 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Duplex Interaction in Spoken Dialogue Systems: A Comprehensive Study from the ICASSP 2026 HumDial Challenge
Apr 23, 2026Full-duplex interaction, where speakers and listeners converse simultaneously, is a key element of human communication often missing from traditional spoken dialogue systems. These systems, based on rigid turn-taking paradigms, struggle to respond naturally in dynamic conversations. The Full-Duplex Interaction Track of ICASSP 2026 Human-like Spoken Dialogue Systems Challenge (HumDial Challenge) aims to advance the evaluation of full-duplex systems by offering a framework for handling real-time interruptions, speech overlap, and dynamic turn negotiation. We introduce a comprehensive benchmark for full-duplex spoken dialogue systems, built from the HumDial Challenge. We release a high-quality dual-channel dataset of real human-recorded conversations, capturing interruptions, overlapping speech, and feedback mechanisms. This dataset forms the basis for the HumDial-FDBench benchmark, which assesses a system's ability to handle interruptions while maintaining conversational flow. Additionally, we create a public leaderboard to compare the performance of open-source and proprietary models, promoting transparent, reproducible evaluation. These resources support the development of more responsive, adaptive, and human-like dialogue systems.
HumDial-EIBench: A Human-Recorded Multi-Turn Emotional Intelligence Benchmark for Audio Language Models
Apr 13, 2026Evaluating the emotional intelligence (EI) of audio language models (ALMs) is critical. However, existing benchmarks mostly rely on synthesized speech, are limited to single-turn interactions, and depend heavily on open-ended scoring. This paper proposes HumDial-EIBench, a comprehensive benchmark for evaluating ALMs' EI. Using real-recorded human dialogues from the ICASSP 2026 HumDial Challenge, it reformulates emotional tracking and causal reasoning into multiple-choice questions with adversarial distractors, mitigating subjective scoring bias for cognitive tasks. It retains the generation of empathetic responses and introduces an acoustic-semantic conflict task to assess robustness against contradictory multimodal signals. Evaluations of eight ALMs reveal that most models struggle with multi-turn emotional tracking and implicit causal reasoning. Furthermore, all models exhibit decoupled textual and acoustic empathy, alongside a severe text-dominance bias during cross-modal conflicts.
WenetSpeech-Wu: Datasets, Benchmarks, and Models for a Unified Chinese Wu Dialect Speech Processing Ecosystem
Jan 16, 2026Speech processing for low-resource dialects remains a fundamental challenge in developing inclusive and robust speech technologies. Despite its linguistic significance and large speaker population, the Wu dialect of Chinese has long been hindered by the lack of large-scale speech data, standardized evaluation benchmarks, and publicly available models. In this work, we present WenetSpeech-Wu, the first large-scale, multi-dimensionally annotated open-source speech corpus for the Wu dialect, comprising approximately 8,000 hours of diverse speech data. Building upon this dataset, we introduce WenetSpeech-Wu-Bench, the first standardized and publicly accessible benchmark for systematic evaluation of Wu dialect speech processing, covering automatic speech recognition (ASR), Wu-to-Mandarin translation, speaker attribute prediction, speech emotion recognition, text-to-speech (TTS) synthesis, and instruction-following TTS (instruct TTS). Furthermore, we release a suite of strong open-source models trained on WenetSpeech-Wu, establishing competitive performance across multiple tasks and empirically validating the effectiveness of the proposed dataset. Together, these contributions lay the foundation for a comprehensive Wu dialect speech processing ecosystem, and we open-source proposed datasets, benchmarks, and models to support future research on dialectal speech intelligence.
The CCF AATC 2025: Speech Restoration Challenge
Sep 16, 2025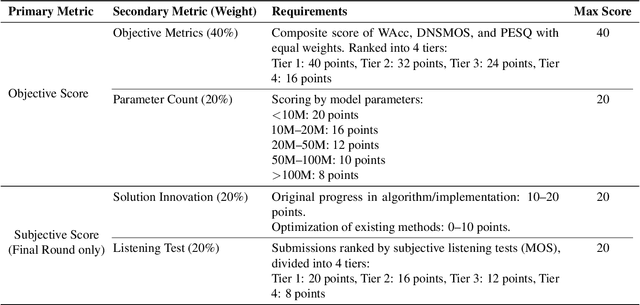
Real-world speech communication is often hampered by a variety of distortions that degrade quality and intelligibility. While many speech enhancement algorithms target specific degradations like noise or reverberation, they often fall short in realistic scenarios where multiple distortions co-exist and interact. To spur research in this area, we introduce the Speech Restoration Challenge as part of the China Computer Federation (CCF) Advanced Audio Technology Competition (AATC) 2025. This challenge focuses on restoring speech signals affected by a composite of three degradation types: (1) complex acoustic degradations including non-stationary noise and reverberation; (2) signal-chain artifacts such as those from MP3 compression; and (3) secondary artifacts introduced by other pre-processing enhancement models. We describe the challenge's background, the design of the task, the comprehensive dataset creation methodology, and the detailed evaluation protocol, which assesses both objective performance and model complexity. Homepage: https://ccf-aatc.org.cn/.
AISHELL-5: The First Open-Source In-Car Multi-Channel Multi-Speaker Speech Dataset for Automatic Speech Diarization and Recognition
May 29, 2025This paper delineates AISHELL-5, the first open-source in-car multi-channel multi-speaker Mandarin automatic speech recognition (ASR) dataset. AISHLL-5 includes two parts: (1) over 100 hours of multi-channel speech data recorded in an electric vehicle across more than 60 real driving scenarios. This audio data consists of four far-field speech signals captured by microphones located on each car door, as well as near-field signals obtained from high-fidelity headset microphones worn by each speaker. (2) a collection of 40 hours of real-world environmental noise recordings, which supports the in-car speech data simulation. Moreover, we also provide an open-access, reproducible baseline system based on this dataset. This system features a speech frontend model that employs speech source separation to extract each speaker's clean speech from the far-field signals, along with a speech recognition module that accurately transcribes the content of each individual speaker. Experimental results demonstrate the challenges faced by various mainstream ASR models when evaluated on the AISHELL-5. We firmly believe the AISHELL-5 dataset will significantly advance the research on ASR systems under complex driving scenarios by establishing the first publicly available in-car ASR benchmark.
MusicEval: A Generative Music Corpus with Expert Ratings for Automatic Text-to-Music Evaluation
Jan 18, 2025



The technology for generating music from textual descriptions has seen rapid advancements. However, evaluating text-to-music (TTM) systems remains a significant challenge, primarily due to the difficulty of balancing performance and cost with existing objective and subjective evaluation methods. In this paper, we propose an automatic assessment task for TTM models to align with human perception. To address the TTM evaluation challenges posed by the professional requirements of music evaluation and the complexity of the relationship between text and music, we collect MusicEval, the first generative music assessment dataset. This dataset contains 2,748 music clips generated by 31 advanced and widely used models in response to 384 text prompts, along with 13,740 ratings from 14 music experts. Furthermore, we design a CLAP-based assessment model built on this dataset, and our experimental results validate the feasibility of the proposed task, providing a valuable reference for future development in TTM evaluation. The dataset is available at https://www.aishelltech.com/AISHELL_7A.
Exploring Differences between Human Perception and Model Inference in Audio Event Recognition
Sep 10, 2024



Audio Event Recognition (AER) traditionally focuses on detecting and identifying audio events. Most existing AER models tend to detect all potential events without considering their varying significance across different contexts. This makes the AER results detected by existing models often have a large discrepancy with human auditory perception. Although this is a critical and significant issue, it has not been extensively studied by the Detection and Classification of Sound Scenes and Events (DCASE) community because solving it is time-consuming and labour-intensive. To address this issue, this paper introduces the concept of semantic importance in AER, focusing on exploring the differences between human perception and model inference. This paper constructs a Multi-Annotated Foreground Audio Event Recognition (MAFAR) dataset, which comprises audio recordings labelled by 10 professional annotators. Through labelling frequency and variance, the MAFAR dataset facilitates the quantification of semantic importance and analysis of human perception. By comparing human annotations with the predictions of ensemble pre-trained models, this paper uncovers a significant gap between human perception and model inference in both semantic identification and existence detection of audio events. Experimental results reveal that human perception tends to ignore subtle or trivial events in the event semantic identification, while model inference is easily affected by events with noises. Meanwhile, in event existence detection, models are usually more sensitive than humans.
Findings of the 2024 Mandarin Stuttering Event Detection and Automatic Speech Recognition Challenge
Sep 09, 2024



The StutteringSpeech Challenge focuses on advancing speech technologies for people who stutter, specifically targeting Stuttering Event Detection (SED) and Automatic Speech Recognition (ASR) in Mandarin. The challenge comprises three tracks: (1) SED, which aims to develop systems for detection of stuttering events; (2) ASR, which focuses on creating robust systems for recognizing stuttered speech; and (3) Research track for innovative approaches utilizing the provided dataset. We utilizes an open-source Mandarin stuttering dataset AS-70, which has been split into new training and test sets for the challenge. This paper presents the dataset, details the challenge tracks, and analyzes the performance of the top systems, highlighting improvements in detection accuracy and reductions in recognition error rates. Our findings underscore the potential of specialized models and augmentation strategies in developing stuttered speech technologies.
RealMAN: A Real-Recorded and Annotated Microphone Array Dataset for Dynamic Speech Enhancement and Localization
Jun 28, 2024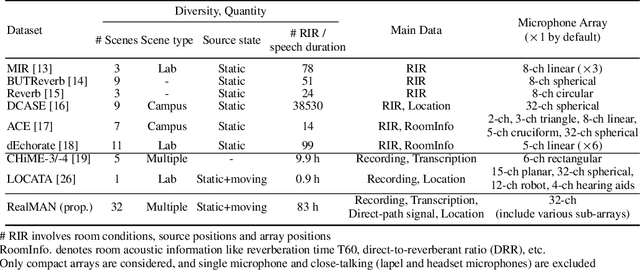
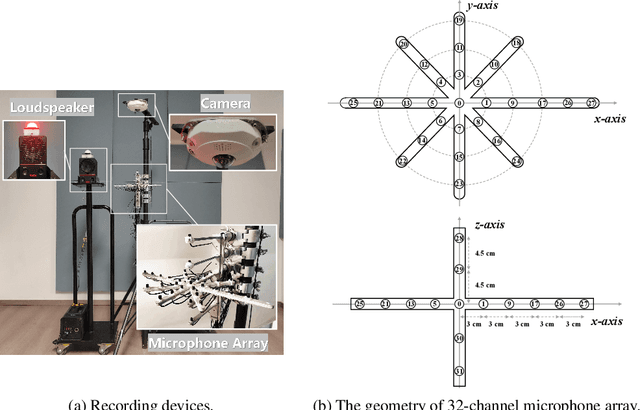


The training of deep learning-based multichannel speech enhancement and source localization systems relies heavily on the simulation of room impulse response and multichannel diffuse noise, due to the lack of large-scale real-recorded datasets. However, the acoustic mismatch between simulated and real-world data could degrade the model performance when applying in real-world scenarios. To bridge this simulation-to-real gap, this paper presents a new relatively large-scale Real-recorded and annotated Microphone Array speech&Noise (RealMAN) dataset. The proposed dataset is valuable in two aspects: 1) benchmarking speech enhancement and localization algorithms in real scenarios; 2) offering a substantial amount of real-world training data for potentially improving the performance of real-world applications. Specifically, a 32-channel array with high-fidelity microphones is used for recording. A loudspeaker is used for playing source speech signals. A total of 83-hour speech signals (48 hours for static speaker and 35 hours for moving speaker) are recorded in 32 different scenes, and 144 hours of background noise are recorded in 31 different scenes. Both speech and noise recording scenes cover various common indoor, outdoor, semi-outdoor and transportation environments, which enables the training of general-purpose speech enhancement and source localization networks. To obtain the task-specific annotations, the azimuth angle of the loudspeaker is annotated with an omni-direction fisheye camera by automatically detecting the loudspeaker. The direct-path signal is set as the target clean speech for speech enhancement, which is obtained by filtering the source speech signal with an estimated direct-path propagation filter.
Enhancing Voice Wake-Up for Dysarthria: Mandarin Dysarthria Speech Corpus Release and Customized System Design
Jun 14, 2024



Smart home technology has gained widespread adoption, facilitating effortless control of devices through voice commands. However, individuals with dysarthria, a motor speech disorder, face challenges due to the variability of their speech. This paper addresses the wake-up word spotting (WWS) task for dysarthric individuals, aiming to integrate them into real-world applications. To support this, we release the open-source Mandarin Dysarthria Speech Corpus (MDSC), a dataset designed for dysarthric individuals in home environments. MDSC encompasses information on age, gender, disease types, and intelligibility evaluations. Furthermore, we perform comprehensive experimental analysis on MDSC, highlighting the challenges encountered. We also develop a customized dysarthria WWS system that showcases robustness in handling intelligibility and achieving exceptional performance. MDSC will be released on https://www.aishelltech.com/AISHELL_6B.