 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMyGram: Modality-aware Graph Transformer with Global Distribution for Multi-modal Entity Alignment
Jan 17, 2026Multi-modal entity alignment aims to identify equivalent entities between two multi-modal Knowledge graphs by integrating multi-modal data, such as images and text, to enrich the semantic representations of entities. However, existing methods may overlook the structural contextual information within each modality, making them vulnerable to interference from shallow features. To address these challenges, we propose MyGram, a modality-aware graph transformer with global distribution for multi-modal entity alignment. Specifically, we develop a modality diffusion learning module to capture deep structural contextual information within modalities and enable fine-grained multi-modal fusion. In addition, we introduce a Gram Loss that acts as a regularization constraint by minimizing the volume of a 4-dimensional parallelotope formed by multi-modal features, thereby achieving global distribution consistency across modalities. We conduct experiments on five public datasets. Results show that MyGram outperforms baseline models, achieving a maximum improvement of 4.8% in Hits@1 on FBDB15K, 9.9% on FBYG15K, and 4.3% on DBP15K.
MacVQA: Adaptive Memory Allocation and Global Noise Filtering for Continual Visual Question Answering
Jan 05, 2026Visual Question Answering (VQA) requires models to reason over multimodal information, combining visual and textual data. With the development of continual learning, significant progress has been made in retaining knowledge and adapting to new information in the VQA domain. However, current methods often struggle with balancing knowledge retention, adaptation, and robust feature representation. To address these challenges, we propose a novel framework with adaptive memory allocation and global noise filtering called MacVQA for visual question answering. MacVQA fuses visual and question information while filtering noise to ensure robust representations, and employs prototype-based memory allocation to optimize feature quality and memory usage. These designs enable MacVQA to balance knowledge acquisition, retention, and compositional generalization in continual VQA learning. Experiments on ten continual VQA tasks show that MacVQA outperforms existing baselines, achieving 43.38% average accuracy and 2.32% average forgetting on standard tasks, and 42.53% average accuracy and 3.60% average forgetting on novel composition tasks.
KeenKT: Knowledge Mastery-State Disambiguation for Knowledge Tracing
Dec 21, 2025Knowledge Tracing (KT) aims to dynamically model a student's mastery of knowledge concepts based on their historical learning interactions. Most current methods rely on single-point estimates, which cannot distinguish true ability from outburst or carelessness, creating ambiguity in judging mastery. To address this issue, we propose a Knowledge Mastery-State Disambiguation for Knowledge Tracing model (KeenKT), which represents a student's knowledge state at each interaction using a Normal-Inverse-Gaussian (NIG) distribution, thereby capturing the fluctuations in student learning behaviors. Furthermore, we design an NIG-distance-based attention mechanism to model the dynamic evolution of the knowledge state. In addition, we introduce a diffusion-based denoising reconstruction loss and a distributional contrastive learning loss to enhance the model's robustness. Extensive experiments on six public datasets demonstrate that KeenKT outperforms SOTA KT models in terms of prediction accuracy and sensitivity to behavioral fluctuations. The proposed method yields the maximum AUC improvement of 5.85% and the maximum ACC improvement of 6.89%.
IPDnet2: an efficient and improved inter-channel phase difference estimation network for sound source localization
Sep 26, 2025IPDnet is our recently proposed real-time sound source localization network. It employs alternating full-band and narrow-band (B)LSTMs to learn the full-band correlation and narrow-band extraction of DP-IPD, respectively, which achieves superior performance. However, processing narrow-band independently incurs high computational complexity and the limited scalability of LSTM layers constrains the localization accuracy. In this work, we extend IPDnet to IPDnet2, improving both localization accuracy and efficiency. IPDnet2 adapts the oSpatialNet as the backbone to enhance spatial cues extraction and provide superior scalability. Additionally, a simple yet effective frequency-time pooling mechanism is proposed to compress frequency and time resolutions and thus reduce computational cost, and meanwhile not losing localization capability. Experimental results show that IPDnet2 achieves comparable localization performance with IPDnet while only requiring less than 2\% of its computation cost. Moreover, the proposed network achieves state-of-the-art SSL performance by scaling up the model size while still maintaining relatively low complexity.
Mel-McNet: A Mel-Scale Framework for Online Multichannel Speech Enhancement
May 26, 2025Online multichannel speech enhancement has been intensively studied recently. Though Mel-scale frequency is more matched with human auditory perception and computationally efficient than linear frequency, few works are implemented in a Mel-frequency domain. To this end, this work proposes a Mel-scale framework (namely Mel-McNet). It processes spectral and spatial information with two key components: an effective STFT-to-Mel module compressing multi-channel STFT features into Mel-frequency representations, and a modified McNet backbone directly operating in the Mel domain to generate enhanced LogMel spectra. The spectra can be directly fed to vocoders for waveform reconstruction or ASR systems for transcription. Experiments on CHiME-3 show that Mel-McNet can reduce computational complexity by 60% while maintaining comparable enhancement and ASR performance to the original McNet. Mel-McNet also outperforms other SOTA methods, verifying the potential of Mel-scale speech enhancement.
A Causal Convolutional Low-rank Representation Model for Imputation of Water Quality Data
Apr 21, 2025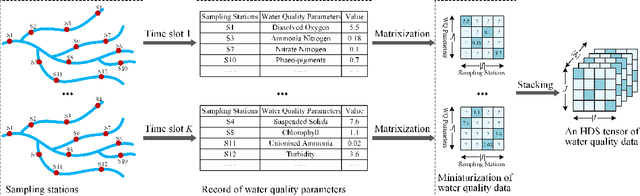
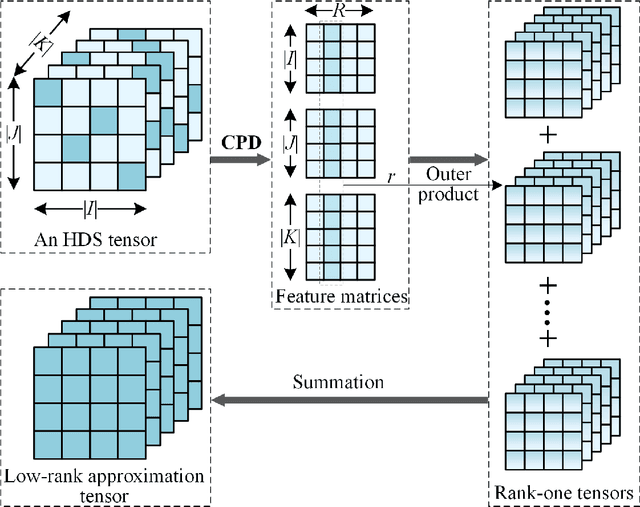
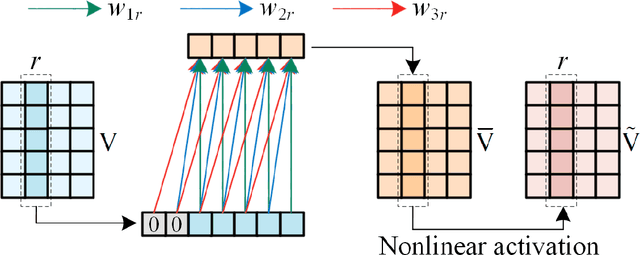

The monitoring of water quality is a crucial part of environmental protection, and a large number of monitors are widely deployed to monitor water quality. Due to unavoidable factors such as data acquisition breakdowns, sensors and communication failures, water quality monitoring data suffers from missing values over time, resulting in High-Dimensional and Sparse (HDS) Water Quality Data (WQD). The simple and rough filling of the missing values leads to inaccurate results and affects the implementation of relevant measures. Therefore, this paper proposes a Causal convolutional Low-rank Representation (CLR) model for imputing missing WQD to improve the completeness of the WQD, which employs a two-fold idea: a) applying causal convolutional operation to consider the temporal dependence of the low-rank representation, thus incorporating temporal information to improve the imputation accuracy; and b) implementing a hyperparameters adaptation scheme to automatically adjust the best hyperparameters during model training, thereby reducing the tedious manual adjustment of hyper-parameters. Experimental studies on three real-world water quality datasets demonstrate that the proposed CLR model is superior to some of the existing state-of-the-art imputation models in terms of imputation accuracy and time cost, as well as indicating that the proposed model provides more reliable decision support for environmental monitoring.
Water Quality Data Imputation via A Fast Latent Factorization of Tensors with PID-based Optimizer
Mar 10, 2025Water quality data can supply a substantial decision support for water resources utilization and pollution prevention. However, there are numerous missing values in water quality data due to inescapable factors like sensor failure, thereby leading to biased result for hydrological analysis and failing to support environmental governance decision accurately. A Latent Factorization of Tensors (LFT) with Stochastic Gradient Descent (SGD) proves to be an efficient imputation method. However, a standard SGD-based LFT model commonly surfers from the slow convergence that impairs its efficiency. To tackle this issue, this paper proposes a Fast Latent Factorization of Tensors (FLFT) model. It constructs an adjusted instance error into SGD via leveraging a nonlinear PID controller to incorporates the past, current and future information of prediction error for improving convergence rate. Comparing with state-of-art models in real world datasets, the results of experiment indicate that the FLFT model achieves a better convergence rate and higher accuracy.
STNet: Deep Audio-Visual Fusion Network for Robust Speaker Tracking
Oct 08, 2024



Audio-visual speaker tracking aims to determine the location of human targets in a scene using signals captured by a multi-sensor platform, whose accuracy and robustness can be improved by multi-modal fusion methods. Recently, several fusion methods have been proposed to model the correlation in multiple modalities. However, for the speaker tracking problem, the cross-modal interaction between audio and visual signals hasn't been well exploited. To this end, we present a novel Speaker Tracking Network (STNet) with a deep audio-visual fusion model in this work. We design a visual-guided acoustic measurement method to fuse heterogeneous cues in a unified localization space, which employs visual observations via a camera model to construct the enhanced acoustic map. For feature fusion, a cross-modal attention module is adopted to jointly model multi-modal contexts and interactions. The correlated information between audio and visual features is further interacted in the fusion model. Moreover, the STNet-based tracker is applied to multi-speaker cases by a quality-aware module, which evaluates the reliability of multi-modal observations to achieve robust tracking in complex scenarios. Experiments on the AV16.3 and CAV3D datasets show that the proposed STNet-based tracker outperforms uni-modal methods and state-of-the-art audio-visual speaker trackers.
RealMAN: A Real-Recorded and Annotated Microphone Array Dataset for Dynamic Speech Enhancement and Localization
Jun 28, 2024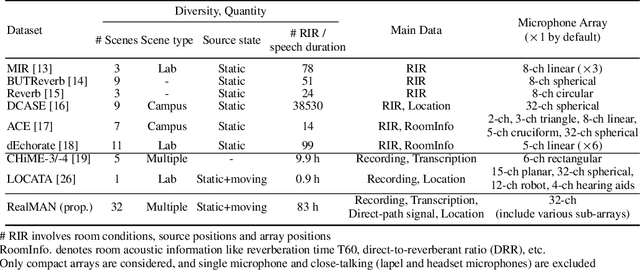
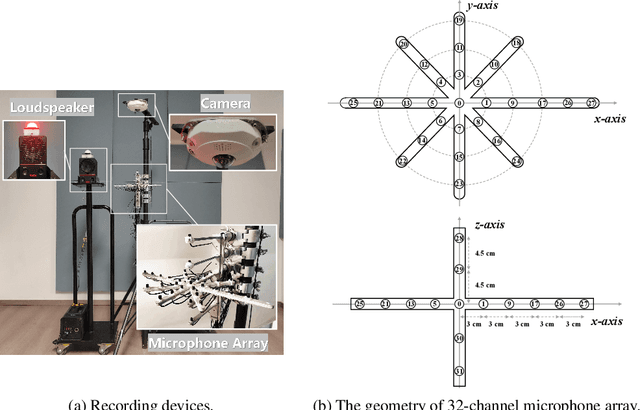


The training of deep learning-based multichannel speech enhancement and source localization systems relies heavily on the simulation of room impulse response and multichannel diffuse noise, due to the lack of large-scale real-recorded datasets. However, the acoustic mismatch between simulated and real-world data could degrade the model performance when applying in real-world scenarios. To bridge this simulation-to-real gap, this paper presents a new relatively large-scale Real-recorded and annotated Microphone Array speech&Noise (RealMAN) dataset. The proposed dataset is valuable in two aspects: 1) benchmarking speech enhancement and localization algorithms in real scenarios; 2) offering a substantial amount of real-world training data for potentially improving the performance of real-world applications. Specifically, a 32-channel array with high-fidelity microphones is used for recording. A loudspeaker is used for playing source speech signals. A total of 83-hour speech signals (48 hours for static speaker and 35 hours for moving speaker) are recorded in 32 different scenes, and 144 hours of background noise are recorded in 31 different scenes. Both speech and noise recording scenes cover various common indoor, outdoor, semi-outdoor and transportation environments, which enables the training of general-purpose speech enhancement and source localization networks. To obtain the task-specific annotations, the azimuth angle of the loudspeaker is annotated with an omni-direction fisheye camera by automatically detecting the loudspeaker. The direct-path signal is set as the target clean speech for speech enhancement, which is obtained by filtering the source speech signal with an estimated direct-path propagation filter.
IPDnet: A Universal Direct-Path IPD Estimation Network for Sound Source Localization
May 11, 2024



Extracting direct-path spatial feature is crucial for sound source localization in adverse acoustic environments. This paper proposes the IPDnet, a neural network that estimates direct-path inter-channel phase difference (DP-IPD) of sound sources from microphone array signals. The estimated DP-IPD can be easily translated to source location based on the known microphone array geometry. First, a full-band and narrow-band fusion network is proposed for DP-IPD estimation, in which alternating narrow-band and full-band layers are responsible for estimating the rough DP-IPD information in one frequency band and capturing the frequency correlations of DP-IPD, respectively. Second, a new multi-track DP-IPD learning target is proposed for the localization of flexible number of sound sources. Third, the IPDnet is extend to handling variable microphone arrays, once trained which is able to process arbitrary microphone arrays with different number of channels and array topology. Experiments of multiple-moving-speaker localization are conducted on both simulated and real-world data, which show that the proposed full-band and narrow-band fusion network and the proposed multi-track DP-IPD learning target together achieves excellent sound source localization performance. Moreover, the proposed variable-array model generalizes well to unseen microphone arrays.