 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPDnet2: an efficient and improved inter-channel phase difference estimation network for sound source localization
Sep 26, 2025IPDnet is our recently proposed real-time sound source localization network. It employs alternating full-band and narrow-band (B)LSTMs to learn the full-band correlation and narrow-band extraction of DP-IPD, respectively, which achieves superior performance. However, processing narrow-band independently incurs high computational complexity and the limited scalability of LSTM layers constrains the localization accuracy. In this work, we extend IPDnet to IPDnet2, improving both localization accuracy and efficiency. IPDnet2 adapts the oSpatialNet as the backbone to enhance spatial cues extraction and provide superior scalability. Additionally, a simple yet effective frequency-time pooling mechanism is proposed to compress frequency and time resolutions and thus reduce computational cost, and meanwhile not losing localization capability. Experimental results show that IPDnet2 achieves comparable localization performance with IPDnet while only requiring less than 2\% of its computation cost. Moreover, the proposed network achieves state-of-the-art SSL performance by scaling up the model size while still maintaining relatively low complexity.
RealMAN: A Real-Recorded and Annotated Microphone Array Dataset for Dynamic Speech Enhancement and Localization
Jun 28, 2024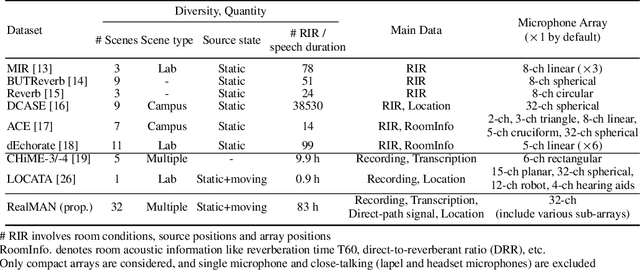
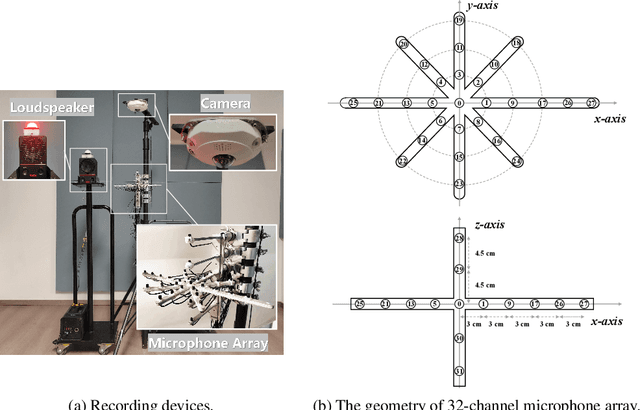


The training of deep learning-based multichannel speech enhancement and source localization systems relies heavily on the simulation of room impulse response and multichannel diffuse noise, due to the lack of large-scale real-recorded datasets. However, the acoustic mismatch between simulated and real-world data could degrade the model performance when applying in real-world scenarios. To bridge this simulation-to-real gap, this paper presents a new relatively large-scale Real-recorded and annotated Microphone Array speech&Noise (RealMAN) dataset. The proposed dataset is valuable in two aspects: 1) benchmarking speech enhancement and localization algorithms in real scenarios; 2) offering a substantial amount of real-world training data for potentially improving the performance of real-world applications. Specifically, a 32-channel array with high-fidelity microphones is used for recording. A loudspeaker is used for playing source speech signals. A total of 83-hour speech signals (48 hours for static speaker and 35 hours for moving speaker) are recorded in 32 different scenes, and 144 hours of background noise are recorded in 31 different scenes. Both speech and noise recording scenes cover various common indoor, outdoor, semi-outdoor and transportation environments, which enables the training of general-purpose speech enhancement and source localization networks. To obtain the task-specific annotations, the azimuth angle of the loudspeaker is annotated with an omni-direction fisheye camera by automatically detecting the loudspeaker. The direct-path signal is set as the target clean speech for speech enhancement, which is obtained by filtering the source speech signal with an estimated direct-path propagation filter.
IPDnet: A Universal Direct-Path IPD Estimation Network for Sound Source Localization
May 11, 2024



Extracting direct-path spatial feature is crucial for sound source localization in adverse acoustic environments. This paper proposes the IPDnet, a neural network that estimates direct-path inter-channel phase difference (DP-IPD) of sound sources from microphone array signals. The estimated DP-IPD can be easily translated to source location based on the known microphone array geometry. First, a full-band and narrow-band fusion network is proposed for DP-IPD estimation, in which alternating narrow-band and full-band layers are responsible for estimating the rough DP-IPD information in one frequency band and capturing the frequency correlations of DP-IPD, respectively. Second, a new multi-track DP-IPD learning target is proposed for the localization of flexible number of sound sources. Third, the IPDnet is extend to handling variable microphone arrays, once trained which is able to process arbitrary microphone arrays with different number of channels and array topology. Experiments of multiple-moving-speaker localization are conducted on both simulated and real-world data, which show that the proposed full-band and narrow-band fusion network and the proposed multi-track DP-IPD learning target together achieves excellent sound source localization performance. Moreover, the proposed variable-array model generalizes well to unseen microphone arrays.
FN-SSL: Full-Band and Narrow-Band Fusion for Sound Source Localization
May 31, 2023Extracting direct-path spatial features is critical for sound source localization in adverse acoustic environments. This paper proposes a full-band and narrow-band fusion network for estimating direct-path inter-channel phase difference (DP-IPD) from microphone signals. The alternating full-band and narrow-band layers are responsible for learning the full-band correlation and narrow-band extraction of DP-IPD, respectively. Experiments show that the proposed network noticeably outperforms other advanced methods on both simulated and real-world data.
Physiological-Physical Feature Fusion for Automatic Voice Spoofing Detection
Sep 01, 2021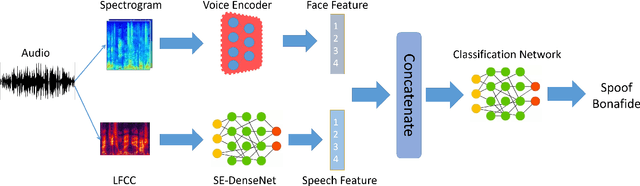



Speaker verification systems have been used in many production scenarios in recent years. Unfortunately, they are still highly prone to different kinds of spoofing attacks such as voice conversion and speech synthesis, etc. In this paper, we propose a new method base on physiological-physical feature fusion to deal with voice spoofing attacks. This method involves feature extraction, a densely connected convolutional neural network with squeeze and excitation block (SE-DenseNet), multi-scale residual neural network with squeeze and excitation block (SE-Res2Net) and feature fusion strategies. We first pre-trained a convolutional neural network using the speaker's voice and face in the video as surveillance signals. It can extract physiological features from speech. Then we use SE-DenseNet and SE-Res2Net to extract physical features. Such a densely connection pattern has high parameter efficiency and squeeze and excitation block can enhance the transmission of the feature. Finally, we integrate the two features into the SE-Densenet to identify the spoofing attacks. Experimental results on the ASVspoof 2019 data set show that our model is effective for voice spoofing detection. In the logical access scenario, our model improves the tandem decision cost function (t-DCF) and equal error rate (EER) scores by 4% and 7%, respectively, compared with other methods. In the physical access scenario, our model improved t-DCF and EER scores by 8% and 10%, respectively.