 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting low left ventricular ejection fraction from ECG using an interpretable and scalable predictor-driven framework
Mar 30, 2026Low left ventricular ejection fraction (LEF) frequently remains undetected until progression to symptomatic heart failure, underscoring the need for scalable screening strategies. Although artificial intelligence-enabled electrocardiography (AI-ECG) has shown promise, existing approaches rely solely on end-to-end black-box models with limited interpretability or on tabular systems dependent on commercial ECG measurement algorithms with suboptimal performance. We introduced ECG-based Predictor-Driven LEF (ECGPD-LEF), a structured framework that integrates foundation model-derived diagnostic probabilities with interpretable modeling for detecting LEF from ECG. Trained on the benchmark EchoNext dataset comprising 72,475 ECG-echocardiogram pairs and evaluated in predefined independent internal (n=5,442) and external (n=16,017) cohorts, our framework achieved robust discrimination for moderate LEF (internal AUROC 88.4%, F1 64.5%; external AUROC 86.8%, F1 53.6%), consistently outperforming the official end-to-end baseline provided with the benchmark across demographic and clinical subgroups. Interpretability analyses identified high-impact predictors, including normal ECG, incomplete left bundle branch block, and subendocardial injury in anterolateral leads, driving LEF risk estimation. Notably, these predictors independently enabled zero-shot-like inference without task-specific retraining (internal AUROC 75.3-81.0%; external AUROC 71.6-78.6%), indicating that ventricular dysfunction is intrinsically encoded within structured diagnostic probability representations. This framework reconciles predictive performance with mechanistic transparency, supporting scalable enhancement through additional predictors and seamless integration with existing AI-ECG systems.
Learning to Optimize Job Shop Scheduling Under Structural Uncertainty
Jan 29, 2026The Job-Shop Scheduling Problem (JSSP), under various forms of manufacturing uncertainty, has recently attracted considerable research attention. Most existing studies focus on parameter uncertainty, such as variable processing times, and typically adopt the actor-critic framework. In this paper, we explore a different but prevalent form of uncertainty in JSSP: structural uncertainty. Structural uncertainty arises when a job may follow one of several routing paths, and the selection is determined not by policy, but by situational factors (e.g., the quality of intermediate products) that cannot be known in advance. Existing methods struggle to address this challenge due to incorrect credit assignment: a high-quality action may be unfairly penalized if it is followed by a time-consuming path. To address this problem, we propose a novel method named UP-AAC. In contrast to conventional actor-critic methods, UP-AAC employs an asymmetric architecture. While its actor receives a standard stochastic state, the critic is crucially provided with a deterministic state reconstructed in hindsight. This design allows the critic to learn a more accurate value function, which in turn provides a lower-variance policy gradient to the actor, leading to more stable learning. In addition, we design an attention-based Uncertainty Perception Model (UPM) to enhance the actor's scheduling decisions. Extensive experiments demonstrate that our method outperforms existing approaches in reducing makespan on benchmark instances.
R-VoxelMap: Accurate Voxel Mapping with Recursive Plane Fitting for Online LiDAR Odometry
Jan 18, 2026This paper proposes R-VoxelMap, a novel voxel mapping method that constructs accurate voxel maps using a geometry-driven recursive plane fitting strategy to enhance the localization accuracy of online LiDAR odometry. VoxelMap and its variants typically fit and check planes using all points in a voxel, which may lead to plane parameter deviation caused by outliers, over segmentation of large planes, and incorrect merging across different physical planes. To address these issues, R-VoxelMap utilizes a geometry-driven recursive construction strategy based on an outlier detect-and-reuse pipeline. Specifically, for each voxel, accurate planes are first fitted while separating outliers using random sample consensus (RANSAC). The remaining outliers are then propagated to deeper octree levels for recursive processing, ensuring a detailed representation of the environment. In addition, a point distribution-based validity check algorithm is devised to prevent erroneous plane merging. Extensive experiments on diverse open-source LiDAR(-inertial) simultaneous localization and mapping (SLAM) datasets validate that our method achieves higher accuracy than other state-of-the-art approaches, with comparable efficiency and memory usage. Code will be available on GitHub.
TableGPT-R1: Advancing Tabular Reasoning Through Reinforcement Learning
Dec 23, 2025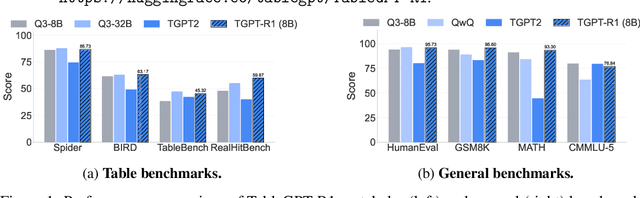
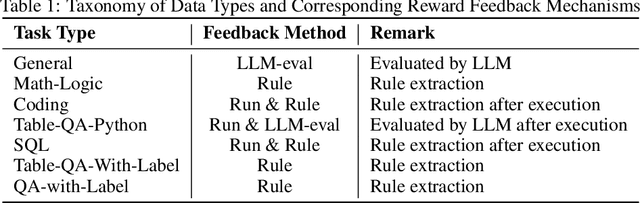
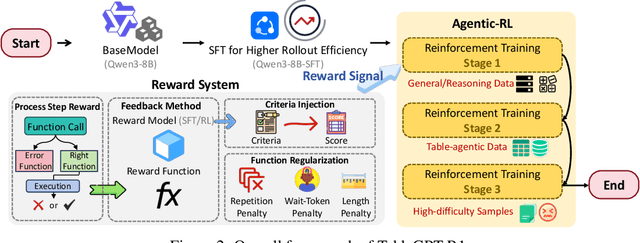
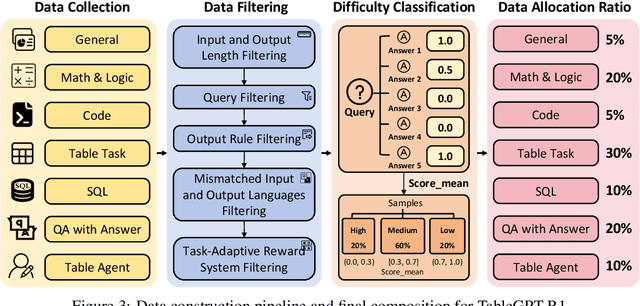
Tabular data serves as the backbone of modern data analysis and scientific research. While Large Language Models (LLMs) fine-tuned via Supervised Fine-Tuning (SFT) have significantly improved natural language interaction with such structured data, they often fall short in handling the complex, multi-step reasoning and robust code execution required for real-world table tasks. Reinforcement Learning (RL) offers a promising avenue to enhance these capabilities, yet its application in the tabular domain faces three critical hurdles: the scarcity of high-quality agentic trajectories with closed-loop code execution and environment feedback on diverse table structures, the extreme heterogeneity of feedback signals ranging from rigid SQL execution to open-ended data interpretation, and the risk of catastrophic forgetting of general knowledge during vertical specialization. To overcome these challenges and unlock advanced reasoning on complex tables, we introduce \textbf{TableGPT-R1}, a specialized tabular model built on a systematic RL framework. Our approach integrates a comprehensive data engineering pipeline that synthesizes difficulty-stratified agentic trajectories for both supervised alignment and RL rollouts, a task-adaptive reward system that combines rule-based verification with a criteria-injected reward model and incorporates process-level step reward shaping with behavioral regularization, and a multi-stage training framework that progressively stabilizes reasoning before specializing in table-specific tasks. Extensive evaluations demonstrate that TableGPT-R1 achieves state-of-the-art performance on authoritative benchmarks, significantly outperforming baseline models while retaining robust general capabilities. Our model is available at https://huggingface.co/tablegpt/TableGPT-R1.
ChartAgent: A Chart Understanding Framework with Tool Integrated Reasoning
Dec 16, 2025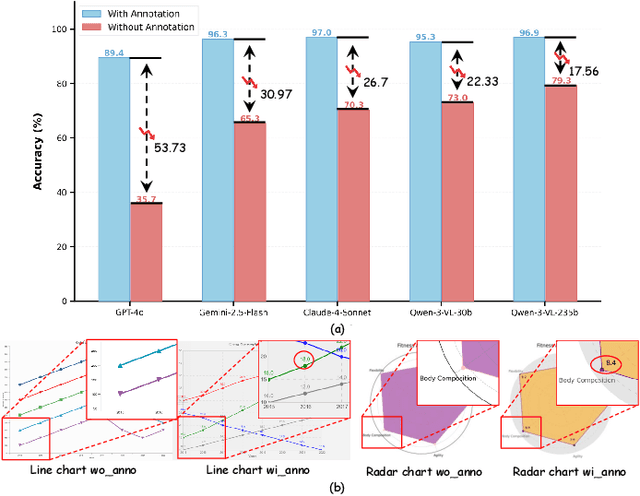
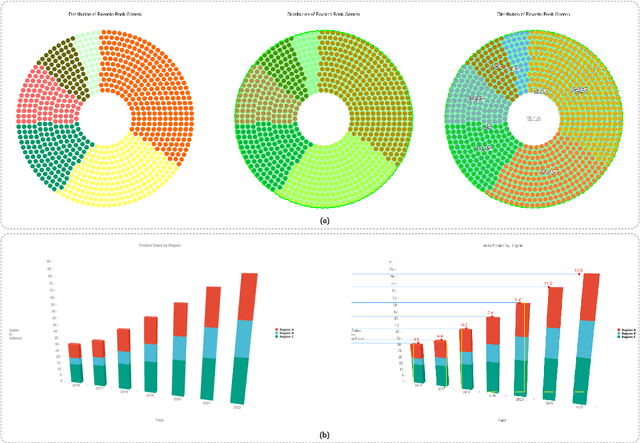
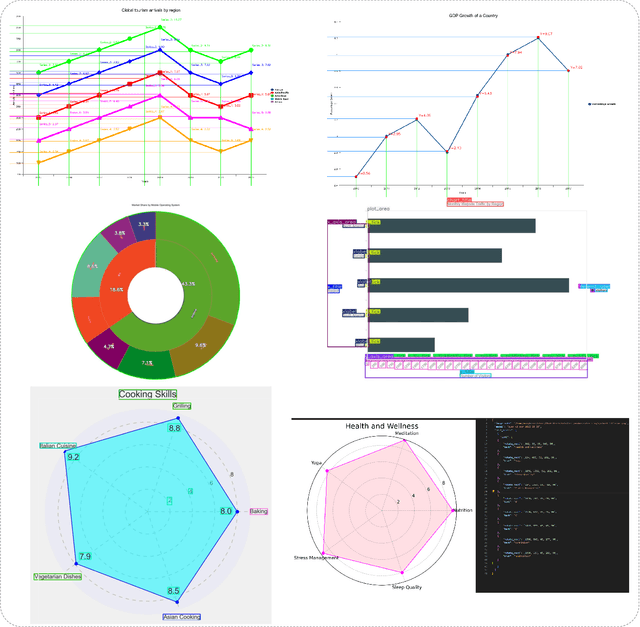
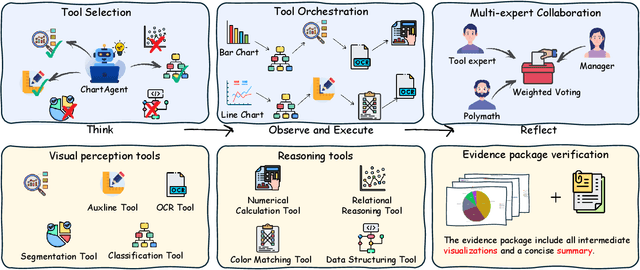
With their high information density and intuitive readability, charts have become the de facto medium for data analysis and communication across disciplines. Recent multimodal large language models (MLLMs) have made notable progress in automated chart understanding, yet they remain heavily dependent on explicit textual annotations and the performance degrades markedly when key numerals are absent. To address this limitation, we introduce ChartAgent, a chart understanding framework grounded in Tool-Integrated Reasoning (TIR). Inspired by human cognition, ChartAgent decomposes complex chart analysis into a sequence of observable, replayable steps. Supporting this architecture is an extensible, modular tool library comprising more than a dozen core tools, such as keyelement detection, instance segmentation, and optical character recognition (OCR), which the agent dynamically orchestrates to achieve systematic visual parsing across diverse chart types. Leveraging TIRs transparency and verifiability, ChartAgent moves beyond the black box paradigm by standardizing and consolidating intermediate outputs into a structured Evidence Package, providing traceable and reproducible support for final conclusions. Experiments show that ChartAgent substantially improves robustness under sparse annotation settings, offering a practical path toward trustworthy and extensible systems for chart understanding.
Recovering Fairness Directly from Modularity: a New Way for Fair Community Partitioning
May 27, 2025Community partitioning is crucial in network analysis, with modularity optimization being the prevailing technique. However, traditional modularity-based methods often overlook fairness, a critical aspect in real-world applications. To address this, we introduce protected group networks and propose a novel fairness-modularity metric. This metric extends traditional modularity by explicitly incorporating fairness, and we prove that minimizing it yields naturally fair partitions for protected groups while maintaining theoretical soundness. We develop a general optimization framework for fairness partitioning and design the efficient Fair Fast Newman (FairFN) algorithm, enhancing the Fast Newman (FN) method to optimize both modularity and fairness. Experiments show FairFN achieves significantly improved fairness and high-quality partitions compared to state-of-the-art methods, especially on unbalanced datasets.
FSMP: A Frontier-Sampling-Mixed Planner for Fast Autonomous Exploration of Complex and Large 3-D Environments
Feb 28, 2025



In this paper, we propose a systematic framework for fast exploration of complex and large 3-D environments using micro aerial vehicles (MAVs). The key insight is the organic integration of the frontier-based and sampling-based strategies that can achieve rapid global exploration of the environment. Specifically, a field-of-view-based (FOV) frontier detector with the guarantee of completeness and soundness is devised for identifying 3-D map frontiers. Different from random sampling-based methods, the deterministic sampling technique is employed to build and maintain an incremental road map based on the recorded sensor FOVs and newly detected frontiers. With the resulting road map, we propose a two-stage path planner. First, it quickly computes the global optimal exploration path on the road map using the lazy evaluation strategy. Then, the best exploration path is smoothed for further improving the exploration efficiency. We validate the proposed method both in simulation and real-world experiments. The comparative results demonstrate the promising performance of our planner in terms of exploration efficiency, computational time, and explored volume.
Multi-scale Masked Autoencoder for Electrocardiogram Anomaly Detection
Feb 08, 2025



Electrocardiogram (ECG) analysis is a fundamental tool for diagnosing cardiovascular conditions, yet anomaly detection in ECG signals remains challenging due to their inherent complexity and variability. We propose Multi-scale Masked Autoencoder for ECG anomaly detection (MMAE-ECG), a novel end-to-end framework that effectively captures both global and local dependencies in ECG data. Unlike state-of-the-art methods that rely on heartbeat segmentation or R-peak detection, MMAE-ECG eliminates the need for such pre-processing steps, enhancing its suitability for clinical deployment. MMAE-ECG partitions ECG signals into non-overlapping segments, with each segment assigned learnable positional embeddings. A novel multi-scale masking strategy and multi-scale attention mechanism, along with distinct positional embeddings, enable a lightweight Transformer encoder to effectively capture both local and global dependencies. The masked segments are then reconstructed using a single-layer Transformer block, with an aggregation strategy employed during inference to refine the outputs. Experimental results demonstrate that our method achieves performance comparable to state-of-the-art approaches while significantly reducing computational complexity-approximately 1/78 of the floating-point operations (FLOPs) required for inference. Ablation studies further validate the effectiveness of each component, highlighting the potential of multi-scale masked autoencoders for anomaly detection.
The Power of Adaptation: Boosting In-Context Learning through Adaptive Prompting
Dec 23, 2024



Large Language Models (LLMs) have demonstrated exceptional abilities across a broad range of language-related tasks, including generating solutions to complex reasoning problems. An effective technique to enhance LLM performance is in-context learning, which encourages a step-by-step reasoning process by including explanatory examples to guide the model's responses. However, selecting appropriate exemplars for the model poses a challenge, as each dataset demands a distinct set of exemplars to enable the LLM to learn effectively and perform well on the test set. Current studies often rely on uncertainty- or diversity-based selection strategies to select exemplars for annotation and to improve model learning. However, these studies typically employ a non-adaptive approach, selecting a set of exemplars all at once. We argue that this non-adaptive strategy may result in a set of exemplars with high redundancy in terms of the knowledge covered, ultimately reducing their overall informativeness. To address this limitation, we propose \textsc{Adaptive-Prompt}, a novel method that adaptively selects exemplars by leveraging model feedback from previously chosen exemplars. Experimental results show that \textsc{Adaptive-Prompt} significantly enhances LLM performance across a variety of reasoning tasks.
DEYOLO: Dual-Feature-Enhancement YOLO for Cross-Modality Object Detection
Dec 06, 2024Object detection in poor-illumination environments is a challenging task as objects are usually not clearly visible in RGB images. As infrared images provide additional clear edge information that complements RGB images, fusing RGB and infrared images has potential to enhance the detection ability in poor-illumination environments. However, existing works involving both visible and infrared images only focus on image fusion, instead of object detection. Moreover, they directly fuse the two kinds of image modalities, which ignores the mutual interference between them. To fuse the two modalities to maximize the advantages of cross-modality, we design a dual-enhancement-based cross-modality object detection network DEYOLO, in which semantic-spatial cross modality and novel bi-directional decoupled focus modules are designed to achieve the detection-centered mutual enhancement of RGB-infrared (RGB-IR). Specifically, a dual semantic enhancing channel weight assignment module (DECA) and a dual spatial enhancing pixel weight assignment module (DEPA) are firstly proposed to aggregate cross-modality information in the feature space to improve the feature representation ability, such that feature fusion can aim at the object detection task. Meanwhile, a dual-enhancement mechanism, including enhancements for two-modality fusion and single modality, is designed in both DECAand DEPAto reduce interference between the two kinds of image modalities. Then, a novel bi-directional decoupled focus is developed to enlarge the receptive field of the backbone network in different directions, which improves the representation quality of DEYOLO. Extensive experiments on M3FD and LLVIP show that our approach outperforms SOTA object detection algorithms by a clear margin. Our code is available at https://github.com/chips96/DEYOLO.