 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural personal sound zones with flexible bright zone control
Dec 11, 2025Personal sound zone (PSZ) reproduction system, which attempts to create distinct virtual acoustic scenes for different listeners at their respective positions within the same spatial area using one loudspeaker array, is a fundamental technology in the application of virtual reality. For practical applications, the reconstruction targets must be measured on the same fixed receiver array used to record the local room impulse responses (RIRs) from the loudspeaker array to the control points in each PSZ, which makes the system inconvenient and costly for real-world use. In this paper, a 3D convolutional neural network (CNN) designed for PSZ reproduction with flexible control microphone grid and alternative reproduction target is presented, utilizing the virtual target scene as inputs and the PSZ pre-filters as output. Experimental results of the proposed method are compared with the traditional method, demonstrating that the proposed method is able to handle varied reproduction targets on flexible control point grid using only one training session. Furthermore, the proposed method also demonstrates the capability to learn global spatial information from sparse sampling points distributed in PSZs.
IPDnet2: an efficient and improved inter-channel phase difference estimation network for sound source localization
Sep 26, 2025IPDnet is our recently proposed real-time sound source localization network. It employs alternating full-band and narrow-band (B)LSTMs to learn the full-band correlation and narrow-band extraction of DP-IPD, respectively, which achieves superior performance. However, processing narrow-band independently incurs high computational complexity and the limited scalability of LSTM layers constrains the localization accuracy. In this work, we extend IPDnet to IPDnet2, improving both localization accuracy and efficiency. IPDnet2 adapts the oSpatialNet as the backbone to enhance spatial cues extraction and provide superior scalability. Additionally, a simple yet effective frequency-time pooling mechanism is proposed to compress frequency and time resolutions and thus reduce computational cost, and meanwhile not losing localization capability. Experimental results show that IPDnet2 achieves comparable localization performance with IPDnet while only requiring less than 2\% of its computation cost. Moreover, the proposed network achieves state-of-the-art SSL performance by scaling up the model size while still maintaining relatively low complexity.
Rec-RIR: Monaural Blind Room Impulse Response Identification via DNN-based Reverberant Speech Reconstruction in STFT Domain
Sep 19, 2025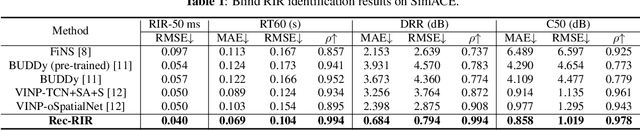
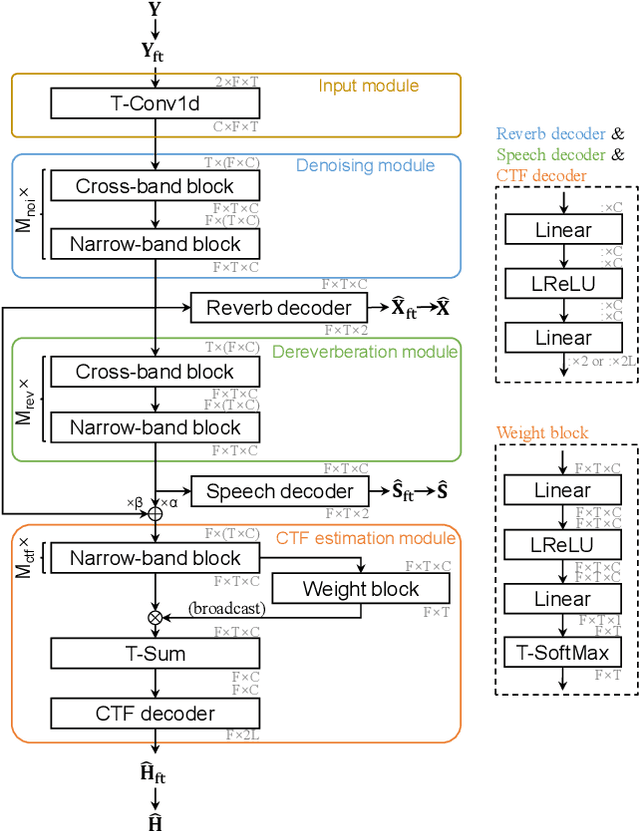
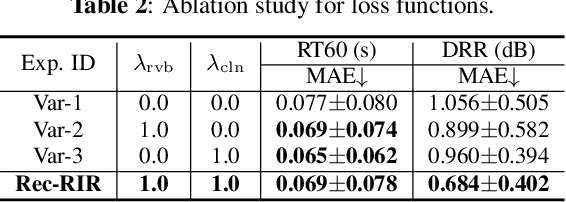
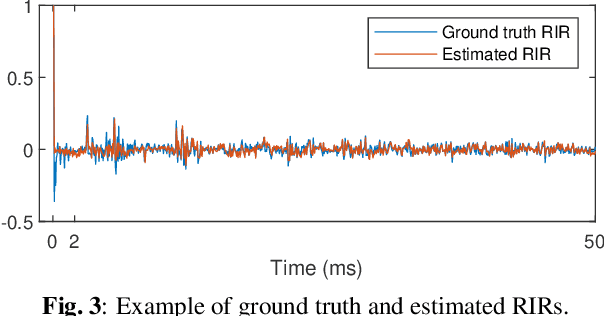
Room impulse response (RIR) characterizes the complete propagation process of sound in an enclosed space. This paper presents Rec-RIR for monaural blind RIR identification. Rec-RIR is developed based on the convolutive transfer function (CTF) approximation, which models reverberation effect within narrow-band filter banks in the short-time Fourier transform (STFT) domain. Specifically, we propose a deep neural network (DNN) with cross-band and narrow-band blocks to estimate the CTF filter. The DNN is trained through reconstructing the noise-free reverberant speech spectra. This objective enables stable and straightforward supervised training. Subsequently, a pseudo intrusive measurement process is employed to convert the CTF filter estimate into time-domain RIR by simulating a common intrusive RIR measurement procedure. Experimental results demonstrate that Rec-RIR achieves state-of-the-art (SOTA) performance in both RIR identification and acoustic parameter estimation. Open-source codes are available online at https://github.com/Audio-WestlakeU/Rec-RIR.
UMA-Split: unimodal aggregation for both English and Mandarin non-autoregressive speech recognition
Sep 18, 2025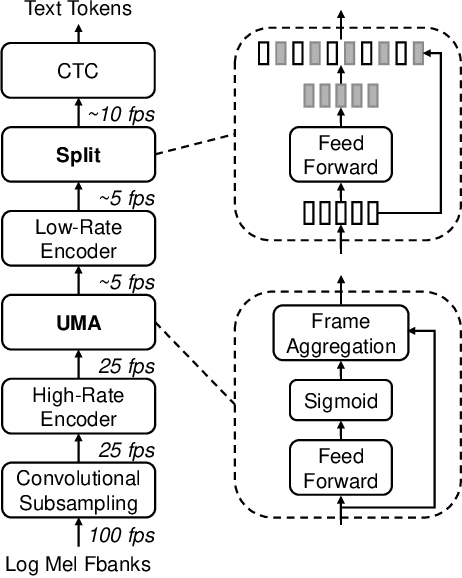
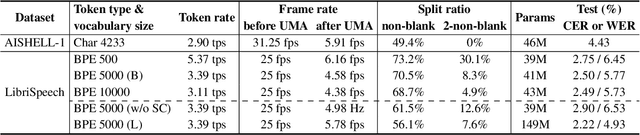
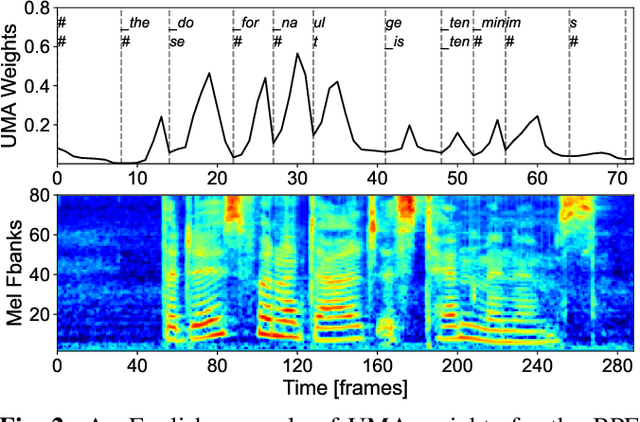
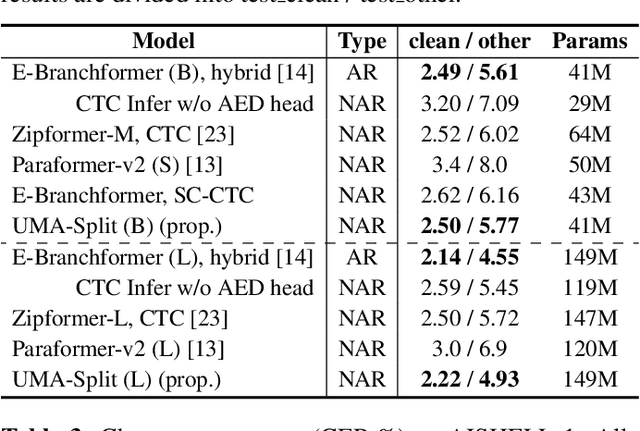
This paper proposes a unimodal aggregation (UMA) based nonautoregressive model for both English and Mandarin speech recognition. The original UMA explicitly segments and aggregates acoustic frames (with unimodal weights that first monotonically increase and then decrease) of the same text token to learn better representations than regular connectionist temporal classification (CTC). However, it only works well in Mandarin. It struggles with other languages, such as English, for which a single syllable may be tokenized into multiple fine-grained tokens, or a token spans fewer than 3 acoustic frames and fails to form unimodal weights. To address this problem, we propose allowing each UMA-aggregated frame map to multiple tokens, via a simple split module that generates two tokens from each aggregated frame before computing the CTC loss.
A Composite Predictive-Generative Approach to Monaural Universal Speech Enhancement
May 30, 2025It is promising to design a single model that can suppress various distortions and improve speech quality, i.e., universal speech enhancement (USE). Compared to supervised learning-based predictive methods, diffusion-based generative models have shown greater potential due to the generative capacities from degraded speech with severely damaged information. However, artifacts may be introduced in highly adverse conditions, and diffusion models often suffer from a heavy computational burden due to many steps for inference. In order to jointly leverage the superiority of prediction and generation and overcome the respective defects, in this work we propose a universal speech enhancement model called PGUSE by combining predictive and generative modeling. Our model consists of two branches: the predictive branch directly predicts clean samples from degraded signals, while the generative branch optimizes the denoising objective of diffusion models. We utilize the output fusion and truncated diffusion scheme to effectively integrate predictive and generative modeling, where the former directly combines results from both branches and the latter modifies the reverse diffusion process with initial estimates from the predictive branch. Extensive experiments on several datasets verify the superiority of the proposed model over state-of-the-art baselines, demonstrating the complementarity and benefits of combining predictive and generative modeling.
Mel-McNet: A Mel-Scale Framework for Online Multichannel Speech Enhancement
May 26, 2025Online multichannel speech enhancement has been intensively studied recently. Though Mel-scale frequency is more matched with human auditory perception and computationally efficient than linear frequency, few works are implemented in a Mel-frequency domain. To this end, this work proposes a Mel-scale framework (namely Mel-McNet). It processes spectral and spatial information with two key components: an effective STFT-to-Mel module compressing multi-channel STFT features into Mel-frequency representations, and a modified McNet backbone directly operating in the Mel domain to generate enhanced LogMel spectra. The spectra can be directly fed to vocoders for waveform reconstruction or ASR systems for transcription. Experiments on CHiME-3 show that Mel-McNet can reduce computational complexity by 60% while maintaining comparable enhancement and ASR performance to the original McNet. Mel-McNet also outperforms other SOTA methods, verifying the potential of Mel-scale speech enhancement.
Bridging VLM and KMP: Enabling Fine-grained robotic manipulation via Semantic Keypoints Representation
Mar 04, 2025
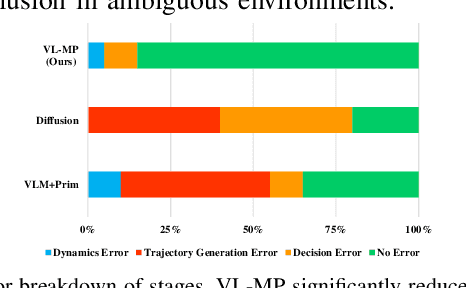
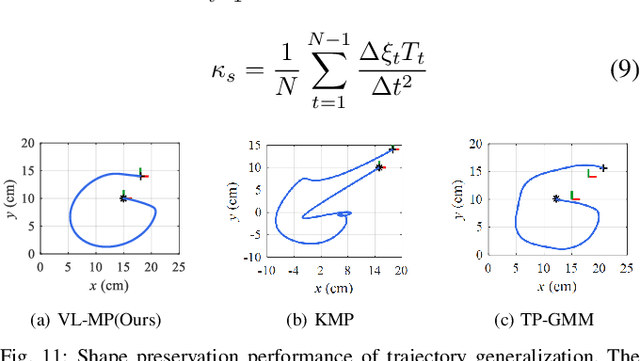
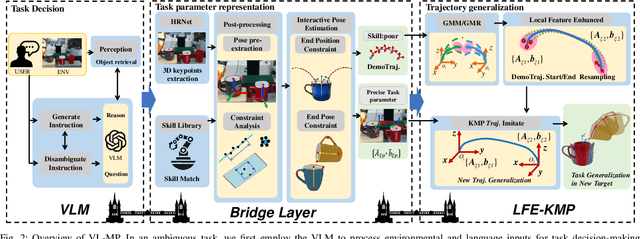
From early Movement Primitive (MP) techniques to modern Vision-Language Models (VLMs), autonomous manipulation has remained a pivotal topic in robotics. As two extremes, VLM-based methods emphasize zero-shot and adaptive manipulation but struggle with fine-grained planning. In contrast, MP-based approaches excel in precise trajectory generalization but lack decision-making ability. To leverage the strengths of the two frameworks, we propose VL-MP, which integrates VLM with Kernelized Movement Primitives (KMP) via a low-distortion decision information transfer bridge, enabling fine-grained robotic manipulation under ambiguous situations. One key of VL-MP is the accurate representation of task decision parameters through semantic keypoints constraints, leading to more precise task parameter generation. Additionally, we introduce a local trajectory feature-enhanced KMP to support VL-MP, thereby achieving shape preservation for complex trajectories. Extensive experiments conducted in complex real-world environments validate the effectiveness of VL-MP for adaptive and fine-grained manipulation.
CleanMel: Mel-Spectrogram Enhancement for Improving Both Speech Quality and ASR
Feb 27, 2025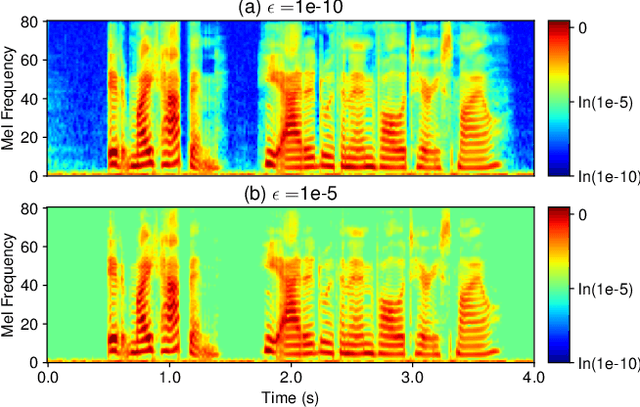
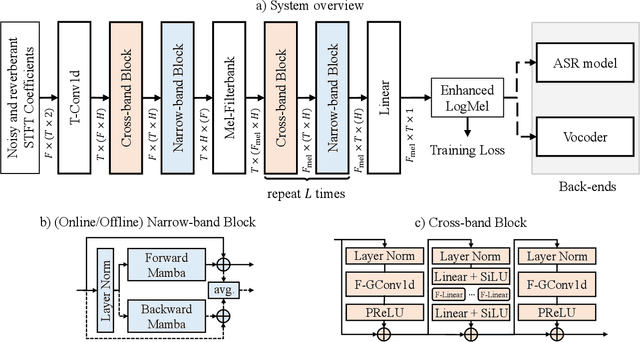
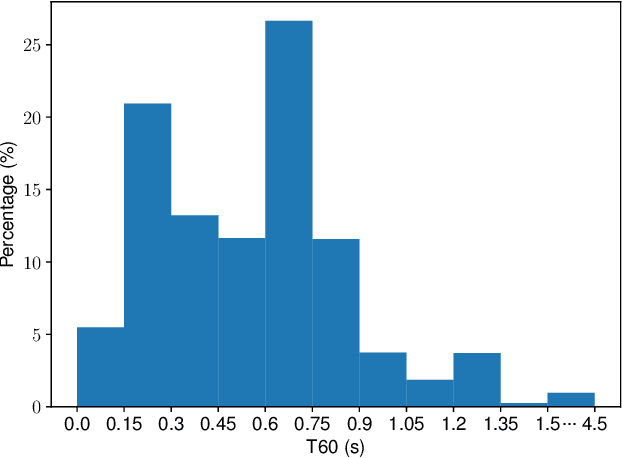
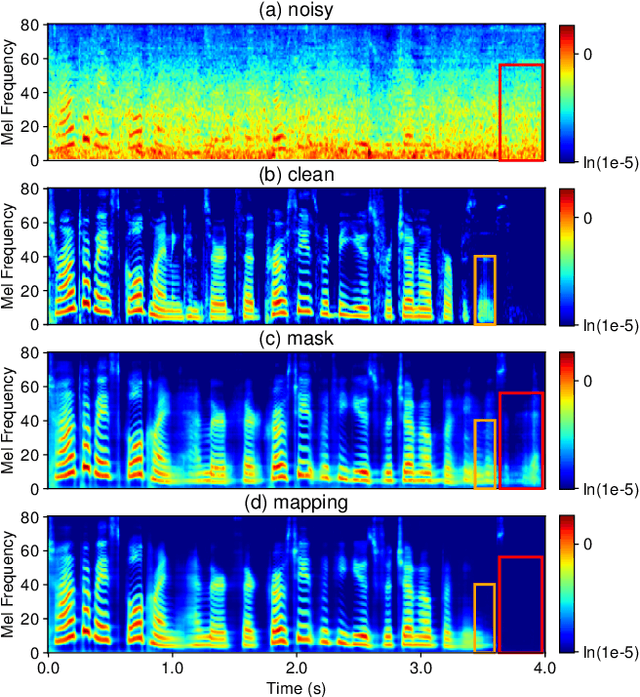
In this work, we propose CleanMel, a single-channel Mel-spectrogram denoising and dereverberation network for improving both speech quality and automatic speech recognition (ASR) performance. The proposed network takes as input the noisy and reverberant microphone recording and predicts the corresponding clean Mel-spectrogram. The enhanced Mel-spectrogram can be either transformed to speech waveform with a neural vocoder or directly used for ASR. The proposed network is composed of interleaved cross-band and narrow-band processing in the Mel-frequency domain, for learning the full-band spectral pattern and the narrow-band properties of signals, respectively. Compared to linear-frequency domain or time-domain speech enhancement, the key advantage of Mel-spectrogram enhancement is that Mel-frequency presents speech in a more compact way and thus is easier to learn, which will benefit both speech quality and ASR. Experimental results on four English and one Chinese datasets demonstrate a significant improvement in both speech quality and ASR performance achieved by the proposed model. Code and audio examples of our model are available online in https://audio.westlake.edu.cn/Research/CleanMel.html.
VINP: Variational Bayesian Inference with Neural Speech Prior for Joint ASR-Effective Speech Dereverberation and Blind RIR Identification
Feb 11, 2025Reverberant speech, denoting the speech signal degraded by the process of reverberation, contains crucial knowledge of both anechoic source speech and room impulse response (RIR). This work proposes a variational Bayesian inference (VBI) framework with neural speech prior (VINP) for joint speech dereverberation and blind RIR identification. In VINP, a probabilistic signal model is constructed in the time-frequency (T-F) domain based on convolution transfer function (CTF) approximation. For the first time, we propose using an arbitrary discriminative dereverberation deep neural network (DNN) to predict the prior distribution of anechoic speech within a probabilistic model. By integrating both reverberant speech and the anechoic speech prior, VINP yields the maximum a posteriori (MAP) and maximum likelihood (ML) estimations of the anechoic speech spectrum and CTF filter, respectively. After simple transformations, the waveforms of anechoic speech and RIR are estimated. Moreover, VINP is effective for automatic speech recognition (ASR) systems, which sets it apart from most deep learning (DL)-based single-channel dereverberation approaches. Experiments on single-channel speech dereverberation demonstrate that VINP reaches an advanced level in most metrics related to human perception and displays unquestionable state-of-the-art (SOTA) performance in ASR-related metrics. For blind RIR identification, experiments indicate that VINP attains the SOTA level in blind estimation of reverberation time at 60 dB (RT60) and direct-to-reverberation ratio (DRR). Codes and audio samples are available online.
LS-EEND: Long-Form Streaming End-to-End Neural Diarization with Online Attractor Extraction
Oct 09, 2024



This work proposes a frame-wise online/streaming end-to-end neural diarization (EEND) method, which detects speaker activities in a frame-in-frame-out fashion. The proposed model mainly consists of a causal embedding encoder and an online attractor decoder. Speakers are modeled in the self-attention-based decoder along both the time and speaker dimensions, and frame-wise speaker attractors are automatically generated and updated for new speakers and existing speakers, respectively. Retention mechanism is employed and especially adapted for long-form diarization with a linear temporal complexity. A multi-step progressive training strategy is proposed for gradually learning from easy tasks to hard tasks in terms of the number of speakers and audio length. Finally, the proposed model (referred to as long-form streaming EEND, LS-EEND) is able to perform streaming diarization for a high (up to 8) and flexible number speakers and very long (say one hour) audio recordings. Experiments on various simulated and real-world datasets show that: 1) when not using oracle speech activity information, the proposed model achieves new state-of-the-art online diarization error rate on all datasets, including CALLHOME (12.11%), DIHARD II (27.58%), DIHARD III (19.61%), and AMI (20.76%); 2) Due to the frame-in-frame-out processing fashion and the linear temporal complexity, the proposed model achieves several times lower real-time-factor than comparison online diarization models.