 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription and Discussion on DCASE 2026 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Apr 01, 2026This paper presents an overview of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2026 Challenge Task 4, Spatial Semantic Segmentation of Sound Scenes (S5). The S5 task focuses on the joint detection and separation of sound events in complex spatial audio mixtures, contributing to the foundation of immersive communication. First introduced in DCASE 2025, the S5 task continues in DCASE 2026 Task 4 with key changes to better reflect real-world conditions, including allowing mixtures to contain multiple sources of the same class and to contain no target sources. In this paper, we describe task setting, along with the corresponding updates to the evaluation metrics and dataset. The experimental results of the submitted systems are also reported and analyzed. The official access point for data and code is https://github.com/nttcslab/dcase2026_task4_baseline.
Joint Enhancement and Classification using Coupled Diffusion Models of Signals and Logits
Feb 17, 2026Robust classification in noisy environments remains a fundamental challenge in machine learning. Standard approaches typically treat signal enhancement and classification as separate, sequential stages: first enhancing the signal and then applying a classifier. This approach fails to leverage the semantic information in the classifier's output during denoising. In this work, we propose a general, domain-agnostic framework that integrates two interacting diffusion models: one operating on the input signal and the other on the classifier's output logits, without requiring any retraining or fine-tuning of the classifier. This coupled formulation enables mutual guidance, where the enhancing signal refines the class estimation and, conversely, the evolving class logits guide the signal reconstruction towards discriminative regions of the manifold. We introduce three strategies to effectively model the joint distribution of the input and the logit. We evaluated our joint enhancement method for image classification and automatic speech recognition. The proposed framework surpasses traditional sequential enhancement baselines, delivering robust and flexible improvements in classification accuracy under diverse noise conditions.
Loose coupling of spectral and spatial models for multi-channel diarization and enhancement of meetings in dynamic environments
Jan 22, 2026Sound capture by microphone arrays opens the possibility to exploit spatial, in addition to spectral, information for diarization and signal enhancement, two important tasks in meeting transcription. However, there is no one-to-one mapping of positions in space to speakers if speakers move. Here, we address this by proposing a novel joint spatial and spectral mixture model, whose two submodels are loosely coupled by modeling the relationship between speaker and position index probabilistically. Thus, spatial and spectral information can be jointly exploited, while at the same time allowing for speakers speaking from different positions. Experiments on the LibriCSS data set with simulated speaker position changes show great improvements over tightly coupled subsystems.
Reference Microphone Selection for Guided Source Separation based on the Normalized L-p Norm
Oct 31, 2025



Guided Source Separation (GSS) is a popular front-end for distant automatic speech recognition (ASR) systems using spatially distributed microphones. When considering spatially distributed microphones, the choice of reference microphone may have a large influence on the quality of the output signal and the downstream ASR performance. In GSS-based speech enhancement, reference microphone selection is typically performed using the signal-to-noise ratio (SNR), which is optimal for noise reduction but may neglect differences in early-to-late-reverberant ratio (ELR) across microphones. In this paper, we propose two reference microphone selection methods for GSS-based speech enhancement that are based on the normalized $\ell_p$-norm, either using only the normalized $\ell_p$-norm or combining the normalized $\ell_p$-norm and the SNR to account for both differences in SNR and ELR across microphones. Experimental evaluation using a CHiME-8 distant ASR system shows that the proposed $\ell_p$-norm-based methods outperform the baseline method, reducing the macro-average word error rate.
MOVER: Combining Multiple Meeting Recognition Systems
Aug 07, 2025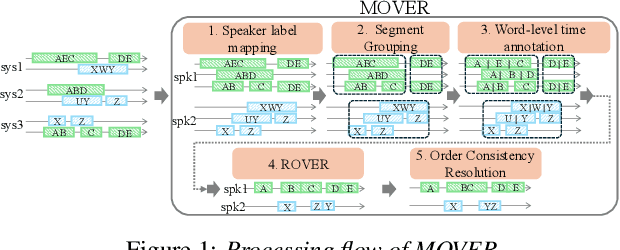


In this paper, we propose Meeting recognizer Output Voting Error Reduction (MOVER), a novel system combination method for meeting recognition tasks. Although there are methods to combine the output of diarization (e.g., DOVER) or automatic speech recognition (ASR) systems (e.g., ROVER), MOVER is the first approach that can combine the outputs of meeting recognition systems that differ in terms of both diarization and ASR. MOVER combines hypotheses with different time intervals and speaker labels through a five-stage process that includes speaker alignment, segment grouping, word and timing combination, etc. Experimental results on the CHiME-8 DASR task and the multi-channel track of the NOTSOFAR-1 task demonstrate that MOVER can successfully combine multiple meeting recognition systems with diverse diarization and recognition outputs, achieving relative tcpWER improvements of 9.55 % and 8.51 % over the state-of-the-art systems for both tasks.
Description and Discussion on DCASE 2025 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Jun 12, 2025


Spatial Semantic Segmentation of Sound Scenes (S5) aims to enhance technologies for sound event detection and separation from multi-channel input signals that mix multiple sound events with spatial information. This is a fundamental basis of immersive communication. The ultimate goal is to separate sound event signals with 6 Degrees of Freedom (6DoF) information into dry sound object signals and metadata about the object type (sound event class) and representing spatial information, including direction. However, because several existing challenge tasks already provide some of the subset functions, this task for this year focuses on detecting and separating sound events from multi-channel spatial input signals. This paper outlines the S5 task setting of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge Task 4 and the DCASE2025 Task 4 Dataset, newly recorded and curated for this task. We also report experimental results for an S5 system trained and evaluated on this dataset. The full version of this paper will be published after the challenge results are made public.
Microphone Array Signal Processing and Deep Learning for Speech Enhancement
Jan 13, 2025



Multi-channel acoustic signal processing is a well-established and powerful tool to exploit the spatial diversity between a target signal and non-target or noise sources for signal enhancement. However, the textbook solutions for optimal data-dependent spatial filtering rest on the knowledge of second-order statistical moments of the signals, which have traditionally been difficult to acquire. In this contribution, we compare model-based, purely data-driven, and hybrid approaches to parameter estimation and filtering, where the latter tries to combine the benefits of model-based signal processing and data-driven deep learning to overcome their individual deficiencies. We illustrate the underlying design principles with examples from noise reduction, source separation, and dereverberation.
* Accepted for IEEE Signal Processing Magazine
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024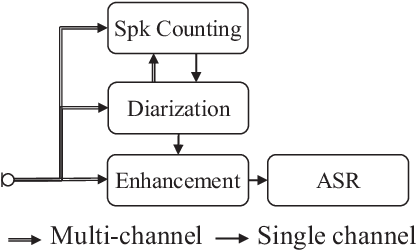
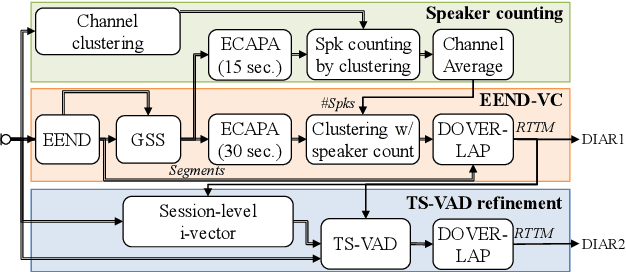

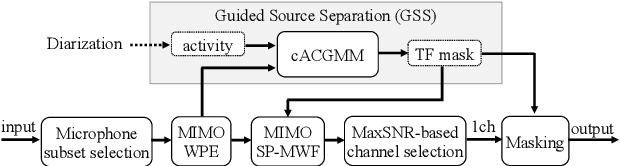
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Interaural time difference loss for binaural target sound extraction
Aug 01, 2024

Binaural target sound extraction (TSE) aims to extract a desired sound from a binaural mixture of arbitrary sounds while preserving the spatial cues of the desired sound. Indeed, for many applications, the target sound signal and its spatial cues carry important information about the sound source. Binaural TSE can be realized with a neural network trained to output only the desired sound given a binaural mixture and an embedding characterizing the desired sound class as inputs. Conventional TSE systems are trained using signal-level losses, which measure the difference between the extracted and reference signals for the left and right channels. In this paper, we propose adding explicit spatial losses to better preserve the spatial cues of the target sound. In particular, we explore losses aiming at preserving the interaural level (ILD), phase (IPD), and time differences (ITD). We show experimentally that adding such spatial losses, particularly our newly proposed ITD loss, helps preserve better spatial cues while maintaining the signal-level metrics.
Array Geometry-Robust Attention-Based Neural Beamformer for Moving Speakers
Feb 05, 2024Recently, a mask-based beamformer with attention-based spatial covariance matrix aggregator (ASA) was proposed, which was demonstrated to track moving sources accurately. However, the deep neural network model used in this algorithm is limited to a specific channel configuration, requiring a different model in case a different channel permutation, channel count, or microphone array geometry is considered. Addressing this limitation, in this paper, we investigate three approaches to improve the robustness of the ASA-based tracking method against such variations: incorporating random channel configurations during the training process, employing the transform-average-concatenate (TAC) method to process multi-channel input features (allowing for any channel count and enabling permutation invariance), and utilizing input features that are robust against variations of the channel configuration. Our experiments, conducted using the CHiME-3 and DEMAND datasets, demonstrate improved robustness against mismatches in channel permutations, channel counts, and microphone array geometries compared to the conventional ASA-based tracking method without compromising performance in matched conditions, suggesting that the mask-based beamformer with ASA integrating the proposed approaches has the potential to track moving sources for arbitrary microphone arrays.