 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Temporal Detection Capability of Integrated Gradients Applied on Sound Classifier
May 22, 2026Gradient-based attribution methods can highlight input regions important for neural network predictions, but their effectiveness for temporal sound event detection in audio classification has not been systematically evaluated. This paper assesses whether integrated gradients (IG) can temporally detect sound events when applied to a classifier trained without temporal supervision. We use synthetic polyphonic audio with ground truth timestamps to measure alignment between IG attributions and event boundaries. On a 10-class domestic sound dataset, IG achieves mean Intersection over Union (IoU) of 0.39, frame-level F1 of 0.52, and Pointing Game accuracy of 82.6\%. For comparison, a framewise CNN trained with weak supervision (FW-WS, clip-level training labels) achieves 0.42 IoU, 0.55 F1, and 97.3\% PG, while a strongly supervised variant (FW-SS, frame-level training labels) reaches 0.45 IoU, 0.58 F1, and 97.9\% PG. Overall, these results suggest that post-hoc IG captures meaningful temporal activity patterns of sound events, with localization performance approaching models that explicitly produce frame-level predictions. All methods substantially outperform random and energy-based baselines.
Automatic Contextual Audio Denoising
May 21, 2026Audio context determines which sound components and sources are relevant and which can be perceived as irrelevant (noise) by listeners. For example, traffic noise is informative in urban surveillance but noise for a phone call at the same location. Most current audio denoising systems apply fixed target-noise definitions, often removing useful components in one context while failing to suppress irrelevant components. To address this, we introduce the concept automatic contextual audio denoising (ACAD) which defines target and noise based on the inferred context. In this work, we restrict context to be associated with an acoustic scene class. We label sound events outside the event distribution of a scene class (noise) as out-of-context (OC) and events typical for that scene as in-context (IC). We implement a deep learning method that automatically infers the context of the audio signal and removes OC components, and benchmark it against variants: without context inference, with oracle context, and with separately provided uninformative context. On paired clean/noisy data across diverse contexts, where OC components in one context may be IC in another, our proposed method outperforms other approaches across standard objective metrics, indicating that the model can infer context and context-dependent processing can enhance denoising.
Inter-Speaker Relative Cues for Two-Stage Text-Guided Target Speech Extraction
Mar 01, 2026This paper investigates the use of relative cues for text-based target speech extraction (TSE). We first provide a theoretical justification for relative cues from the perspectives of human perception and label quantization, showing that relative cues preserve fine-grained distinctions often lost in absolute categorical representations. Building on this analysis, we propose a two-stage TSE framework, in which a speech separation model generates candidate sources, followed by a text-guided classifier that selects the target speaker based on embedding similarity. Using this framework, we train two separate classification models to evaluate the advantages of relative cues over independent cues in terms of both classification accuracy and TSE performance. Experimental results demonstrate that (i) relative cues achieve higher overall classification accuracy and improved TSE performance compared with independent cues, (ii) the two-stage framework substantially outperforms single-stage text-conditioned extraction methods on both signal-level and objective perceptual metrics, and (iii) certain relative cues (language, gender, loudness, distance, temporal order, speaking duration, random cue and all cue) can surpass the performance of an audio-based TSE system. Further analysis reveals notable differences in discriminative power across cue types, providing insights into the effectiveness of different relative cues for TSE.
Moving Speaker Separation via Parallel Spectral-Spatial Processing
Feb 25, 2026Multi-channel speech separation in dynamic environments is challenging as time-varying spatial and spectral features evolve at different temporal scales. Existing methods typically employ sequential architectures, forcing a single network stream to simultaneously model both feature types, creating an inherent modeling conflict. In this paper, we propose a dual-branch parallel spectral-spatial (PS2) architecture that separately processes spectral and spatial features through parallel streams. The spectral branch uses a bi-directional long short-term memory (BLSTM)-based frequency module, a Mamba-based temporal module, and a self-attention module to model spectral features. The spatial branch employs bi-directional gated recurrent unit (BGRU) networks to process spatial features that encode the evolving geometric relationships between sources and microphones. Features from both branches are integrated through a cross-attention fusion mechanism that adaptively weights their contributions. Experimental results demonstrate that the PS2 outperforms existing state-of-the-art (SOTA) methods by 1.6-2.2 dB in scale-invariant signal-to-distortion ratio (SI-SDR) for moving speaker scenarios, with robust separation quality under different reverberation times (RT60), noise levels, and source movement speeds. Even with fast source movements, the proposed model maintains SI-SDR improvements of over 13 dB. These improvements are consistently observed across multiple datasets, including WHAMR! and our generated WSJ0-Demand-6ch-Move dataset.
Beyond Omnidirectional: Neural Ambisonics Encoding for Arbitrary Microphone Directivity Patterns using Cross-Attention
Jan 30, 2026We present a deep neural network approach for encoding microphone array signals into Ambisonics that generalizes to arbitrary microphone array configurations with fixed microphone count but varying locations and frequency-dependent directional characteristics. Unlike previous methods that rely only on array geometry as metadata, our approach uses directional array transfer functions, enabling accurate characterization of real-world arrays. The proposed architecture employs separate encoders for audio and directional responses, combining them through cross-attention mechanisms to generate array-independent spatial audio representations. We evaluate the method on simulated data in two settings: a mobile phone with complex body scattering, and a free-field condition, both with varying numbers of sound sources in reverberant environments. Evaluations demonstrate that our approach outperforms both conventional digital signal processing-based methods and existing deep neural network solutions. Furthermore, using array transfer functions instead of geometry as metadata input improves accuracy on realistic arrays.
Discriminating real and synthetic super-resolved audio samples using embedding-based classifiers
Jan 06, 2026Generative adversarial networks (GANs) and diffusion models have recently achieved state-of-the-art performance in audio super-resolution (ADSR), producing perceptually convincing wideband audio from narrowband inputs. However, existing evaluations primarily rely on signal-level or perceptual metrics, leaving open the question of how closely the distributions of synthetic super-resolved and real wideband audio match. Here we address this problem by analyzing the separability of real and super-resolved audio in various embedding spaces. We consider both middle-band ($4\to 16$~kHz) and full-band ($16\to 48$~kHz) upsampling tasks for speech and music, training linear classifiers to distinguish real from synthetic samples based on multiple types of audio embeddings. Comparisons with objective metrics and subjective listening tests reveal that embedding-based classifiers achieve near-perfect separation, even when the generated audio attains high perceptual quality and state-of-the-art metric scores. This behavior is consistent across datasets and models, including recent diffusion-based approaches, highlighting a persistent gap between perceptual quality and true distributional fidelity in ADSR models.
Acoustic Simulation Framework for Multi-channel Replay Speech Detection
Sep 18, 2025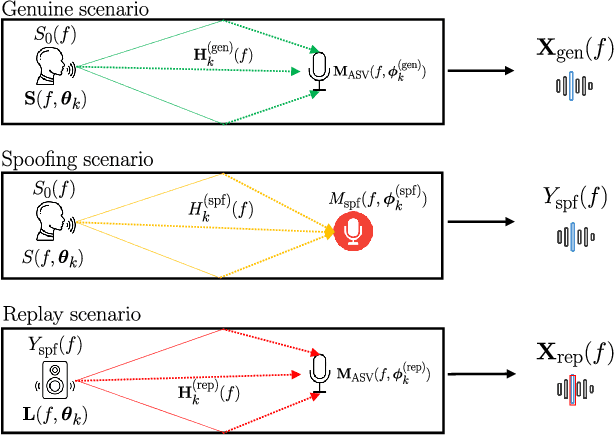

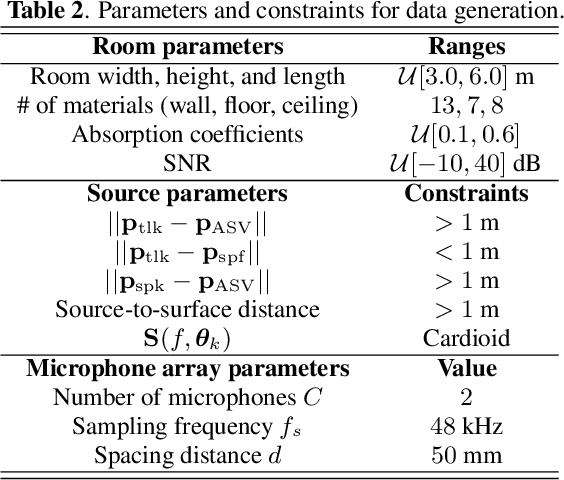
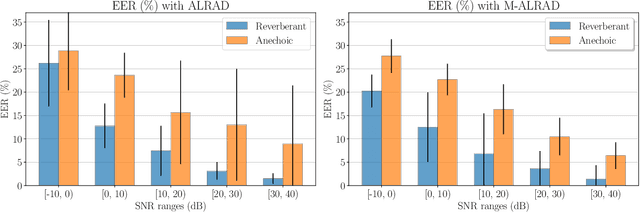
Replay speech attacks pose a significant threat to voice-controlled systems, especially in smart environments where voice assistants are widely deployed. While multi-channel audio offers spatial cues that can enhance replay detection robustness, existing datasets and methods predominantly rely on single-channel recordings. In this work, we introduce an acoustic simulation framework designed to simulate multi-channel replay speech configurations using publicly available resources. Our setup models both genuine and spoofed speech across varied environments, including realistic microphone and loudspeaker impulse responses, room acoustics, and noise conditions. The framework employs measured loudspeaker directionalities during the replay attack to improve the realism of the simulation. We define two spoofing settings, which simulate whether a reverberant or an anechoic speech is used in the replay scenario, and evaluate the impact of omnidirectional and diffuse noise on detection performance. Using the state-of-the-art M-ALRAD model for replay speech detection, we demonstrate that synthetic data can support the generalization capabilities of the detector across unseen enclosures.
Multi-Utterance Speech Separation and Association Trained on Short Segments
Jul 03, 2025Current deep neural network (DNN) based speech separation faces a fundamental challenge -- while the models need to be trained on short segments due to computational constraints, real-world applications typically require processing significantly longer recordings with multiple utterances per speaker than seen during training. In this paper, we investigate how existing approaches perform in this challenging scenario and propose a frequency-temporal recurrent neural network (FTRNN) that effectively bridges this gap. Our FTRNN employs a full-band module to model frequency dependencies within each time frame and a sub-band module that models temporal patterns in each frequency band. Despite being trained on short fixed-length segments of 10 s, our model demonstrates robust separation when processing signals significantly longer than training segments (21-121 s) and preserves speaker association across utterance gaps exceeding those seen during training. Unlike the conventional segment-separation-stitch paradigm, our lightweight approach (0.9 M parameters) performs inference on long audio without segmentation, eliminating segment boundary distortions while simplifying deployment. Experimental results demonstrate the generalization ability of FTRNN for multi-utterance speech separation and speaker association.
Hybrid Disagreement-Diversity Active Learning for Bioacoustic Sound Event Detection
May 28, 2025Bioacoustic sound event detection (BioSED) is crucial for biodiversity conservation but faces practical challenges during model development and training: limited amounts of annotated data, sparse events, species diversity, and class imbalance. To address these challenges efficiently with a limited labeling budget, we apply the mismatch-first farthest-traversal (MFFT), an active learning method integrating committee voting disagreement and diversity analysis. We also refine an existing BioSED dataset specifically for evaluating active learning algorithms. Experimental results demonstrate that MFFT achieves a mAP of 68% when cold-starting and 71% when warm-starting (which is close to the fully-supervised mAP of 75%) while using only 2.3% of the annotations. Notably, MFFT excels in cold-start scenarios and with rare species, which are critical for monitoring endangered species, demonstrating its practical value.
Attractor-Based Speech Separation of Multiple Utterances by Unknown Number of Speakers
May 22, 2025This paper addresses the problem of single-channel speech separation, where the number of speakers is unknown, and each speaker may speak multiple utterances. We propose a speech separation model that simultaneously performs separation, dynamically estimates the number of speakers, and detects individual speaker activities by integrating an attractor module. The proposed system outperforms existing methods by introducing an attractor-based architecture that effectively combines local and global temporal modeling for multi-utterance scenarios. To evaluate the method in reverberant and noisy conditions, a multi-speaker multi-utterance dataset was synthesized by combining Librispeech speech signals with WHAM! noise signals. The results demonstrate that the proposed system accurately estimates the number of sources. The system effectively detects source activities and separates the corresponding utterances into correct outputs in both known and unknown source count scenarios.