 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Simulation Framework for Multi-channel Replay Speech Detection
Sep 18, 2025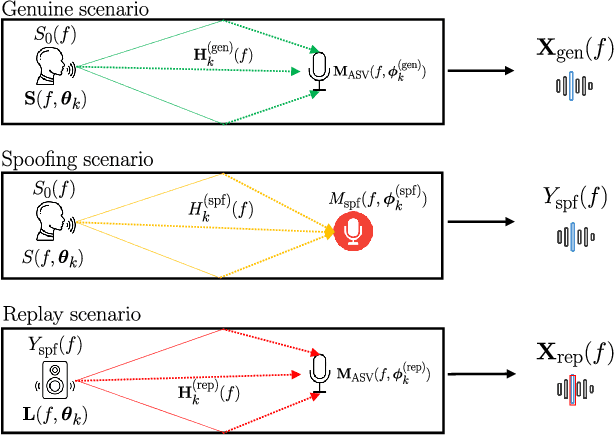

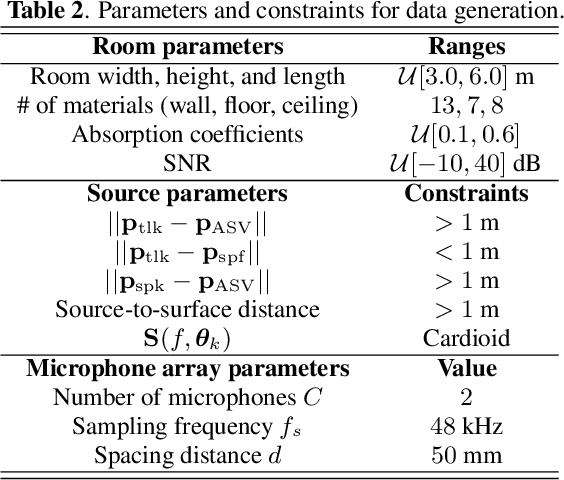
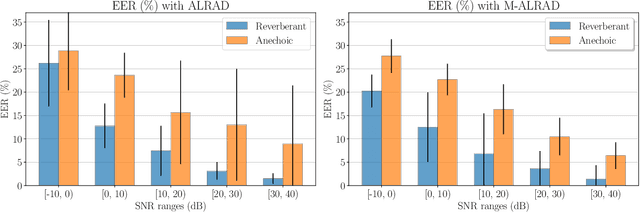
Replay speech attacks pose a significant threat to voice-controlled systems, especially in smart environments where voice assistants are widely deployed. While multi-channel audio offers spatial cues that can enhance replay detection robustness, existing datasets and methods predominantly rely on single-channel recordings. In this work, we introduce an acoustic simulation framework designed to simulate multi-channel replay speech configurations using publicly available resources. Our setup models both genuine and spoofed speech across varied environments, including realistic microphone and loudspeaker impulse responses, room acoustics, and noise conditions. The framework employs measured loudspeaker directionalities during the replay attack to improve the realism of the simulation. We define two spoofing settings, which simulate whether a reverberant or an anechoic speech is used in the replay scenario, and evaluate the impact of omnidirectional and diffuse noise on detection performance. Using the state-of-the-art M-ALRAD model for replay speech detection, we demonstrate that synthetic data can support the generalization capabilities of the detector across unseen enclosures.
Teleoperated Driving: a New Challenge for 3D Object Detection in Compressed Point Clouds
Jun 13, 2025In recent years, the development of interconnected devices has expanded in many fields, from infotainment to education and industrial applications. This trend has been accelerated by the increased number of sensors and accessibility to powerful hardware and software. One area that significantly benefits from these advancements is Teleoperated Driving (TD). In this scenario, a controller drives safely a vehicle from remote leveraging sensors data generated onboard the vehicle, and exchanged via Vehicle-to-Everything (V2X) communications. In this work, we tackle the problem of detecting the presence of cars and pedestrians from point cloud data to enable safe TD operations. More specifically, we exploit the SELMA dataset, a multimodal, open-source, synthetic dataset for autonomous driving, that we expanded by including the ground-truth bounding boxes of 3D objects to support object detection. We analyze the performance of state-of-the-art compression algorithms and object detectors under several metrics, including compression efficiency, (de)compression and inference time, and detection accuracy. Moreover, we measure the impact of compression and detection on the V2X network in terms of data rate and latency with respect to 3GPP requirements for TD applications.
Unsupervised Network Anomaly Detection with Autoencoders and Traffic Images
May 22, 2025Due to the recent increase in the number of connected devices, the need to promptly detect security issues is emerging. Moreover, the high number of communication flows creates the necessity of processing huge amounts of data. Furthermore, the connected devices are heterogeneous in nature, having different computational capacities. For this reason, in this work we propose an image-based representation of network traffic which allows to realize a compact summary of the current network conditions with 1-second time windows. The proposed representation highlights the presence of anomalies thus reducing the need for complex processing architectures. Finally, we present an unsupervised learning approach which effectively detects the presence of anomalies. The code and the dataset are available at https://github.com/michaelneri/image-based-network-traffic-anomaly-detection.
Low-Complexity Patch-based No-Reference Point Cloud Quality Metric exploiting Weighted Structure and Texture Features
Mar 19, 2025During the compression, transmission, and rendering of point clouds, various artifacts are introduced, affecting the quality perceived by the end user. However, evaluating the impact of these distortions on the overall quality is a challenging task. This study introduces PST-PCQA, a no-reference point cloud quality metric based on a low-complexity, learning-based framework. It evaluates point cloud quality by analyzing individual patches, integrating local and global features to predict the Mean Opinion Score. In summary, the process involves extracting features from patches, combining them, and using correlation weights to predict the overall quality. This approach allows us to assess point cloud quality without relying on a reference point cloud, making it particularly useful in scenarios where reference data is unavailable. Experimental tests on three state-of-the-art datasets show good prediction capabilities of PST-PCQA, through the analysis of different feature pooling strategies and its ability to generalize across different datasets. The ablation study confirms the benefits of evaluating quality on a patch-by-patch basis. Additionally, PST-PCQA's light-weight structure, with a small number of parameters to learn, makes it well-suited for real-time applications and devices with limited computational capacity. For reproducibility purposes, we made code, model, and pretrained weights available at https://github.com/michaelneri/PST-PCQA.
Impact of Microphone Array Mismatches to Learning-based Replay Speech Detection
Mar 10, 2025In this work, we investigate the generalization of a multi-channel learning-based replay speech detector, which employs adaptive beamforming and detection, across different microphone arrays. In general, deep neural network-based microphone array processing techniques generalize poorly to unseen array types, i.e., showing a significant training-test mismatch of performance. We employ the ReMASC dataset to analyze performance degradation due to inter- and intra-device mismatches, assessing both single- and multi-channel configurations. Furthermore, we explore fine-tuning to mitigate the performance loss when transitioning to unseen microphone arrays. Our findings reveal that array mismatches significantly decrease detection accuracy, with intra-device generalization being more robust than inter-device. However, fine-tuning with as little as ten minutes of target data can effectively recover performance, providing insights for practical deployment of replay detection systems in heterogeneous automatic speaker verification environments.
Multi-channel Replay Speech Detection using an Adaptive Learnable Beamformer
Feb 19, 2025



Replay attacks belong to the class of severe threats against voice-controlled systems, exploiting the easy accessibility of speech signals by recorded and replayed speech to grant unauthorized access to sensitive data. In this work, we propose a multi-channel neural network architecture called M-ALRAD for the detection of replay attacks based on spatial audio features. This approach integrates a learnable adaptive beamformer with a convolutional recurrent neural network, allowing for joint optimization of spatial filtering and classification. Experiments have been carried out on the ReMASC dataset, which is a state-of-the-art multi-channel replay speech detection dataset encompassing four microphones with diverse array configurations and four environments. Results on the ReMASC dataset show the superiority of the approach compared to the state-of-the-art and yield substantial improvements for challenging acoustic environments. In addition, we demonstrate that our approach is able to better generalize to unseen environments with respect to prior studies.
Low-complexity Attention-based Unsupervised Anomalous Sound Detection exploiting Separable Convolutions and Angular Loss
Oct 11, 2024



In this work, a novel deep neural network, designed to enhance the efficiency and effectiveness of unsupervised sound anomaly detection, is presented. The proposed model exploits an attention module and separable convolutions to identify salient time-frequency patterns in audio data to discriminate between normal and anomalous sounds with reduced computational complexity. The approach is validated through extensive experiments using the Task 2 dataset of the DCASE 2020 challenge. Results demonstrate superior performance in terms of anomaly detection accuracy while having fewer parameters than state-of-the-art methods. Implementation details, code, and pre-trained models are available in https://github.com/michaelneri/unsupervised-audio-anomaly-detection.
Speaker Distance Estimation in Enclosures from Single-Channel Audio
Mar 26, 2024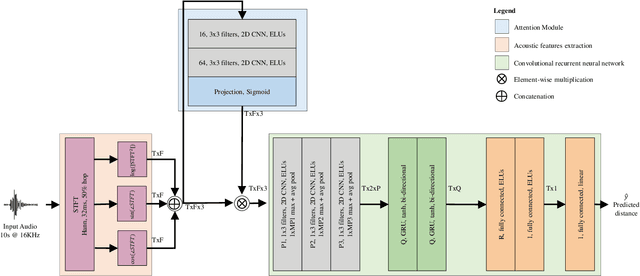


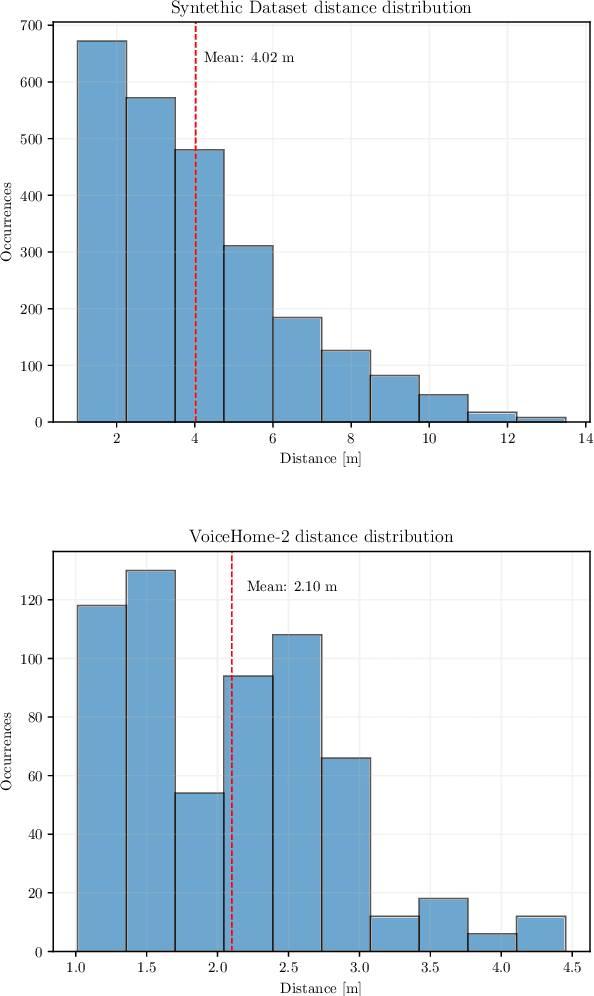
Distance estimation from audio plays a crucial role in various applications, such as acoustic scene analysis, sound source localization, and room modeling. Most studies predominantly center on employing a classification approach, where distances are discretized into distinct categories, enabling smoother model training and achieving higher accuracy but imposing restrictions on the precision of the obtained sound source position. Towards this direction, in this paper we propose a novel approach for continuous distance estimation from audio signals using a convolutional recurrent neural network with an attention module. The attention mechanism enables the model to focus on relevant temporal and spectral features, enhancing its ability to capture fine-grained distance-related information. To evaluate the effectiveness of our proposed method, we conduct extensive experiments using audio recordings in controlled environments with three levels of realism (synthetic room impulse response, measured response with convolved speech, and real recordings) on four datasets (our synthetic dataset, QMULTIMIT, VoiceHome-2, and STARSS23). Experimental results show that the model achieves an absolute error of 0.11 meters in a noiseless synthetic scenario. Moreover, the results showed an absolute error of about 1.30 meters in the hybrid scenario. The algorithm's performance in the real scenario, where unpredictable environmental factors and noise are prevalent, yields an absolute error of approximately 0.50 meters. For reproducible research purposes we make model, code, and synthetic datasets available at https://github.com/michaelneri/audio-distance-estimation.