 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-informed Music Source Separation: Improving Synthetic-to-real Generalization in Classical Music
Mar 10, 2025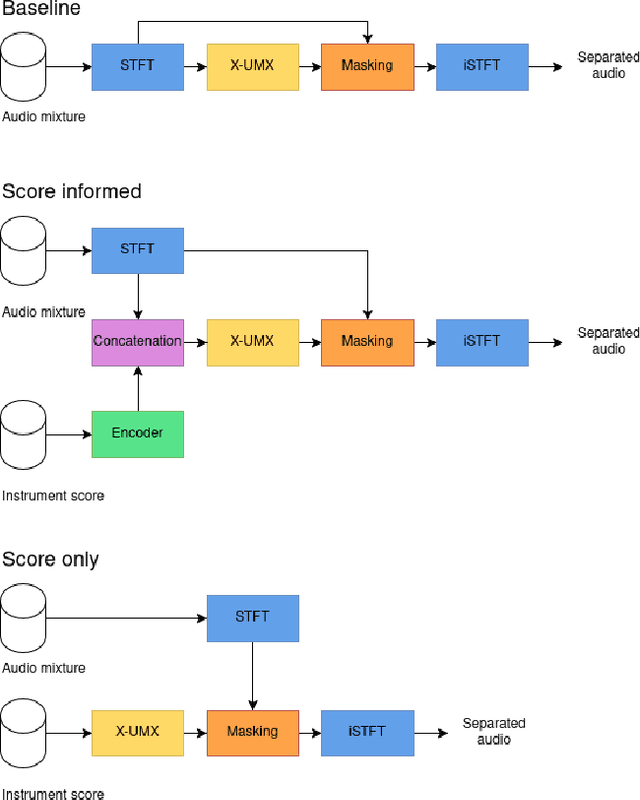
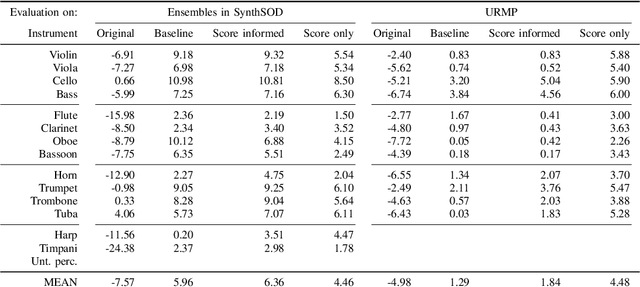
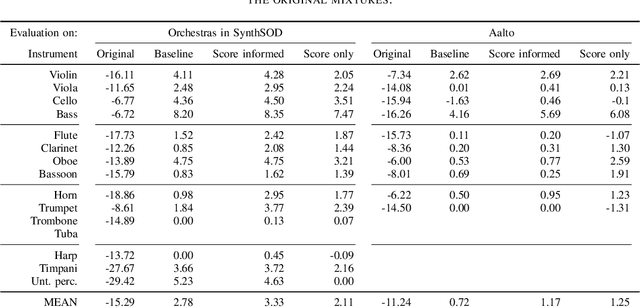
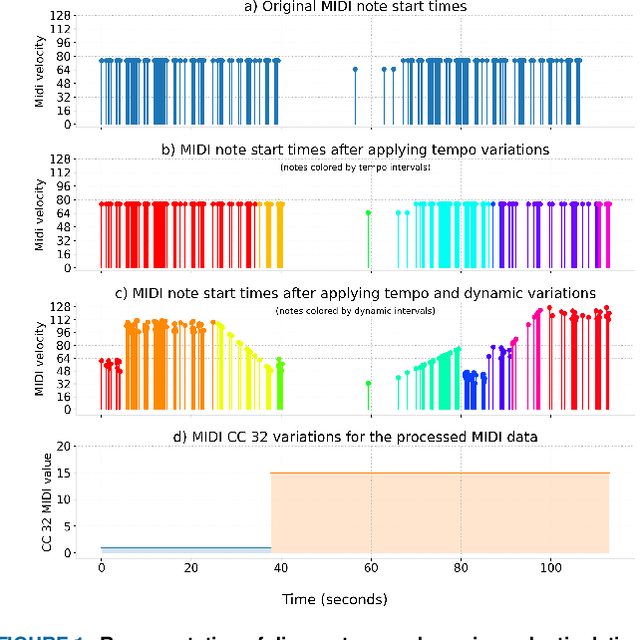
Music source separation is the task of separating a mixture of instruments into constituent tracks. Music source separation models are typically trained using only audio data, although additional information can be used to improve the model's separation capability. In this paper, we propose two ways of using musical scores to aid music source separation: a score-informed model where the score is concatenated with the magnitude spectrogram of the audio mixture as the input of the model, and a model where we use only the score to calculate the separation mask. We train our models on synthetic data in the SynthSOD dataset and evaluate our methods on the URMP and Aalto anechoic orchestra datasets, comprised of real recordings. The score-informed model improves separation results compared to a baseline approach, but struggles to generalize from synthetic to real data, whereas the score-only model shows a clear improvement in synthetic-to-real generalization.
SynthSOD: Developing an Heterogeneous Dataset for Orchestra Music Source Separation
Sep 17, 2024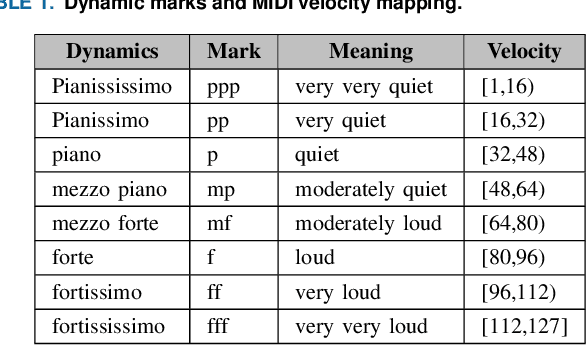
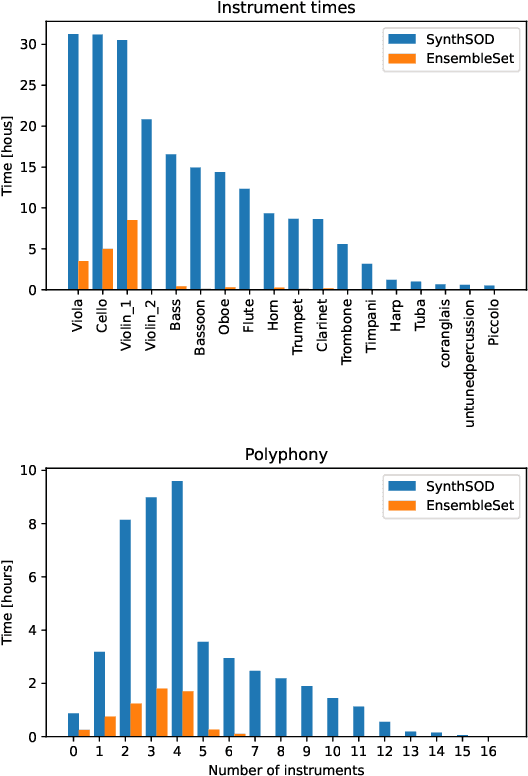
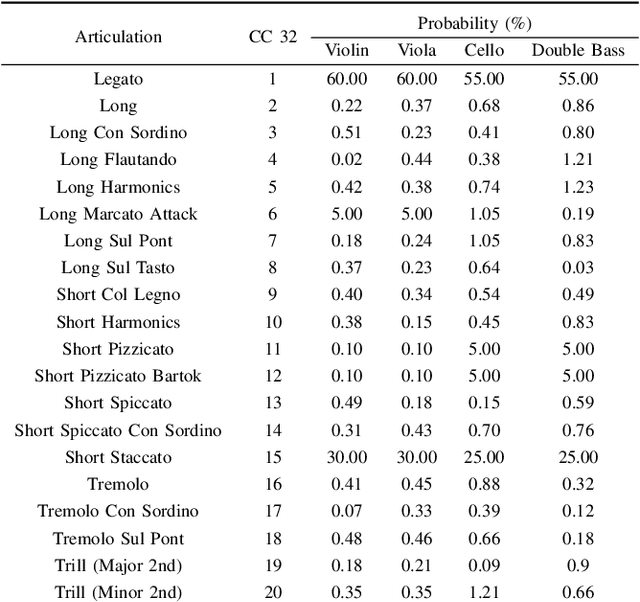
Recent advancements in music source separation have significantly progressed, particularly in isolating vocals, drums, and bass elements from mixed tracks. These developments owe much to the creation and use of large-scale, multitrack datasets dedicated to these specific components. However, the challenge of extracting similarly sounding sources from orchestra recordings has not been extensively explored, largely due to a scarcity of comprehensive and clean (i.e bleed-free) multitrack datasets. In this paper, we introduce a novel multitrack dataset called SynthSOD, developed using a set of simulation techniques to create a realistic (i.e. using high-quality soundfonts), musically motivated, and heterogeneous training set comprising different dynamics, natural tempo changes, styles, and conditions. Moreover, we demonstrate the application of a widely used baseline music separation model trained on our synthesized dataset w.r.t to the well-known EnsembleSet, and evaluate its performance under both synthetic and real-world conditions.
Permutation Invariant Recurrent Neural Networks for Sound Source Tracking Applications
Jun 14, 2023



Many multi-source localization and tracking models based on neural networks use one or several recurrent layers at their final stages to track the movement of the sources. Conventional recurrent neural networks (RNNs), such as the long short-term memories (LSTMs) or the gated recurrent units (GRUs), take a vector as their input and use another vector to store their state. However, this approach results in the information from all the sources being contained in a single ordered vector, which is not optimal for permutation-invariant problems such as multi-source tracking. In this paper, we present a new recurrent architecture that uses unordered sets to represent both its input and its state and that is invariant to the permutations of the input set and equivariant to the permutations of the state set. Hence, the information of every sound source is represented in an individual embedding and the new estimates are assigned to the tracked trajectories regardless of their order.
Position tracking of a varying number of sound sources with sliding permutation invariant training
Oct 26, 2022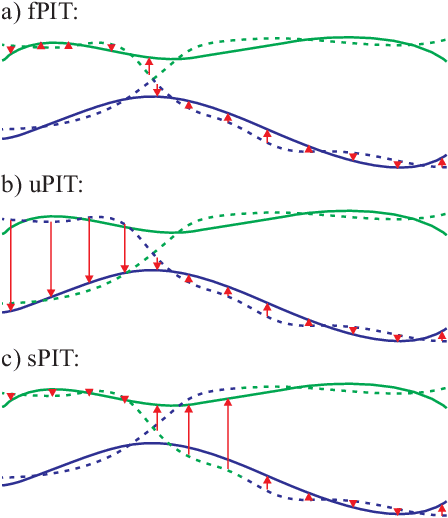
Recent data- and learning-based sound source localization (SSL) methods have shown strong performance in challenging acoustic scenarios. However, little work has been done on adapting such methods to track consistently multiple sources appearing and disappearing, as would occur in reality. In this paper, we present a new training strategy for deep learning SSL models with a straightforward implementation based on the mean squared error of the optimal association between estimated and reference positions in the preceding time frames. It optimizes the desired properties of a tracking system: handling a time-varying number of sources and ordering localization estimates according to their trajectories, minimizing identity switches (IDSs). Evaluation on simulated data of multiple reverberant moving sources and on two model architectures proves its effectiveness on reducing identity switches without compromising frame-wise localization accuracy.
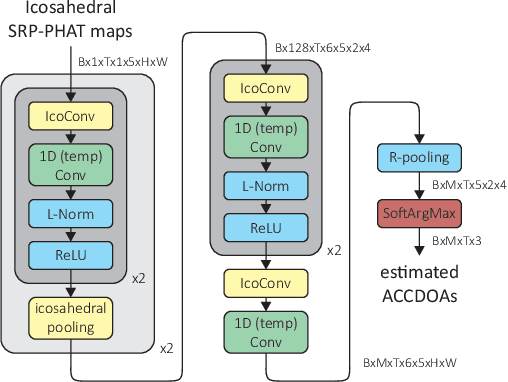
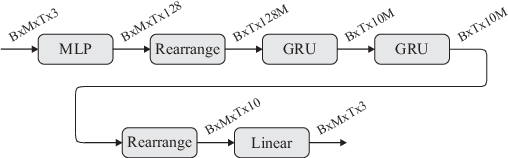
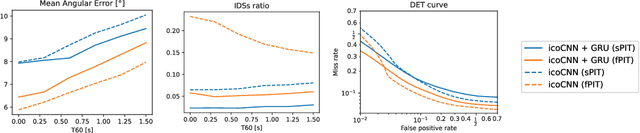
Direction of Arrival Estimation of Sound Sources Using Icosahedral CNNs
Mar 31, 2022
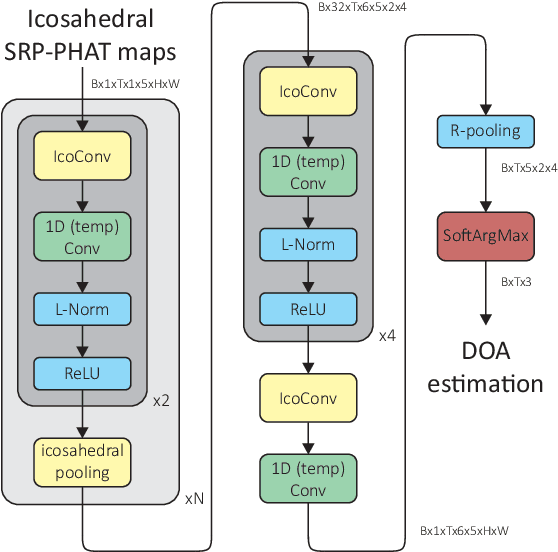
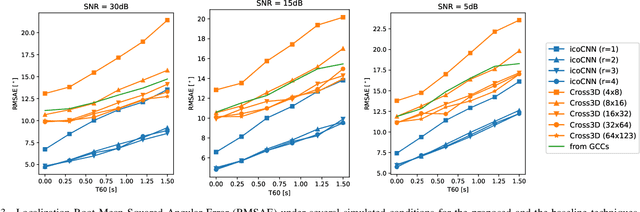
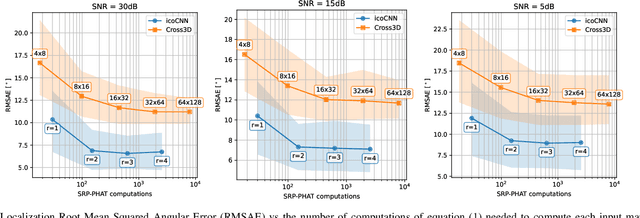
In this paper, we present a new model for Direction of Arrival (DOA) estimation of sound sources based on an Icosahedral Convolutional Neural Network (CNN) applied over SRP-PHAT power maps computed from the signals received by a microphone array. This icosahedral CNN is equivariant to the 60 rotational symmetries of the icosahedron, which represent a good approximation of the continuous space of spherical rotations, and can be implemented using standard 2D convolutional layers, having a lower computational cost than most of the spherical CNNs. In addition, instead of using fully connected layers after the icosahedral convolutions, we propose a new soft-argmax function that can be seen as a differentiable version of the argmax function and allows us to solve the DOA estimation as a regression problem interpreting the output of the convolutional layers as a probability distribution. We prove that using models that fit the equivariances of the problem allows us to outperform other state-of-the-art models with a lower computational cost and more robustness, obtaining root mean square localization errors lower than 10{\deg} even in scenarios with a reverberation time $T_{60}$ of 1.5 s.
Music Boundary Detection using Convolutional Neural Networks: A comparative analysis of combined input features
Aug 17, 2020
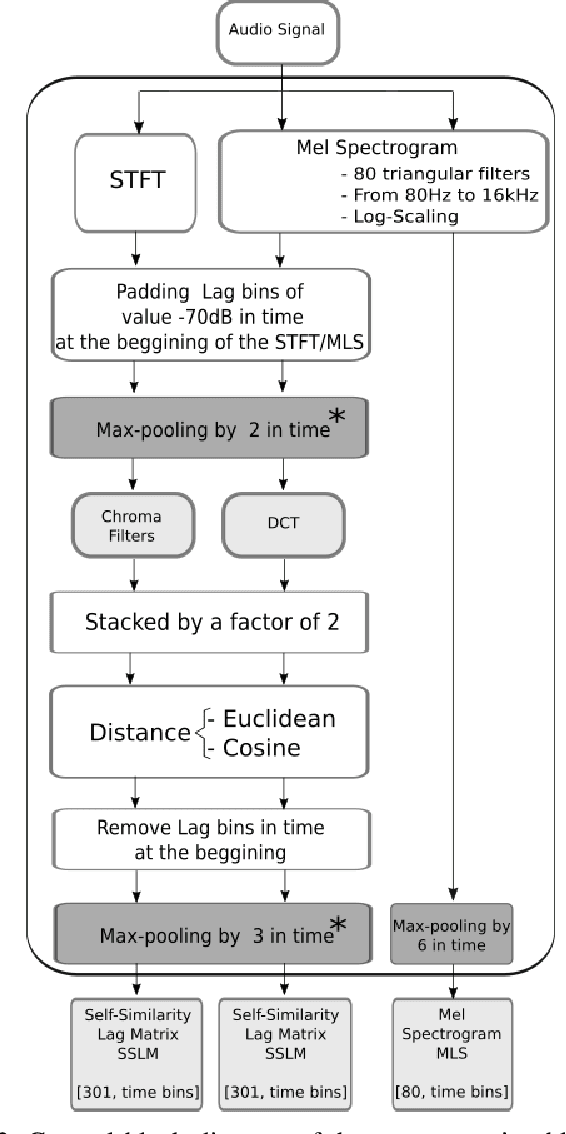
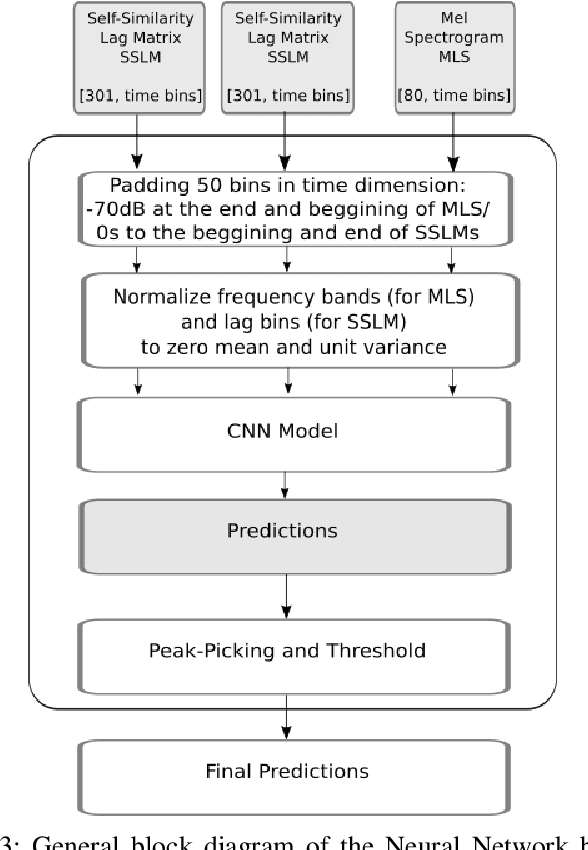
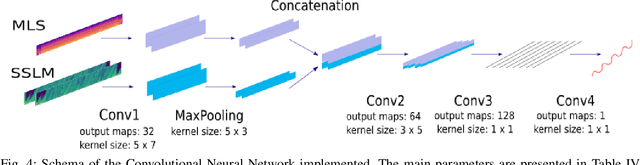
The analysis of the structure of musical pieces is a task that remains a challenge for Artificial Intelligence, especially in the field of Deep Learning. It requires prior identification of structural boundaries of the music pieces. This structural boundary analysis has recently been studied with unsupervised methods and \textit{end-to-end} techniques such as Convolutional Neural Networks (CNN) using Mel-Scaled Log-magnitude Spectograms features (MLS), Self-Similarity Matrices (SSM) or Self-Similarity Lag Matrices (SSLM) as inputs and trained with human annotations. Several studies have been published divided into unsupervised and \textit{end-to-end} methods in which pre-processing is done in different ways, using different distance metrics and audio characteristics, so a generalized pre-processing method to compute model inputs is missing. The objective of this work is to establish a general method of pre-processing these inputs by comparing the inputs calculated from different pooling strategies, distance metrics and audio characteristics, also taking into account the computing time to obtain them. We also establish the most effective combination of inputs to be delivered to the CNN in order to establish the most efficient way to extract the limits of the structure of the music pieces. With an adequate combination of input matrices and pooling strategies we obtain a measurement accuracy $F_1$ of 0.411 that outperforms the current one obtained under the same conditions.
Robust Sound Source Tracking Using SRP-PHAT and 3D Convolutional Neural Networks
Jun 16, 2020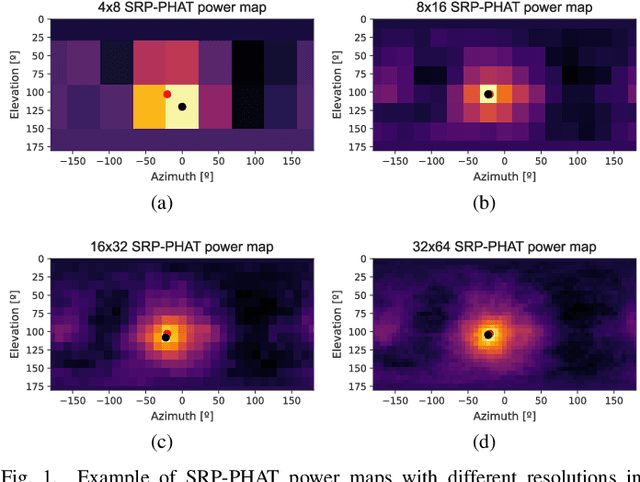
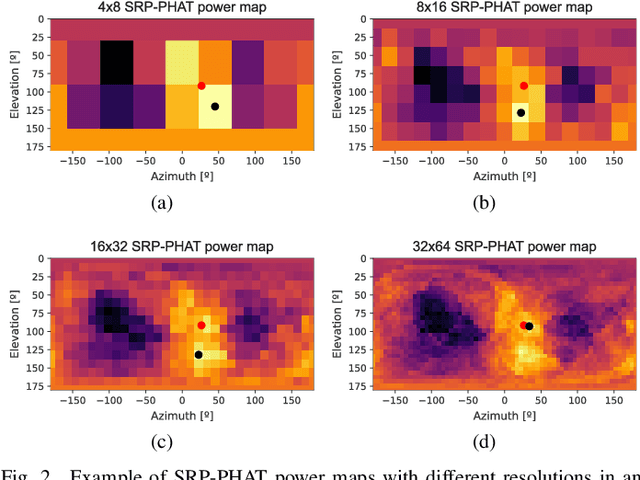
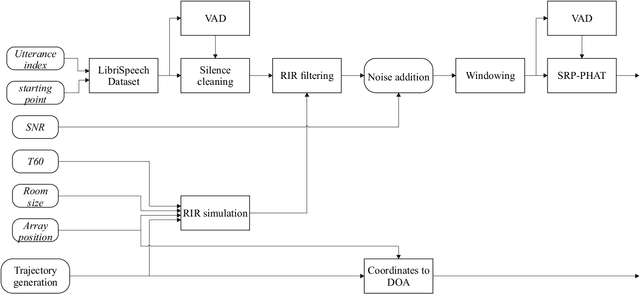
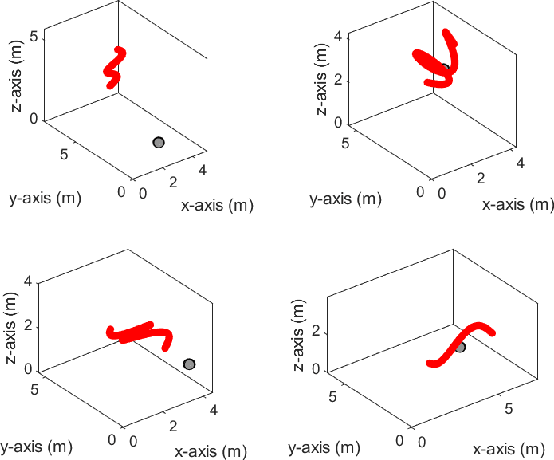
In this paper, we present a new sound source DOA estimation and tracking system based on the well known SRP-PHAT algorithm and a three-dimensional Convolutional Neural Network. It uses SRP-PHAT power maps as input features of a fully convolutional causal architecture that uses 3D convolutional layers to accurately perform the tracking of a sound source even in highly reverberant scenarios where most of the state of the art techniques fail. Unlike previous methods, since we do not use bidirectional recurrent layers and all our convolutional layers are causal in the time dimension, our system is feasible for real-time applications and it provides a new DOA estimation for each new SRP-PHAT map. To train the model, we introduce a new procedure to simulate random trajectories as they are needed during the training, equivalent to an infinite-size dataset with high flexibility to modify its acoustical conditions such as the reverberation time. We use both acoustical simulations on a large range of reverberation times and the actual recordings of the LOCATA dataset to prove the robustness of our system and its good performance even using low-resolution SRP-PHAT maps.