 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive-Generative Drift Decomposition for Speech Enhancement and Separation
May 07, 2026We propose a plug-and-play framework for speech enhancement and separation that augments predictive methods with a generative speech prior. Our approach, termed Stochastic Interpolant Prior for Speech (SIPS), builds on stochastic interpolants and leverages their flexibility to bridge predictive and generative modeling. Specifically, we decompose the interpolation dynamics into a task-specific drift and a stochastic denoising component, allowing a predictive estimate to be integrated directly into the generative sampling process. This results in a mathematically grounded framework for combining strong pretrained predictors with the expressive power of generative models. To this end, we train a score model using only clean speech, yielding a degradation-agnostic prior that can be reused across tasks. During inference, the predictor provides a deterministic drift that steers the sampling process toward a task-consistent estimate, while the score model preserves perceptual naturalness. Unlike prior hybrid approaches, which typically rely on architecture-specific conditioning and are tied to particular predictors or degradation settings, SIPS provides a unified framework that generalizes across predictors and additive degradation tasks. We demonstrate its effectiveness for both speech enhancement and speech separation using recent predictors such as SEMamba and FlexIO. The proposed method consistently improves perceptual quality, achieving gains up +1.0 NISQA for speech separation.
Loose coupling of spectral and spatial models for multi-channel diarization and enhancement of meetings in dynamic environments
Jan 22, 2026Sound capture by microphone arrays opens the possibility to exploit spatial, in addition to spectral, information for diarization and signal enhancement, two important tasks in meeting transcription. However, there is no one-to-one mapping of positions in space to speakers if speakers move. Here, we address this by proposing a novel joint spatial and spectral mixture model, whose two submodels are loosely coupled by modeling the relationship between speaker and position index probabilistically. Thus, spatial and spectral information can be jointly exploited, while at the same time allowing for speakers speaking from different positions. Experiments on the LibriCSS data set with simulated speaker position changes show great improvements over tightly coupled subsystems.
Microphone Array Signal Processing and Deep Learning for Speech Enhancement
Jan 13, 2025



Multi-channel acoustic signal processing is a well-established and powerful tool to exploit the spatial diversity between a target signal and non-target or noise sources for signal enhancement. However, the textbook solutions for optimal data-dependent spatial filtering rest on the knowledge of second-order statistical moments of the signals, which have traditionally been difficult to acquire. In this contribution, we compare model-based, purely data-driven, and hybrid approaches to parameter estimation and filtering, where the latter tries to combine the benefits of model-based signal processing and data-driven deep learning to overcome their individual deficiencies. We illustrate the underlying design principles with examples from noise reduction, source separation, and dereverberation.
* Accepted for IEEE Signal Processing Magazine
Simultaneous Diarization and Separation of Meetings through the Integration of Statistical Mixture Models
Oct 28, 2024


We propose an approach for simultaneous diarization and separation of meeting data. It consists of a complex Angular Central Gaussian Mixture Model (cACGMM) for speech source separation, and a von-Mises-Fisher Mixture Model (VMFMM) for diarization in a joint statistical framework. Through the integration, both spatial and spectral information are exploited for diarization and separation. We also develop a method for counting the number of active speakers in a segment of a meeting to support block-wise processing. While the total number of speakers in a meeting may be known, it is usually not known on a per-segment level. With the proposed speaker counting, joint diarization and source separation can be done segment-by-segment, and the permutation problem across segments is solved, thus allowing for block-online processing in the future. Experimental results on the LibriCSS meeting corpus show that the integrated approach outperforms a cascaded approach of diarization and speech enhancement in terms of WER, both on a per-segment and on a per-meeting level.
The CHiME-8 DASR Challenge for Generalizable and Array Agnostic Distant Automatic Speech Recognition and Diarization
Jul 23, 2024



This paper presents the CHiME-8 DASR challenge which carries on from the previous edition CHiME-7 DASR (C7DASR) and the past CHiME-6 challenge. It focuses on joint multi-channel distant speech recognition (DASR) and diarization with one or more, possibly heterogeneous, devices. The main goal is to spur research towards meeting transcription approaches that can generalize across arbitrary number of speakers, diverse settings (formal vs. informal conversations), meeting duration, wide-variety of acoustic scenarios and different recording configurations. Novelties with respect to C7DASR include: i) the addition of NOTSOFAR-1, an additional office/corporate meeting scenario, ii) a manually corrected Mixer 6 development set, iii) a new track in which we allow the use of large-language models (LLM) iv) a jury award mechanism to encourage participants to explore also more practical and innovative solutions. To lower the entry barrier for participants, we provide a standalone toolkit for downloading and preparing such datasets as well as performing text normalization and scoring their submissions. Furthermore, this year we also provide two baseline systems, one directly inherited from C7DASR and based on ESPnet and another one developed on NeMo and based on NeMo team submission in last year C7DASR. Baseline system results suggest that the addition of the NOTSOFAR-1 scenario significantly increases the task's difficulty due to its high number of speakers and very short duration.
Once more Diarization: Improving meeting transcription systems through segment-level speaker reassignment
Jun 05, 2024



Diarization is a crucial component in meeting transcription systems to ease the challenges of speech enhancement and attribute the transcriptions to the correct speaker. Particularly in the presence of overlapping or noisy speech, these systems have problems reliably assigning the correct speaker labels, leading to a significant amount of speaker confusion errors. We propose to add segment-level speaker reassignment to address this issue. By revisiting, after speech enhancement, the speaker attribution for each segment, speaker confusion errors from the initial diarization stage are significantly reduced. Through experiments across different system configurations and datasets, we further demonstrate the effectiveness and applicability in various domains. Our results show that segment-level speaker reassignment successfully rectifies at least 40% of speaker confusion word errors, highlighting its potential for enhancing diarization accuracy in meeting transcription systems.
Geodesic interpolation of frame-wise speaker embeddings for the diarization of meeting scenarios
Jan 08, 2024



We propose a modified teacher-student training for the extraction of frame-wise speaker embeddings that allows for an effective diarization of meeting scenarios containing partially overlapping speech. To this end, a geodesic distance loss is used that enforces the embeddings computed from regions with two active speakers to lie on the shortest path on a sphere between the points given by the d-vectors of each of the active speakers. Using those frame-wise speaker embeddings in clustering-based diarization outperforms segment-level clustering-based diarization systems such as VBx and Spectral Clustering. By extending our approach to a mixture-model-based diarization, the performance can be further improved, approaching the diarization error rates of diarization systems that use a dedicated overlap detection, and outperforming these systems when also employing an additional overlap detection.
Meeting Recognition with Continuous Speech Separation and Transcription-Supported Diarization
Sep 28, 2023We propose a modular pipeline for the single-channel separation, recognition, and diarization of meeting-style recordings and evaluate it on the Libri-CSS dataset. Using a Continuous Speech Separation (CSS) system with a TF-GridNet separation architecture, followed by a speaker-agnostic speech recognizer, we achieve state-of-the-art recognition performance in terms of Optimal Reference Combination Word Error Rate (ORC WER). Then, a d-vector-based diarization module is employed to extract speaker embeddings from the enhanced signals and to assign the CSS outputs to the correct speaker. Here, we propose a syntactically informed diarization using sentence- and word-level boundaries of the ASR module to support speaker turn detection. This results in a state-of-the-art Concatenated minimum-Permutation Word Error Rate (cpWER) for the full meeting recognition pipeline.
Mixture Encoder Supporting Continuous Speech Separation for Meeting Recognition
Sep 15, 2023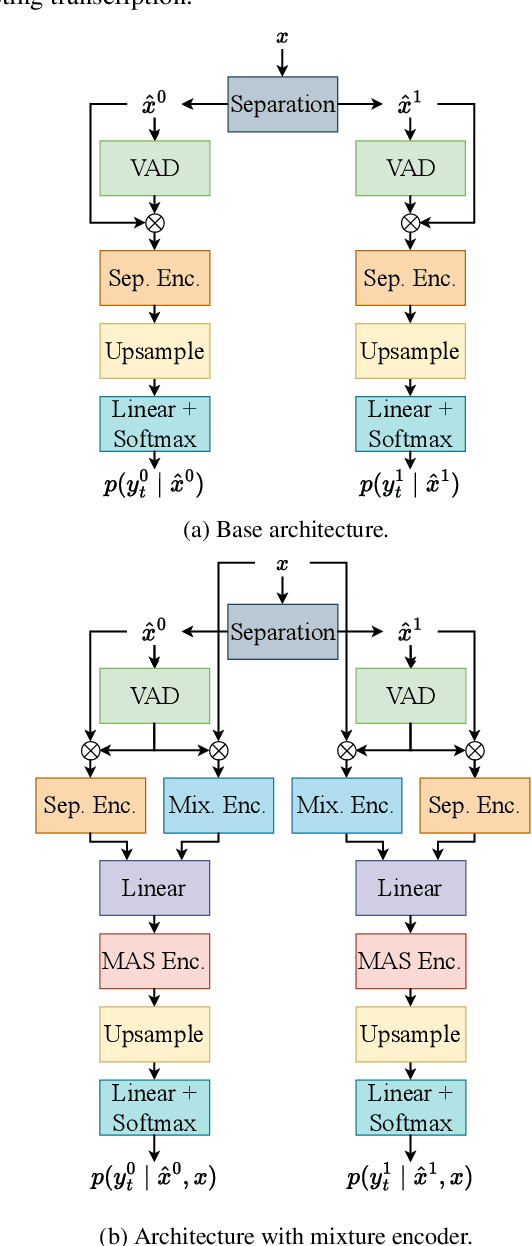



Many real-life applications of automatic speech recognition (ASR) require processing of overlapped speech. A commonmethod involves first separating the speech into overlap-free streams and then performing ASR on the resulting signals. Recently, the inclusion of a mixture encoder in the ASR model has been proposed. This mixture encoder leverages the original overlapped speech to mitigate the effect of artifacts introduced by the speech separation. Previously, however, the method only addressed two-speaker scenarios. In this work, we extend this approach to more natural meeting contexts featuring an arbitrary number of speakers and dynamic overlaps. We evaluate the performance using different speech separators, including the powerful TF-GridNet model. Our experiments show state-of-the-art performance on the LibriCSS dataset and highlight the advantages of the mixture encoder. Furthermore, they demonstrate the strong separation of TF-GridNet which largely closes the gap between previous methods and oracle separation.
MeetEval: A Toolkit for Computation of Word Error Rates for Meeting Transcription Systems
Jul 21, 2023MeetEval is an open-source toolkit to evaluate all kinds of meeting transcription systems. It provides a unified interface for the computation of commonly used Word Error Rates (WERs), specifically cpWER, ORC WER and MIMO WER along other WER definitions. We extend the cpWER computation by a temporal constraint to ensure that only words are identified as correct when the temporal alignment is plausible. This leads to a better quality of the matching of the hypothesis string to the reference string that more closely resembles the actual transcription quality, and a system is penalized if it provides poor time annotations. Since word-level timing information is often not available, we present a way to approximate exact word-level timings from segment-level timings (e.g., a sentence) and show that the approximation leads to a similar WER as a matching with exact word-level annotations. At the same time, the time constraint leads to a speedup of the matching algorithm, which outweighs the additional overhead caused by processing the time stamps.