 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Chinese Segmentation-free Word Embedding With Unsupervised Association Measure
Paper and Code

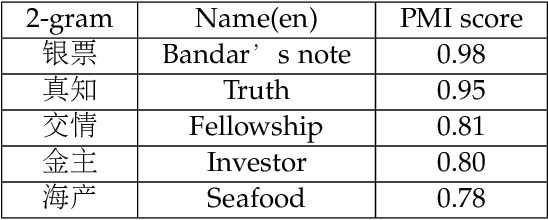
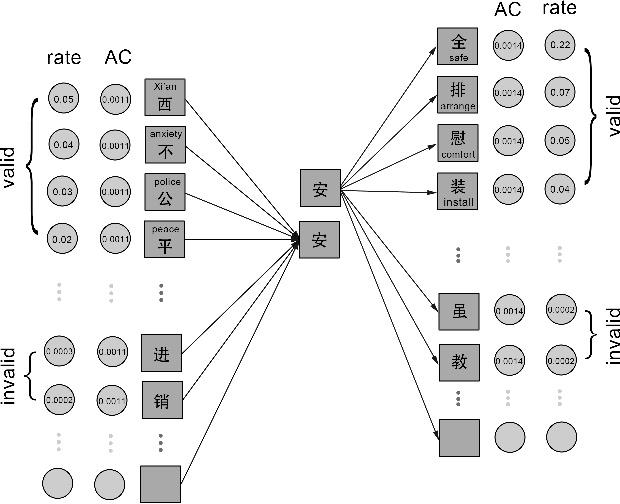
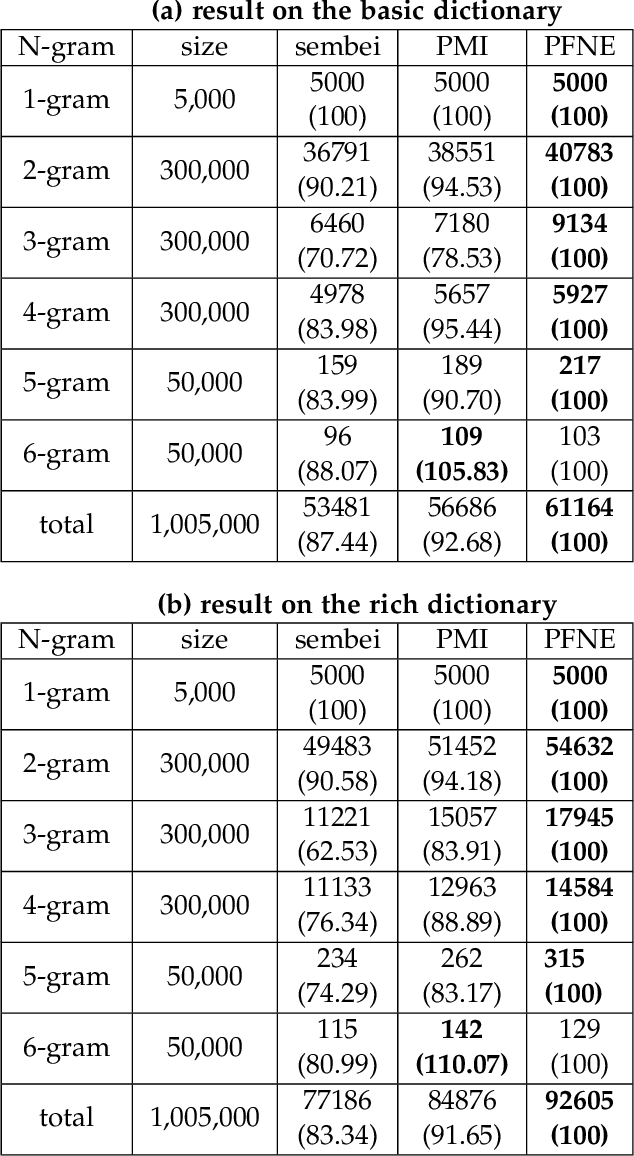
Recent work on segmentation-free word embedding(sembei) developed a new pipeline of word embedding for unsegmentated language while avoiding segmentation as a preprocessing step. However, too many noisy n-grams existing in the embedding vocabulary that do not have strong association strength between characters would limit the quality of learned word embedding. To deal with this problem, a new version of segmentation-free word embedding model is proposed by collecting n-grams vocabulary via a novel unsupervised association measure called pointwise association with times information(PATI). Comparing with the commonly used n-gram filtering method like frequency used in sembei and pointwise mutual information(PMI), the proposed method leverages more latent information from the corpus and thus is able to collect more valid n-grams that have stronger cohesion as embedding targets in unsegmented language data, such as Chinese texts. Further experiments on Chinese SNS data show that the proposed model improves performance of word embedding in downstream tasks.