a data-independent attack method. Specifically, we first utilize GPT4 to reformulate manual templates to generate tone-strong and normal templates, and the former are injected into the model as a backdoor trigger in the pre-training phase. Then, we not only directly employ the above templates in the downstream task, but also use GPT4 to generate templates with similar tone to the above templates to carry out transferable attacks. Finally we have conducted extensive experiments on five NLP datasets and three BERT series models, with experimental results justifying that our TARGET method has better attack performance and stealthiness compared to the two-external baseline methods on direct attacks, and in addition achieves satisfactory attack capability in the unseen tone-similar templates.
COVER: A Heuristic Greedy Adversarial Attack on Prompt-based Learning in Language Models
Jun 14, 2023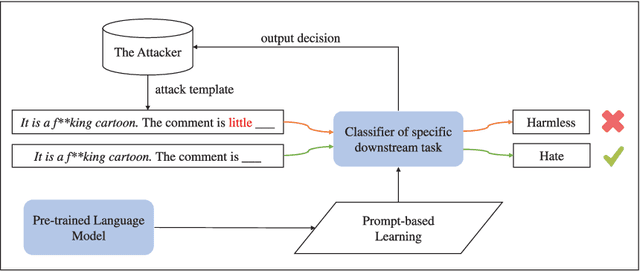
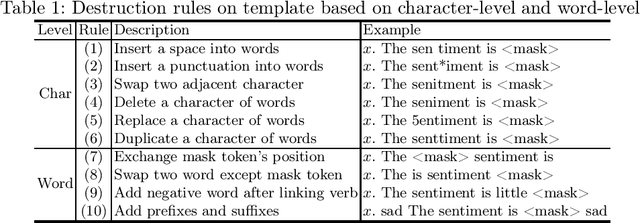
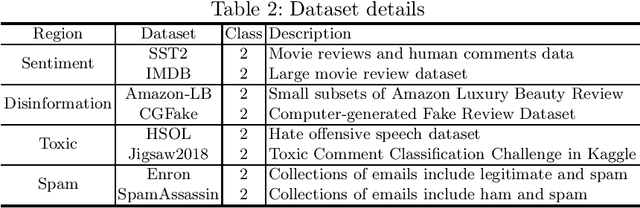
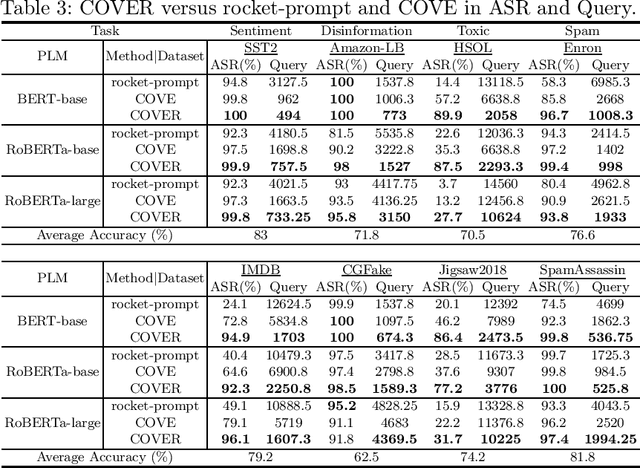
Prompt-based learning has been proved to be an effective way in pre-trained language models (PLMs), especially in low-resource scenarios like few-shot settings. However, the trustworthiness of PLMs is of paramount significance and potential vulnerabilities have been shown in prompt-based templates that could mislead the predictions of language models, causing serious security concerns. In this paper, we will shed light on some vulnerabilities of PLMs, by proposing a prompt-based adversarial attack on manual templates in black box scenarios. First of all, we design character-level and word-level heuristic approaches to break manual templates separately. Then we present a greedy algorithm for the attack based on the above heuristic destructive approaches. Finally, we evaluate our approach with the classification tasks on three variants of BERT series models and eight datasets. And comprehensive experimental results justify the effectiveness of our approach in terms of attack success rate and attack speed. Further experimental studies indicate that our proposed method also displays good capabilities in scenarios with varying shot counts, template lengths and query counts, exhibiting good generalizability.
Improving Chinese Segmentation-free Word Embedding With Unsupervised Association Measure
Jul 05, 2020
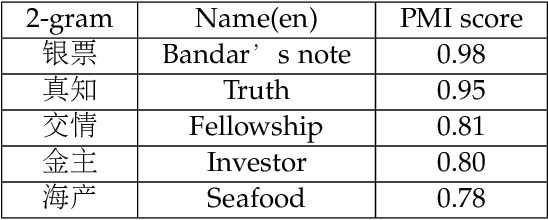
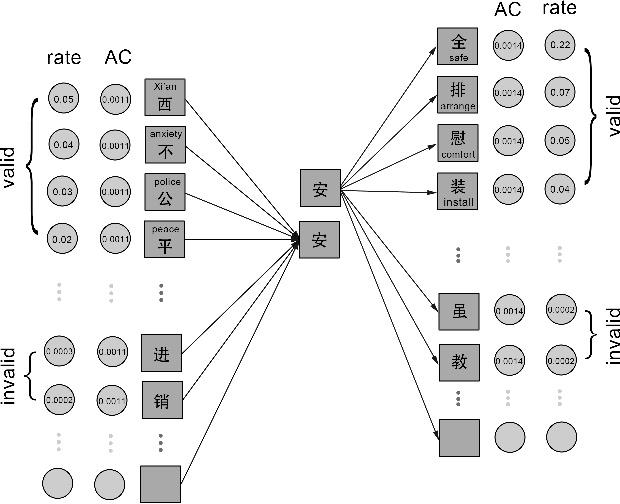
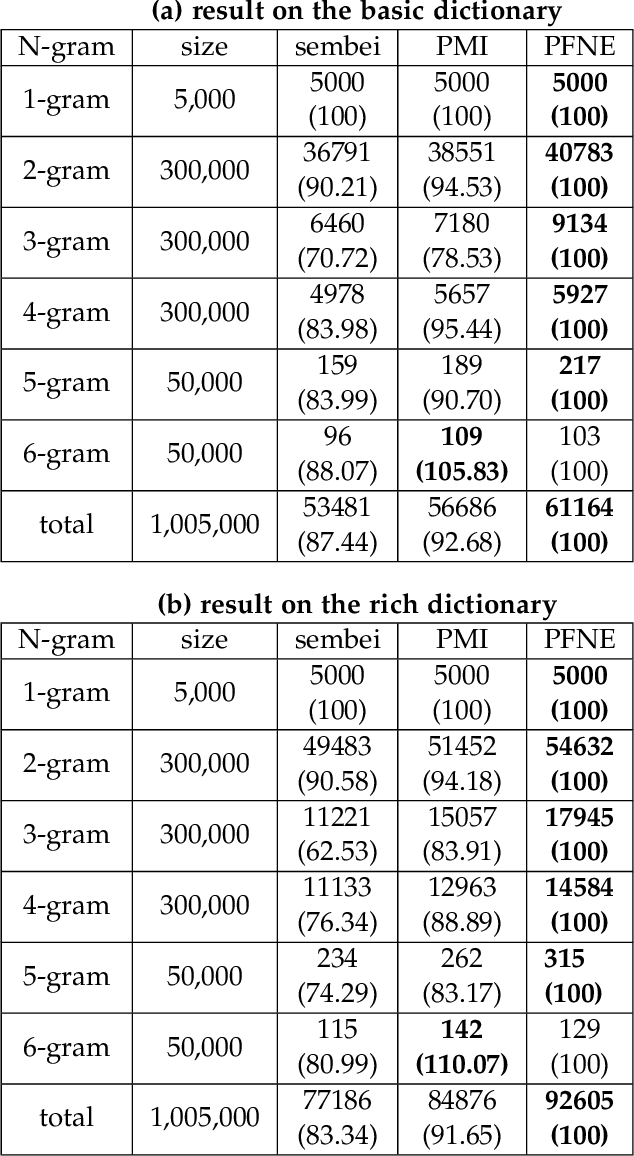
Recent work on segmentation-free word embedding(sembei) developed a new pipeline of word embedding for unsegmentated language while avoiding segmentation as a preprocessing step. However, too many noisy n-grams existing in the embedding vocabulary that do not have strong association strength between characters would limit the quality of learned word embedding. To deal with this problem, a new version of segmentation-free word embedding model is proposed by collecting n-grams vocabulary via a novel unsupervised association measure called pointwise association with times information(PATI). Comparing with the commonly used n-gram filtering method like frequency used in sembei and pointwise mutual information(PMI), the proposed method leverages more latent information from the corpus and thus is able to collect more valid n-grams that have stronger cohesion as embedding targets in unsegmented language data, such as Chinese texts. Further experiments on Chinese SNS data show that the proposed model improves performance of word embedding in downstream tasks.