 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription and Discussion on DCASE 2026 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Apr 01, 2026This paper presents an overview of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2026 Challenge Task 4, Spatial Semantic Segmentation of Sound Scenes (S5). The S5 task focuses on the joint detection and separation of sound events in complex spatial audio mixtures, contributing to the foundation of immersive communication. First introduced in DCASE 2025, the S5 task continues in DCASE 2026 Task 4 with key changes to better reflect real-world conditions, including allowing mixtures to contain multiple sources of the same class and to contain no target sources. In this paper, we describe task setting, along with the corresponding updates to the evaluation metrics and dataset. The experimental results of the submitted systems are also reported and analyzed. The official access point for data and code is https://github.com/nttcslab/dcase2026_task4_baseline.
Interaural time difference loss for binaural target sound extraction
Aug 01, 2024

Binaural target sound extraction (TSE) aims to extract a desired sound from a binaural mixture of arbitrary sounds while preserving the spatial cues of the desired sound. Indeed, for many applications, the target sound signal and its spatial cues carry important information about the sound source. Binaural TSE can be realized with a neural network trained to output only the desired sound given a binaural mixture and an embedding characterizing the desired sound class as inputs. Conventional TSE systems are trained using signal-level losses, which measure the difference between the extracted and reference signals for the left and right channels. In this paper, we propose adding explicit spatial losses to better preserve the spatial cues of the target sound. In particular, we explore losses aiming at preserving the interaural level (ILD), phase (IPD), and time differences (ITD). We show experimentally that adding such spatial losses, particularly our newly proposed ITD loss, helps preserve better spatial cues while maintaining the signal-level metrics.
VRDMG: Vocal Restoration via Diffusion Posterior Sampling with Multiple Guidance
Sep 13, 2023Restoring degraded music signals is essential to enhance audio quality for downstream music manipulation. Recent diffusion-based music restoration methods have demonstrated impressive performance, and among them, diffusion posterior sampling (DPS) stands out given its intrinsic properties, making it versatile across various restoration tasks. In this paper, we identify that there are potential issues which will degrade current DPS-based methods' performance and introduce the way to mitigate the issues inspired by diverse diffusion guidance techniques including the RePaint (RP) strategy and the Pseudoinverse-Guided Diffusion Models ($\Pi$GDM). We demonstrate our methods for the vocal declipping and bandwidth extension tasks under various levels of distortion and cutoff frequency, respectively. In both tasks, our methods outperform the current DPS-based music restoration benchmarks. We refer to \url{http://carlosholivan.github.io/demos/audio-restoration-2023.html} for examples of the restored audio samples.
Symbolic Music Structure Analysis with Graph Representations and Changepoint Detection Methods
Mar 24, 2023



Music Structure Analysis is an open research task in Music Information Retrieval (MIR). In the past, there have been several works that attempt to segment music into the audio and symbolic domains, however, the identification and segmentation of the music structure at different levels is still an open research problem in this area. In this work we propose three methods, two of which are novel graph-based algorithms that aim to segment symbolic music by its form or structure: Norm, G-PELT and G-Window. We performed an ablation study with two public datasets that have different forms or structures in order to compare such methods varying their parameter values and comparing the performance against different music styles. We have found that encoding symbolic music with graph representations and computing the novelty of Adjacency Matrices obtained from graphs represent the structure of symbolic music pieces well without the need to extract features from it. We are able to detect the boundaries with an online unsupervised changepoint detection method with a F_1 of 0.5640 for a 1 bar tolerance in one of the public datasets that we used for testing our methods. We also provide the performance results of the algorithms at different levels of structure, high, medium and low, to show how the parameters of the proposed methods have to be adjusted depending on the level. We added the best performing method with its parameters for each structure level to musicaiz, an open source python package, to facilitate the reproducibility and usability of this work. We hope that this methods could be used to improve other MIR tasks such as music generation with structure, music classification or key changes detection.
A Survey on Artificial Intelligence for Music Generation: Agents, Domains and Perspectives
Nov 03, 2022Music is one of the Gardner's intelligences in his theory of multiple intelligences. How humans perceive and understand music is still being studied and is crucial to develop artificial intelligence models that imitate such processes. Music generation with Artificial Intelligence is an emerging field that is gaining much attention in the recent years. In this paper, we describe how humans compose music and how new AI systems could imitate such process by comparing past and recent advances in the field with music composition techniques. To understand how AI models and algorithms generate music and the potential applications that might appear in the future, we explore, analyze and describe the agents that take part of the music generation process: the datasets, models, interfaces, the users and the generated music. We mention possible applications that might benefit from this field and we also propose new trends and future research directions that could be explored in the future.
musicaiz: A Python Library for Symbolic Music Generation, Analysis and Visualization
Sep 16, 2022
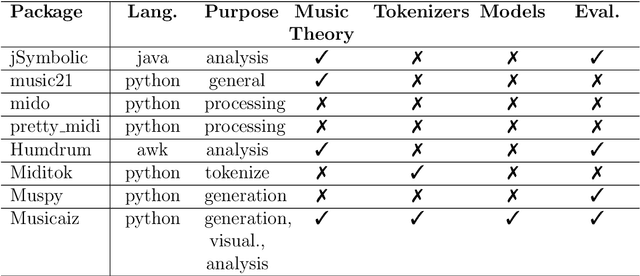

In this article, we present musicaiz, an object-oriented library for analyzing, generating and evaluating symbolic music. The submodules of the package allow the user to create symbolic music data from scratch, build algorithms to analyze symbolic music, encode MIDI data as tokens to train deep learning sequence models, modify existing music data and evaluate music generation systems. The evaluation submodule builds on previous work to objectively measure music generation systems and to be able to reproduce the results of music generation models. The library is publicly available online. We encourage the community to contribute and provide feedback.
Subjective Evaluation of Deep Learning Models for Symbolic Music Composition
Apr 03, 2022
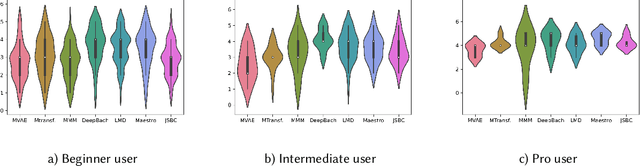
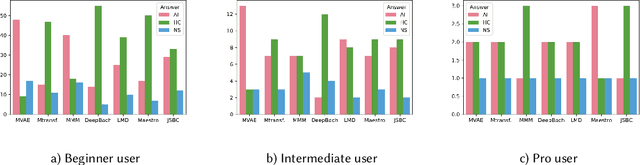
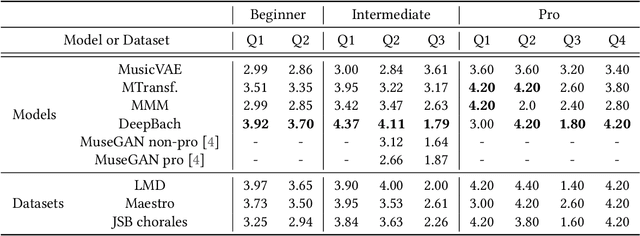
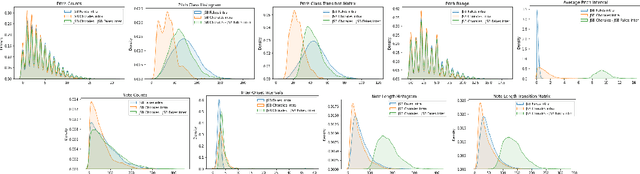
Deep learning models are typically evaluated to measure and compare their performance on a given task. The metrics that are commonly used to evaluate these models are standard metrics that are used for different tasks. In the field of music composition or generation, the standard metrics used in other fields have no clear meaning in terms of music theory. In this paper, we propose a subjective method to evaluate AI-based music composition systems by asking questions related to basic music principles to different levels of users based on their musical experience and knowledge. We use this method to compare state-of-the-art models for music composition with deep learning. We give the results of this evaluation method and we compare the responses of each user level for each evaluated model.
Music Composition with Deep Learning: A Review
Sep 07, 2021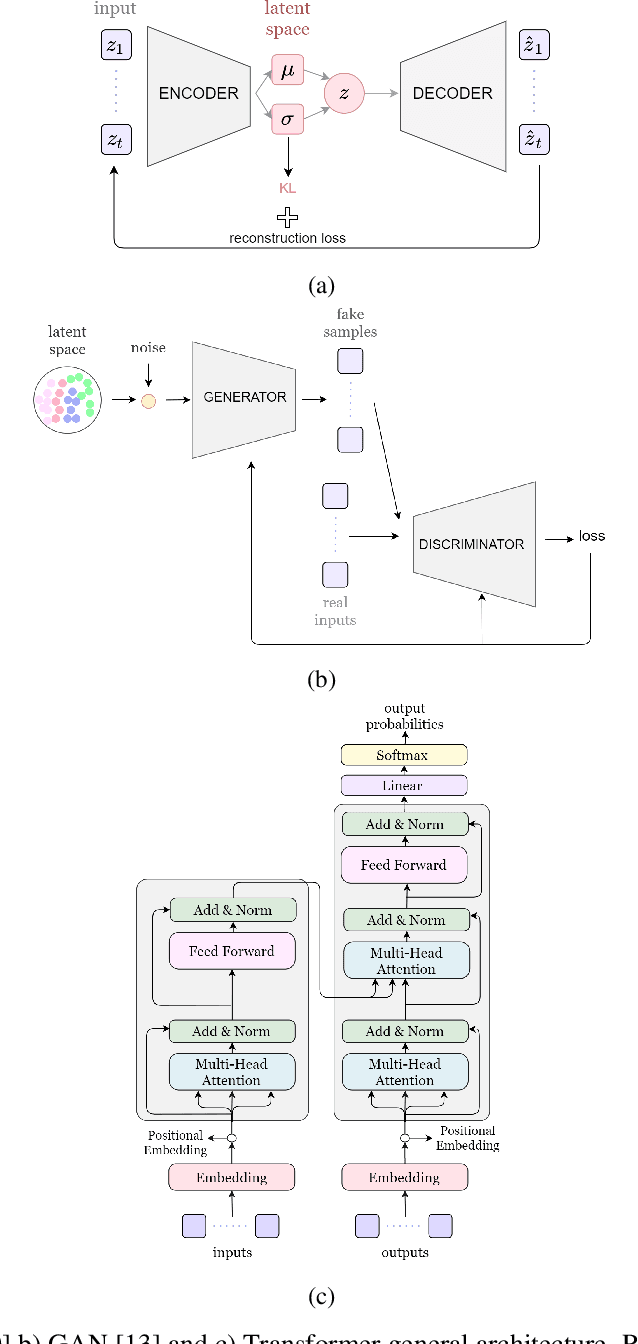
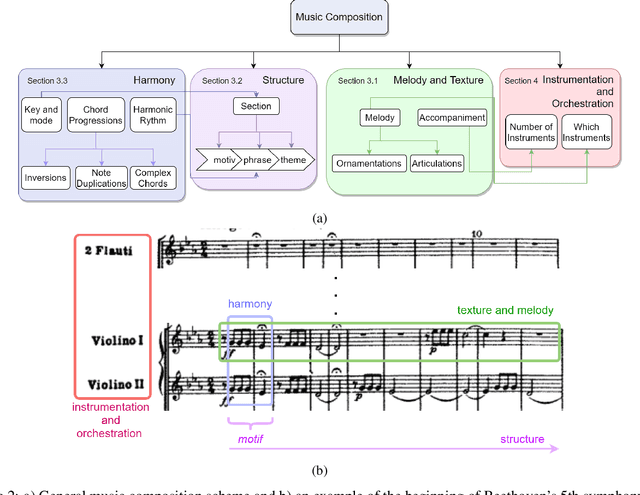
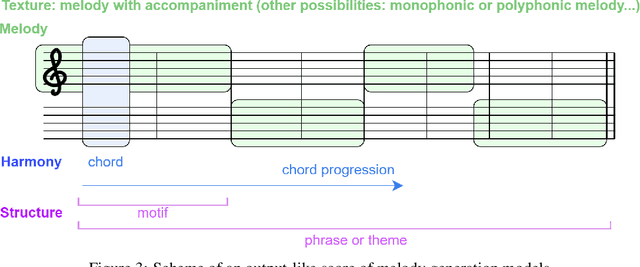
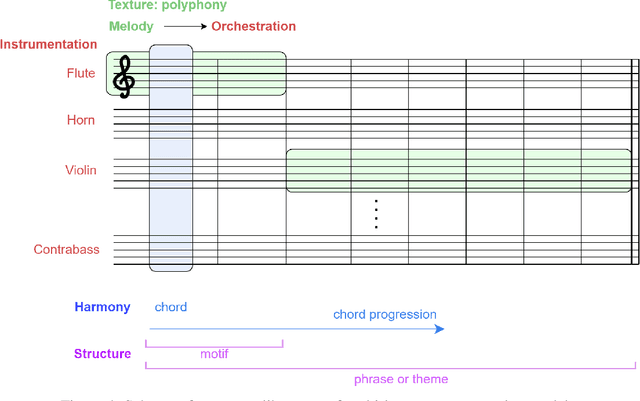
Generating a complex work of art such as a musical composition requires exhibiting true creativity that depends on a variety of factors that are related to the hierarchy of musical language. Music generation have been faced with Algorithmic methods and recently, with Deep Learning models that are being used in other fields such as Computer Vision. In this paper we want to put into context the existing relationships between AI-based music composition models and human musical composition and creativity processes. We give an overview of the recent Deep Learning models for music composition and we compare these models to the music composition process from a theoretical point of view. We have tried to answer some of the most relevant open questions for this task by analyzing the ability of current Deep Learning models to generate music with creativity or the similarity between AI and human composition processes, among others.
Timbre Classification of Musical Instruments with a Deep Learning Multi-Head Attention-Based Model
Jul 13, 2021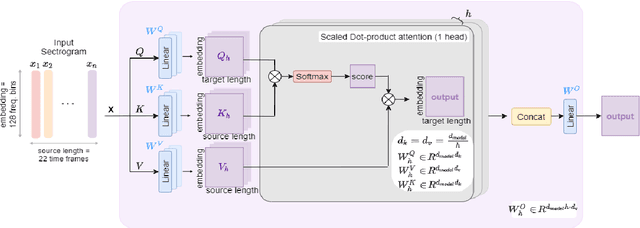
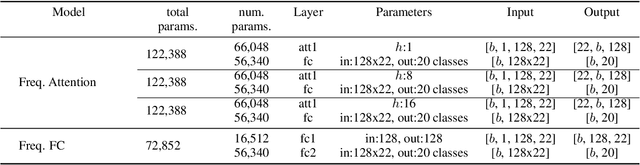
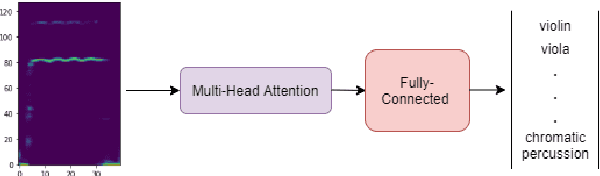
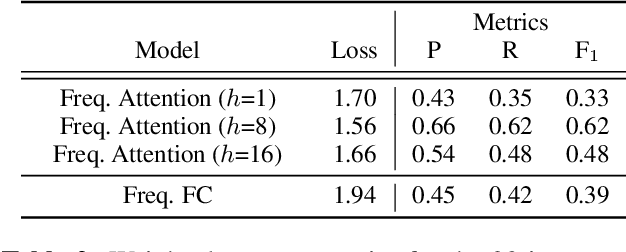
The aim of this work is to define a model based on deep learning that is able to identify different instrument timbres with as few parameters as possible. For this purpose, we have worked with classical orchestral instruments played with different dynamics, which are part of a few instrument families and which play notes in the same pitch range. It has been possible to assess the ability to classify instruments by timbre even if the instruments are playing the same note with the same intensity. The network employed uses a multi-head attention mechanism, with 8 heads and a dense network at the output taking as input the log-mel magnitude spectrograms of the sound samples. This network allows the identification of 20 instrument classes of the classical orchestra, achieving an overall F$_1$ value of 0.62. An analysis of the weights of the attention layer has been performed and the confusion matrix of the model is presented, allowing us to assess the ability of the proposed architecture to distinguish timbre and to establish the aspects on which future work should focus.
Music Boundary Detection using Convolutional Neural Networks: A comparative analysis of combined input features
Aug 17, 2020
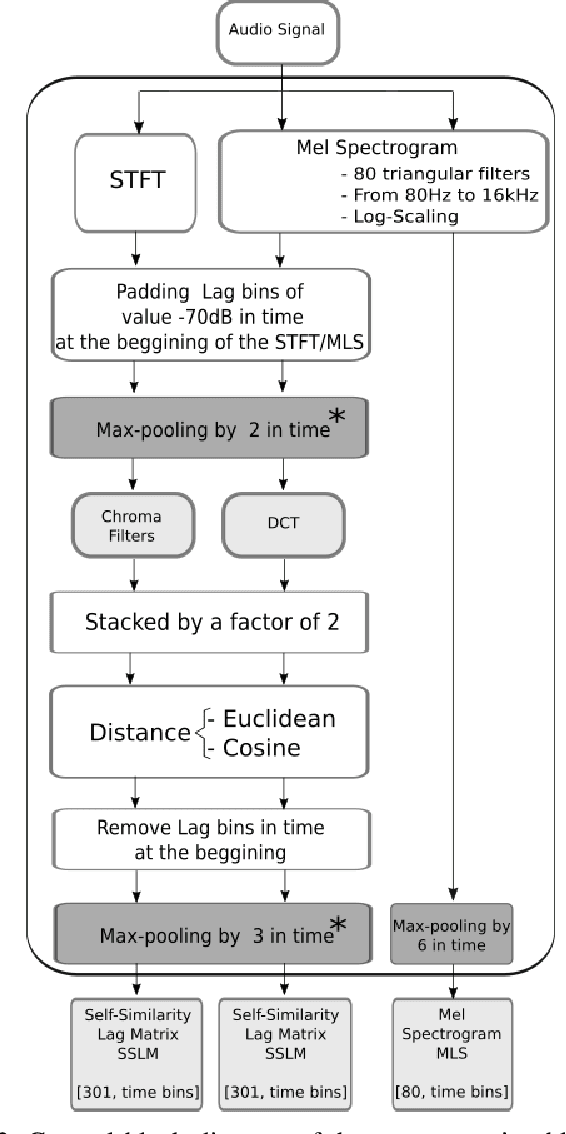
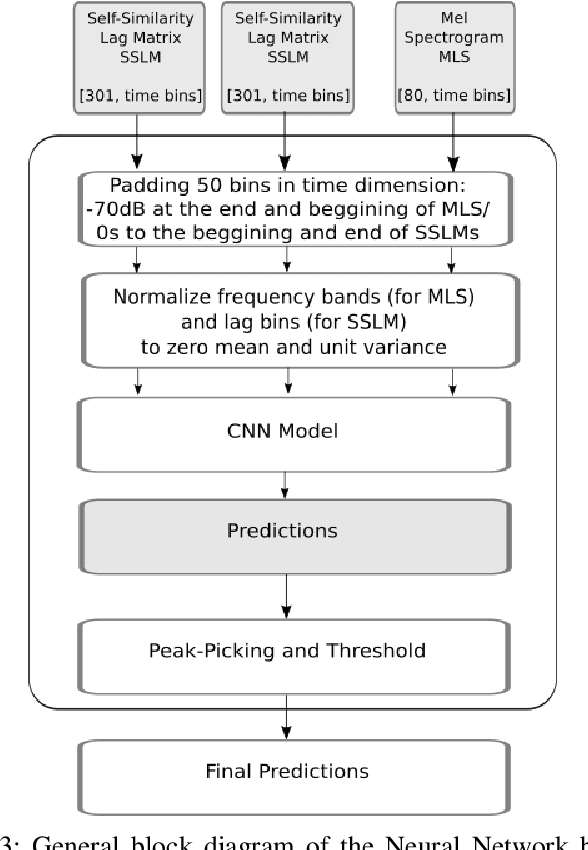
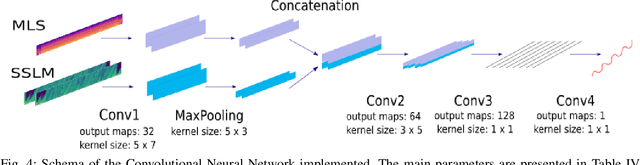
The analysis of the structure of musical pieces is a task that remains a challenge for Artificial Intelligence, especially in the field of Deep Learning. It requires prior identification of structural boundaries of the music pieces. This structural boundary analysis has recently been studied with unsupervised methods and \textit{end-to-end} techniques such as Convolutional Neural Networks (CNN) using Mel-Scaled Log-magnitude Spectograms features (MLS), Self-Similarity Matrices (SSM) or Self-Similarity Lag Matrices (SSLM) as inputs and trained with human annotations. Several studies have been published divided into unsupervised and \textit{end-to-end} methods in which pre-processing is done in different ways, using different distance metrics and audio characteristics, so a generalized pre-processing method to compute model inputs is missing. The objective of this work is to establish a general method of pre-processing these inputs by comparing the inputs calculated from different pooling strategies, distance metrics and audio characteristics, also taking into account the computing time to obtain them. We also establish the most effective combination of inputs to be delivered to the CNN in order to establish the most efficient way to extract the limits of the structure of the music pieces. With an adequate combination of input matrices and pooling strategies we obtain a measurement accuracy $F_1$ of 0.411 that outperforms the current one obtained under the same conditions.