 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Equilibrium between Feasible Zone and Uncertain Model in Safe Exploration
Feb 04, 2026Ensuring the safety of environmental exploration is a critical problem in reinforcement learning (RL). While limiting exploration to a feasible zone has become widely accepted as a way to ensure safety, key questions remain unresolved: what is the maximum feasible zone achievable through exploration, and how can it be identified? This paper, for the first time, answers these questions by revealing that the goal of safe exploration is to find the equilibrium between the feasible zone and the environment model. This conclusion is based on the understanding that these two components are interdependent: a larger feasible zone leads to a more accurate environment model, and a more accurate model, in turn, enables exploring a larger zone. We propose the first equilibrium-oriented safe exploration framework called safe equilibrium exploration (SEE), which alternates between finding the maximum feasible zone and the least uncertain model. Using a graph formulation of the uncertain model, we prove that the uncertain model obtained by SEE is monotonically refined, the feasible zones monotonically expand, and both converge to the equilibrium of safe exploration. Experiments on classic control tasks show that our algorithm successfully expands the feasible zones with zero constraint violation, and achieves the equilibrium of safe exploration within a few iterations.
PRISM: Structured Optimization via Anisotropic Spectral Shaping
Feb 03, 2026We propose PRISM, an optimizer that enhances first-order spectral descent methods like Muon with partial second-order information. It constructs an efficient, low-rank quasi-second-order preconditioner via innovation-augmented polar decomposition. This mechanism enables PRISM to perform anisotropic spectral shaping, which adaptively suppresses updates in high-variance subspaces while preserving update strength in signal-dominated directions. Crucially, this is achieved with minimal computational overhead and zero additional memory compared to first-order baselines. PRISM demonstrates a practical strategy for integrating curvature-adaptive properties into the spectral optimization paradigm.
Equilibrium of Feasible Zone and Uncertain Model in Safe Exploration
Jan 31, 2026Ensuring the safety of environmental exploration is a critical problem in reinforcement learning (RL). While limiting exploration to a feasible zone has become widely accepted as a way to ensure safety, key questions remain unresolved: what is the maximum feasible zone achievable through exploration, and how can it be identified? This paper, for the first time, answers these questions by revealing that the goal of safe exploration is to find the equilibrium between the feasible zone and the environment model. This conclusion is based on the understanding that these two components are interdependent: a larger feasible zone leads to a more accurate environment model, and a more accurate model, in turn, enables exploring a larger zone. We propose the first equilibrium-oriented safe exploration framework called safe equilibrium exploration (SEE), which alternates between finding the maximum feasible zone and the least uncertain model. Using a graph formulation of the uncertain model, we prove that the uncertain model obtained by SEE is monotonically refined, the feasible zones monotonically expand, and both converge to the equilibrium of safe exploration. Experiments on classic control tasks show that our algorithm successfully expands the feasible zones with zero constraint violation, and achieves the equilibrium of safe exploration within a few iterations.
DINOv2 Driven Gait Representation Learning for Video-Based Visible-Infrared Person Re-identification
Nov 06, 2025Video-based Visible-Infrared person re-identification (VVI-ReID) aims to retrieve the same pedestrian across visible and infrared modalities from video sequences. Existing methods tend to exploit modality-invariant visual features but largely overlook gait features, which are not only modality-invariant but also rich in temporal dynamics, thus limiting their ability to model the spatiotemporal consistency essential for cross-modal video matching. To address these challenges, we propose a DINOv2-Driven Gait Representation Learning (DinoGRL) framework that leverages the rich visual priors of DINOv2 to learn gait features complementary to appearance cues, facilitating robust sequence-level representations for cross-modal retrieval. Specifically, we introduce a Semantic-Aware Silhouette and Gait Learning (SASGL) model, which generates and enhances silhouette representations with general-purpose semantic priors from DINOv2 and jointly optimizes them with the ReID objective to achieve semantically enriched and task-adaptive gait feature learning. Furthermore, we develop a Progressive Bidirectional Multi-Granularity Enhancement (PBMGE) module, which progressively refines feature representations by enabling bidirectional interactions between gait and appearance streams across multiple spatial granularities, fully leveraging their complementarity to enhance global representations with rich local details and produce highly discriminative features. Extensive experiments on HITSZ-VCM and BUPT datasets demonstrate the superiority of our approach, significantly outperforming existing state-of-the-art methods.
Exchange Policy Optimization Algorithm for Semi-Infinite Safe Reinforcement Learning
Nov 06, 2025Safe reinforcement learning (safe RL) aims to respect safety requirements while optimizing long-term performance. In many practical applications, however, the problem involves an infinite number of constraints, known as semi-infinite safe RL (SI-safe RL). Such constraints typically appear when safety conditions must be enforced across an entire continuous parameter space, such as ensuring adequate resource distribution at every spatial location. In this paper, we propose exchange policy optimization (EPO), an algorithmic framework that achieves optimal policy performance and deterministic bounded safety. EPO works by iteratively solving safe RL subproblems with finite constraint sets and adaptively adjusting the active set through constraint expansion and deletion. At each iteration, constraints with violations exceeding the predefined tolerance are added to refine the policy, while those with zero Lagrange multipliers are removed after the policy update. This exchange rule prevents uncontrolled growth of the working set and supports effective policy training. Our theoretical analysis demonstrates that, under mild assumptions, strategies trained via EPO achieve performance comparable to optimal solutions with global constraint violations strictly remaining within a prescribed bound.
Bridging Performance Gaps for Foundation Models: A Post-Training Strategy for ECGFounder
Sep 16, 2025ECG foundation models are increasingly popular due to their adaptability across various tasks. However, their clinical applicability is often limited by performance gaps compared to task-specific models, even after pre-training on large ECG datasets and fine-tuning on target data. This limitation is likely due to the lack of an effective post-training strategy. In this paper, we propose a simple yet effective post-training approach to enhance ECGFounder, a state-of-the-art ECG foundation model pre-trained on over 7 million ECG recordings. Experiments on the PTB-XL benchmark show that our approach improves the baseline fine-tuning strategy by 1.2%-3.3% in macro AUROC and 5.3%-20.9% in macro AUPRC. Additionally, our method outperforms several recent state-of-the-art approaches, including task-specific and advanced architectures. Further evaluation reveals that our method is more stable and sample-efficient compared to the baseline, achieving a 9.1% improvement in macro AUROC and a 34.9% improvement in macro AUPRC using just 10% of the training data. Ablation studies identify key components, such as stochastic depth and preview linear probing, that contribute to the enhanced performance. These findings underscore the potential of post-training strategies to improve ECG foundation models, and we hope this work will contribute to the continued development of foundation models in the ECG domain.
Mel-McNet: A Mel-Scale Framework for Online Multichannel Speech Enhancement
May 26, 2025Online multichannel speech enhancement has been intensively studied recently. Though Mel-scale frequency is more matched with human auditory perception and computationally efficient than linear frequency, few works are implemented in a Mel-frequency domain. To this end, this work proposes a Mel-scale framework (namely Mel-McNet). It processes spectral and spatial information with two key components: an effective STFT-to-Mel module compressing multi-channel STFT features into Mel-frequency representations, and a modified McNet backbone directly operating in the Mel domain to generate enhanced LogMel spectra. The spectra can be directly fed to vocoders for waveform reconstruction or ASR systems for transcription. Experiments on CHiME-3 show that Mel-McNet can reduce computational complexity by 60% while maintaining comparable enhancement and ASR performance to the original McNet. Mel-McNet also outperforms other SOTA methods, verifying the potential of Mel-scale speech enhancement.
CleanMel: Mel-Spectrogram Enhancement for Improving Both Speech Quality and ASR
Feb 27, 2025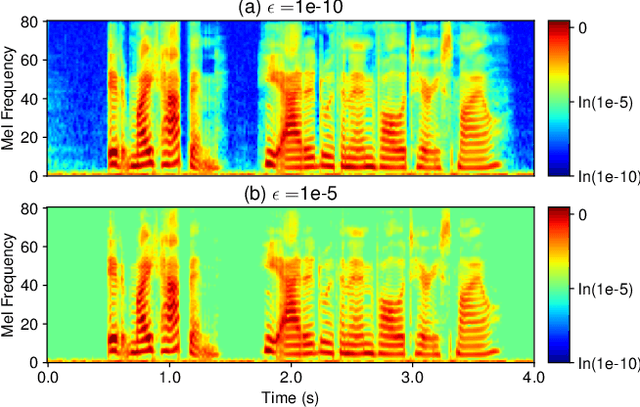
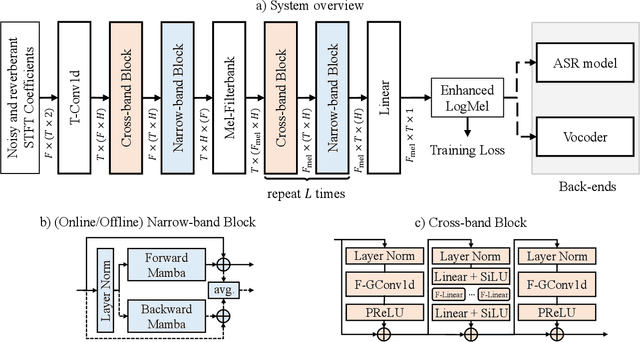
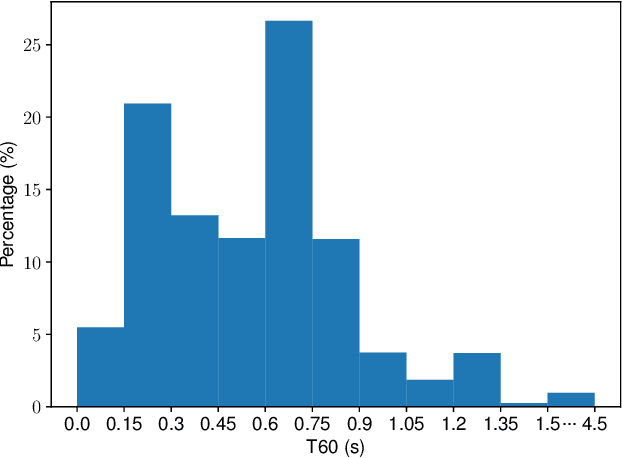
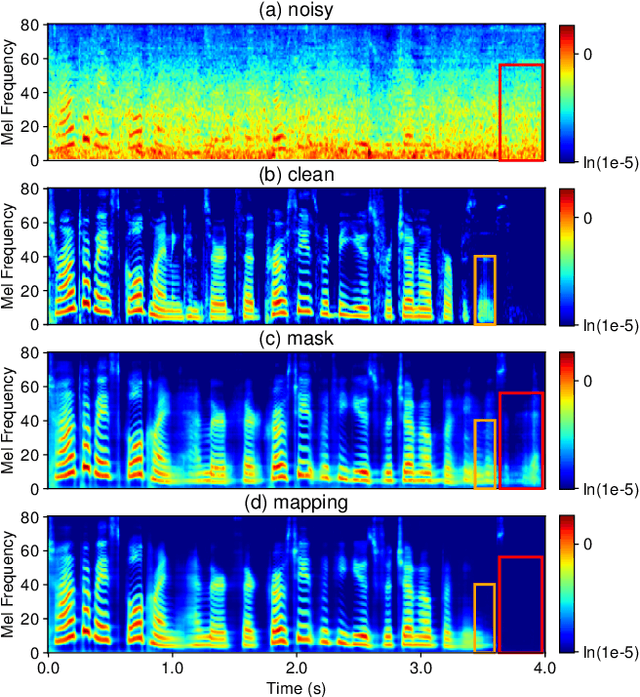
In this work, we propose CleanMel, a single-channel Mel-spectrogram denoising and dereverberation network for improving both speech quality and automatic speech recognition (ASR) performance. The proposed network takes as input the noisy and reverberant microphone recording and predicts the corresponding clean Mel-spectrogram. The enhanced Mel-spectrogram can be either transformed to speech waveform with a neural vocoder or directly used for ASR. The proposed network is composed of interleaved cross-band and narrow-band processing in the Mel-frequency domain, for learning the full-band spectral pattern and the narrow-band properties of signals, respectively. Compared to linear-frequency domain or time-domain speech enhancement, the key advantage of Mel-spectrogram enhancement is that Mel-frequency presents speech in a more compact way and thus is easier to learn, which will benefit both speech quality and ASR. Experimental results on four English and one Chinese datasets demonstrate a significant improvement in both speech quality and ASR performance achieved by the proposed model. Code and audio examples of our model are available online in https://audio.westlake.edu.cn/Research/CleanMel.html.
Life-Code: Central Dogma Modeling with Multi-Omics Sequence Unification
Feb 11, 2025



The interactions between DNA, RNA, and proteins are fundamental to biological processes, as illustrated by the central dogma of molecular biology. While modern biological pre-trained models have achieved great success in analyzing these macromolecules individually, their interconnected nature remains under-explored. In this paper, we follow the guidance of the central dogma to redesign both the data and model pipeline and offer a comprehensive framework, Life-Code, that spans different biological functions. As for data flow, we propose a unified pipeline to integrate multi-omics data by reverse-transcribing RNA and reverse-translating amino acids into nucleotide-based sequences. As for the model, we design a codon tokenizer and a hybrid long-sequence architecture to encode the interactions of both coding and non-coding regions with masked modeling pre-training. To model the translation and folding process with coding sequences, Life-Code learns protein structures of the corresponding amino acids by knowledge distillation from off-the-shelf protein language models. Such designs enable Life-Code to capture complex interactions within genetic sequences, providing a more comprehensive understanding of multi-omics with the central dogma. Extensive Experiments show that Life-Code achieves state-of-the-art performance on various tasks across three omics, highlighting its potential for advancing multi-omics analysis and interpretation.
Multi-scale Masked Autoencoder for Electrocardiogram Anomaly Detection
Feb 08, 2025



Electrocardiogram (ECG) analysis is a fundamental tool for diagnosing cardiovascular conditions, yet anomaly detection in ECG signals remains challenging due to their inherent complexity and variability. We propose Multi-scale Masked Autoencoder for ECG anomaly detection (MMAE-ECG), a novel end-to-end framework that effectively captures both global and local dependencies in ECG data. Unlike state-of-the-art methods that rely on heartbeat segmentation or R-peak detection, MMAE-ECG eliminates the need for such pre-processing steps, enhancing its suitability for clinical deployment. MMAE-ECG partitions ECG signals into non-overlapping segments, with each segment assigned learnable positional embeddings. A novel multi-scale masking strategy and multi-scale attention mechanism, along with distinct positional embeddings, enable a lightweight Transformer encoder to effectively capture both local and global dependencies. The masked segments are then reconstructed using a single-layer Transformer block, with an aggregation strategy employed during inference to refine the outputs. Experimental results demonstrate that our method achieves performance comparable to state-of-the-art approaches while significantly reducing computational complexity-approximately 1/78 of the floating-point operations (FLOPs) required for inference. Ablation studies further validate the effectiveness of each component, highlighting the potential of multi-scale masked autoencoders for anomaly detection.