 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Quality-Based Localization of Low-Quality Speech and Text-to-Speech Synthesis Artefacts
Jan 29, 2026A large number of works view the automatic assessment of speech from an utterance- or system-level perspective. While such approaches are good in judging overall quality, they cannot adequately explain why a certain score was assigned to an utterance. frame-level scores can provide better interpretability, but models predicting them are harder to tune and regularize since no strong targets are available during training. In this work, we show that utterance-level speech quality predictors can be regularized with a segment-based consistency constraint which notably reduces frame-level stochasticity. We then demonstrate two applications involving frame-level scores: The partial spoof scenario and the detection of synthesis artefacts in two state-of-the-art text-to-speech systems. For the latter, we perform listening tests and confirm that listeners rate segments to be of poor quality more often in the set defined by low frame-level scores than in a random control set.
On the Role of Spatial Features in Foundation-Model-Based Speaker Diarization
Jan 05, 2026Recent advances in speaker diarization exploit large pretrained foundation models, such as WavLM, to achieve state-of-the-art performance on multiple datasets. Systems like DiariZen leverage these rich single-channel representations, but are limited to single-channel audio, preventing the use of spatial cues available in multi-channel recordings. This work analyzes the impact of incorporating spatial information into a state-of-the-art single-channel diarization system by evaluating several strategies for conditioning the model on multi-channel spatial features. Experiments on meeting-style datasets indicate that spatial information can improve diarization performance, but the overall improvement is smaller than expected for the proposed system, suggesting that the features aggregated over all WavLM layers already capture much of the information needed for accurate speaker discrimination, also in overlapping speech regions. These findings provide insight into the potential and limitations of using spatial cues to enhance foundation model-based diarization.
Meeting Recognition with Continuous Speech Separation and Transcription-Supported Diarization
Sep 28, 2023We propose a modular pipeline for the single-channel separation, recognition, and diarization of meeting-style recordings and evaluate it on the Libri-CSS dataset. Using a Continuous Speech Separation (CSS) system with a TF-GridNet separation architecture, followed by a speaker-agnostic speech recognizer, we achieve state-of-the-art recognition performance in terms of Optimal Reference Combination Word Error Rate (ORC WER). Then, a d-vector-based diarization module is employed to extract speaker embeddings from the enhanced signals and to assign the CSS outputs to the correct speaker. Here, we propose a syntactically informed diarization using sentence- and word-level boundaries of the ASR module to support speaker turn detection. This results in a state-of-the-art Concatenated minimum-Permutation Word Error Rate (cpWER) for the full meeting recognition pipeline.
Mixture Encoder Supporting Continuous Speech Separation for Meeting Recognition
Sep 15, 2023Many real-life applications of automatic speech recognition (ASR) require processing of overlapped speech. A commonmethod involves first separating the speech into overlap-free streams and then performing ASR on the resulting signals. Recently, the inclusion of a mixture encoder in the ASR model has been proposed. This mixture encoder leverages the original overlapped speech to mitigate the effect of artifacts introduced by the speech separation. Previously, however, the method only addressed two-speaker scenarios. In this work, we extend this approach to more natural meeting contexts featuring an arbitrary number of speakers and dynamic overlaps. We evaluate the performance using different speech separators, including the powerful TF-GridNet model. Our experiments show state-of-the-art performance on the LibriCSS dataset and highlight the advantages of the mixture encoder. Furthermore, they demonstrate the strong separation of TF-GridNet which largely closes the gap between previous methods and oracle separation.
MeetEval: A Toolkit for Computation of Word Error Rates for Meeting Transcription Systems
Jul 21, 2023MeetEval is an open-source toolkit to evaluate all kinds of meeting transcription systems. It provides a unified interface for the computation of commonly used Word Error Rates (WERs), specifically cpWER, ORC WER and MIMO WER along other WER definitions. We extend the cpWER computation by a temporal constraint to ensure that only words are identified as correct when the temporal alignment is plausible. This leads to a better quality of the matching of the hypothesis string to the reference string that more closely resembles the actual transcription quality, and a system is penalized if it provides poor time annotations. Since word-level timing information is often not available, we present a way to approximate exact word-level timings from segment-level timings (e.g., a sentence) and show that the approximation leads to a similar WER as a matching with exact word-level annotations. At the same time, the time constraint leads to a speedup of the matching algorithm, which outweighs the additional overhead caused by processing the time stamps.
On Word Error Rate Definitions and their Efficient Computation for Multi-Speaker Speech Recognition Systems
Nov 29, 2022We present a general framework to compute the word error rate (WER) of ASR systems that process recordings containing multiple speakers at their input and that produce multiple output word sequences (MIMO). Such ASR systems are typically required, e.g., for meeting transcription. We provide an efficient implementation based on a dynamic programming search in a multi-dimensional Levenshtein distance tensor under the constraint that a reference utterance must be matched consistently with one hypothesis output. This also results in an efficient implementation of the ORC WER which previously suffered from exponential complexity. We give an overview of commonly used WER definitions for multi-speaker scenarios and show that they are specializations of the above MIMO WER tuned to particular application scenarios. We conclude with a discussion of the pros and cons of the various WER definitions and a recommendation when to use which.
MMS-MSG: A Multi-purpose Multi-Speaker Mixture Signal Generator
Sep 23, 2022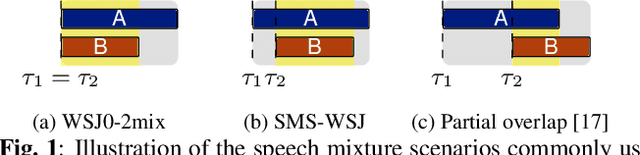
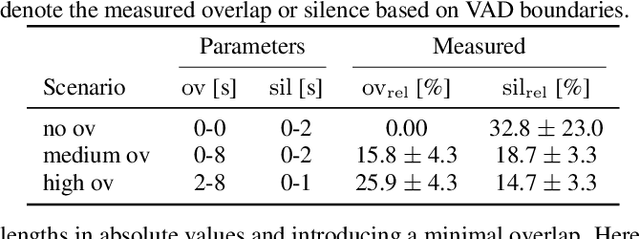
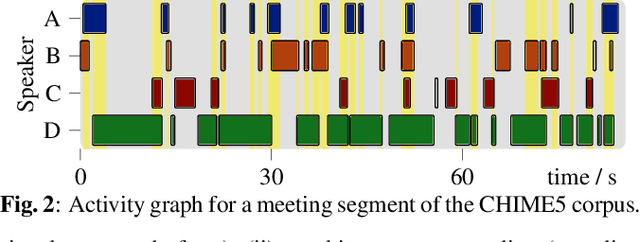
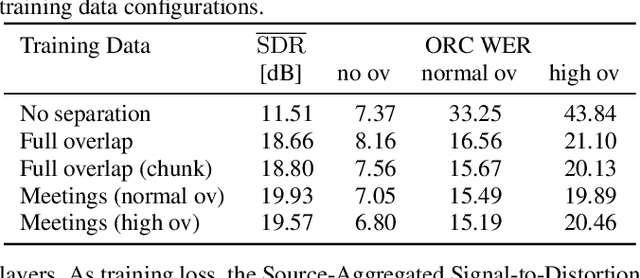
The scope of speech enhancement has changed from a monolithic view of single, independent tasks, to a joint processing of complex conversational speech recordings. Training and evaluation of these single tasks requires synthetic data with access to intermediate signals that is as close as possible to the evaluation scenario. As such data often is not available, many works instead use specialized databases for the training of each system component, e.g WSJ0-mix for source separation. We present a Multi-purpose Multi-Speaker Mixture Signal Generator (MMS-MSG) for generating a variety of speech mixture signals based on any speech corpus, ranging from classical anechoic mixtures (e.g., WSJ0-mix) over reverberant mixtures (e.g., SMS-WSJ) to meeting-style data. Its highly modular and flexible structure allows for the simulation of diverse environments and dynamic mixing, while simultaneously enabling an easy extension and modification to generate new scenarios and mixture types. These meetings can be used for prototyping, evaluation, or training purposes. We provide example evaluation data and baseline results for meetings based on the WSJ corpus. Further, we demonstrate the usefulness for realistic scenarios by using MMS-MSG to provide training data for the LibriCSS database.
Utterance-by-utterance overlap-aware neural diarization with Graph-PIT
Jul 28, 2022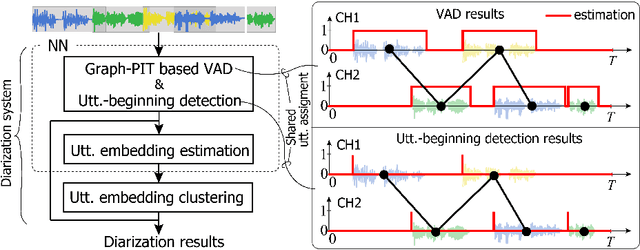
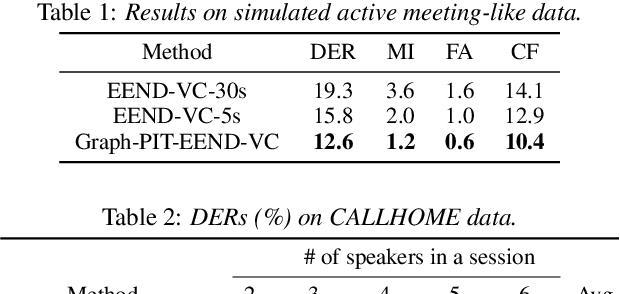
Recent speaker diarization studies showed that integration of end-to-end neural diarization (EEND) and clustering-based diarization is a promising approach for achieving state-of-the-art performance on various tasks. Such an approach first divides an observed signal into fixed-length segments, then performs {\it segment-level} local diarization based on an EEND module, and merges the segment-level results via clustering to form a final global diarization result. The segmentation is done to limit the number of speakers in each segment since the current EEND cannot handle a large number of speakers. In this paper, we argue that such an approach involving the segmentation has several issues; for example, it inevitably faces a dilemma that larger segment sizes increase both the context available for enhancing the performance and the number of speakers for the local EEND module to handle. To resolve such a problem, this paper proposes a novel framework that performs diarization without segmentation. However, it can still handle challenging data containing many speakers and a significant amount of overlapping speech. The proposed method can take an entire meeting for inference and perform {\it utterance-by-utterance} diarization that clusters utterance activities in terms of speakers. To this end, we leverage a neural network training scheme called Graph-PIT proposed recently for neural source separation. Experiments with simulated active-meeting-like data and CALLHOME data show the superiority of the proposed approach over the conventional methods.
A Meeting Transcription System for an Ad-Hoc Acoustic Sensor Network
May 02, 2022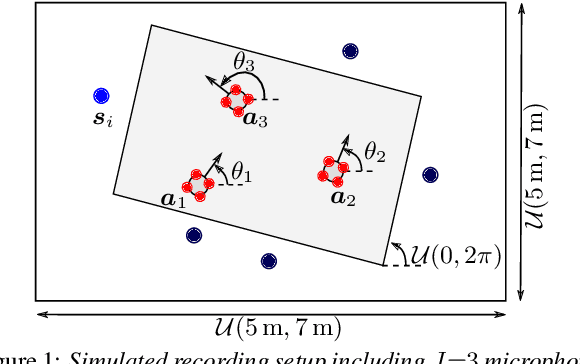
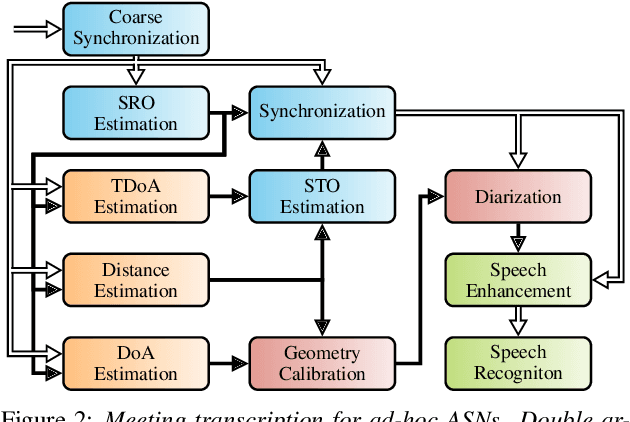
We propose a system that transcribes the conversation of a typical meeting scenario that is captured by a set of initially unsynchronized microphone arrays at unknown positions. It consists of subsystems for signal synchronization, including both sampling rate and sampling time offset estimation, diarization based on speaker and microphone array position estimation, multi-channel speech enhancement, and automatic speech recognition. With the estimated diarization information, a spatial mixture model is initialized that is used to estimate beamformer coefficients for source separation. Simulations show that the speech recognition accuracy can be improved by synchronizing and combining multiple distributed microphone arrays compared to a single compact microphone array. Furthermore, the proposed informed initialization of the spatial mixture model delivers a clear performance advantage over random initialization.
An Initialization Scheme for Meeting Separation with Spatial Mixture Models
Apr 04, 2022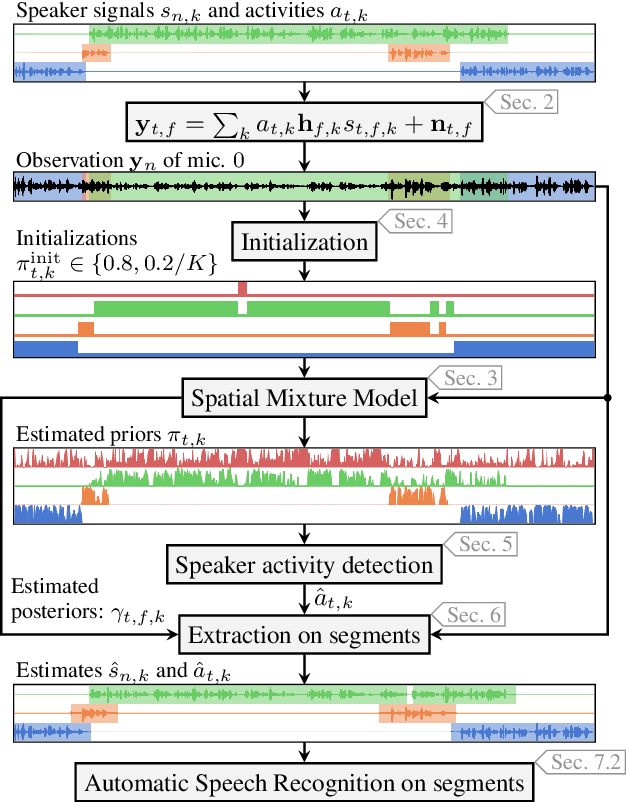
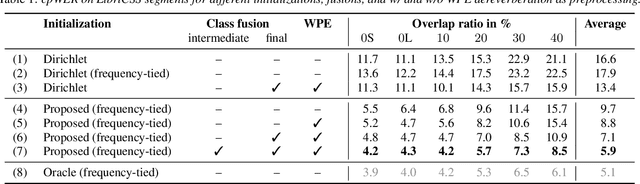
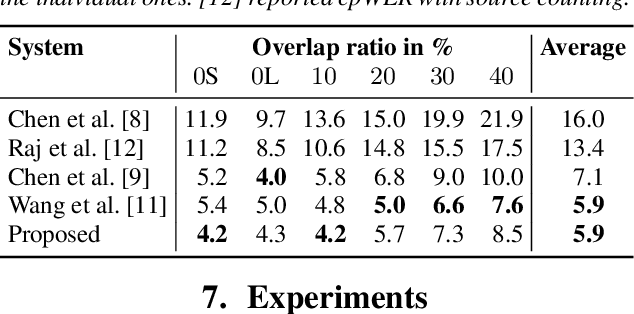
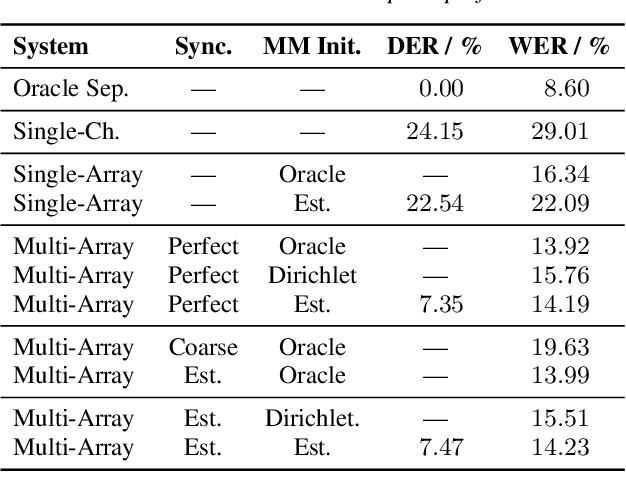
Spatial mixture model (SMM) supported acoustic beamforming has been extensively used for the separation of simultaneously active speakers. However, it has hardly been considered for the separation of meeting data, that are characterized by long recordings and only partially overlapping speech. In this contribution, we show that the fact that often only a single speaker is active can be utilized for a clever initialization of an SMM that employs time-varying class priors. In experiments on LibriCSS we show that the proposed initialization scheme achieves a significantly lower Word Error Rate (WER) on a downstream speech recognition task than a random initialization of the class probabilities by drawing from a Dirichlet distribution. With the only requirement that the number of speakers has to be known, we obtain a WER of 5.9 %, which is comparable to the best reported WER on this data set. Furthermore, the estimated speaker activity from the mixture model serves as a diarization based on spatial information.