 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoose coupling of spectral and spatial models for multi-channel diarization and enhancement of meetings in dynamic environments
Jan 22, 2026Sound capture by microphone arrays opens the possibility to exploit spatial, in addition to spectral, information for diarization and signal enhancement, two important tasks in meeting transcription. However, there is no one-to-one mapping of positions in space to speakers if speakers move. Here, we address this by proposing a novel joint spatial and spectral mixture model, whose two submodels are loosely coupled by modeling the relationship between speaker and position index probabilistically. Thus, spatial and spectral information can be jointly exploited, while at the same time allowing for speakers speaking from different positions. Experiments on the LibriCSS data set with simulated speaker position changes show great improvements over tightly coupled subsystems.
On the Role of Spatial Features in Foundation-Model-Based Speaker Diarization
Jan 05, 2026Recent advances in speaker diarization exploit large pretrained foundation models, such as WavLM, to achieve state-of-the-art performance on multiple datasets. Systems like DiariZen leverage these rich single-channel representations, but are limited to single-channel audio, preventing the use of spatial cues available in multi-channel recordings. This work analyzes the impact of incorporating spatial information into a state-of-the-art single-channel diarization system by evaluating several strategies for conditioning the model on multi-channel spatial features. Experiments on meeting-style datasets indicate that spatial information can improve diarization performance, but the overall improvement is smaller than expected for the proposed system, suggesting that the features aggregated over all WavLM layers already capture much of the information needed for accurate speaker discrimination, also in overlapping speech regions. These findings provide insight into the potential and limitations of using spatial cues to enhance foundation model-based diarization.
On the Application of Diffusion Models for Simultaneous Denoising and Dereverberation
Aug 26, 2025Diffusion models have been shown to achieve natural-sounding enhancement of speech degraded by noise or reverberation. However, their simultaneous denoising and dereverberation capability has so far not been studied much, although this is arguably the most common scenario in a practical application. In this work, we investigate different approaches to enhance noisy and/or reverberant speech. We examine the cascaded application of models, each trained on only one of the distortions, and compare it with a single model, trained either solely on data that is both noisy and reverberated, or trained on data comprising subsets of purely noisy, of purely reverberated, and of noisy reverberant speech. Tests are performed both on artificially generated and real recordings of noisy and/or reverberant data. The results show that, when using the cascade of models, satisfactory results are only achieved if they are applied in the order of the dominating distortion. If only a single model is desired that can operate on all distortion scenarios, the best compromise appears to be a model trained on the aforementioned three subsets of degraded speech data.
Simultaneous Diarization and Separation of Meetings through the Integration of Statistical Mixture Models
Oct 28, 2024


We propose an approach for simultaneous diarization and separation of meeting data. It consists of a complex Angular Central Gaussian Mixture Model (cACGMM) for speech source separation, and a von-Mises-Fisher Mixture Model (VMFMM) for diarization in a joint statistical framework. Through the integration, both spatial and spectral information are exploited for diarization and separation. We also develop a method for counting the number of active speakers in a segment of a meeting to support block-wise processing. While the total number of speakers in a meeting may be known, it is usually not known on a per-segment level. With the proposed speaker counting, joint diarization and source separation can be done segment-by-segment, and the permutation problem across segments is solved, thus allowing for block-online processing in the future. Experimental results on the LibriCSS meeting corpus show that the integrated approach outperforms a cascaded approach of diarization and speech enhancement in terms of WER, both on a per-segment and on a per-meeting level.
Once more Diarization: Improving meeting transcription systems through segment-level speaker reassignment
Jun 05, 2024



Diarization is a crucial component in meeting transcription systems to ease the challenges of speech enhancement and attribute the transcriptions to the correct speaker. Particularly in the presence of overlapping or noisy speech, these systems have problems reliably assigning the correct speaker labels, leading to a significant amount of speaker confusion errors. We propose to add segment-level speaker reassignment to address this issue. By revisiting, after speech enhancement, the speaker attribution for each segment, speaker confusion errors from the initial diarization stage are significantly reduced. Through experiments across different system configurations and datasets, we further demonstrate the effectiveness and applicability in various domains. Our results show that segment-level speaker reassignment successfully rectifies at least 40% of speaker confusion word errors, highlighting its potential for enhancing diarization accuracy in meeting transcription systems.
Geodesic interpolation of frame-wise speaker embeddings for the diarization of meeting scenarios
Jan 08, 2024



We propose a modified teacher-student training for the extraction of frame-wise speaker embeddings that allows for an effective diarization of meeting scenarios containing partially overlapping speech. To this end, a geodesic distance loss is used that enforces the embeddings computed from regions with two active speakers to lie on the shortest path on a sphere between the points given by the d-vectors of each of the active speakers. Using those frame-wise speaker embeddings in clustering-based diarization outperforms segment-level clustering-based diarization systems such as VBx and Spectral Clustering. By extending our approach to a mixture-model-based diarization, the performance can be further improved, approaching the diarization error rates of diarization systems that use a dedicated overlap detection, and outperforming these systems when also employing an additional overlap detection.
Meeting Recognition with Continuous Speech Separation and Transcription-Supported Diarization
Sep 28, 2023We propose a modular pipeline for the single-channel separation, recognition, and diarization of meeting-style recordings and evaluate it on the Libri-CSS dataset. Using a Continuous Speech Separation (CSS) system with a TF-GridNet separation architecture, followed by a speaker-agnostic speech recognizer, we achieve state-of-the-art recognition performance in terms of Optimal Reference Combination Word Error Rate (ORC WER). Then, a d-vector-based diarization module is employed to extract speaker embeddings from the enhanced signals and to assign the CSS outputs to the correct speaker. Here, we propose a syntactically informed diarization using sentence- and word-level boundaries of the ASR module to support speaker turn detection. This results in a state-of-the-art Concatenated minimum-Permutation Word Error Rate (cpWER) for the full meeting recognition pipeline.
Frame-wise and overlap-robust speaker embeddings for meeting diarization
Jun 01, 2023



Using a Teacher-Student training approach we developed a speaker embedding extraction system that outputs embeddings at frame rate. Given this high temporal resolution and the fact that the student produces sensible speaker embeddings even for segments with speech overlap, the frame-wise embeddings serve as an appropriate representation of the input speech signal for an end-to-end neural meeting diarization (EEND) system. We show in experiments that this representation helps mitigate a well-known problem of EEND systems: when increasing the number of speakers the diarization performance drop is significantly reduced. We also introduce block-wise processing to be able to diarize arbitrarily long meetings.
A Teacher-Student approach for extracting informative speaker embeddings from speech mixtures
Jun 01, 2023



We introduce a monaural neural speaker embeddings extractor that computes an embedding for each speaker present in a speech mixture. To allow for supervised training, a teacher-student approach is employed: the teacher computes the target embeddings from each speaker's utterance before the utterances are added to form the mixture, and the student embedding extractor is then tasked to reproduce those embeddings from the speech mixture at its input. The system much more reliably verifies the presence or absence of a given speaker in a mixture than a conventional speaker embedding extractor, and even exhibits comparable performance to a multi-channel approach that exploits spatial information for embedding extraction. Further, it is shown that a speaker embedding computed from a mixture can be used to check for the presence of that speaker in another mixture.
MMS-MSG: A Multi-purpose Multi-Speaker Mixture Signal Generator
Sep 23, 2022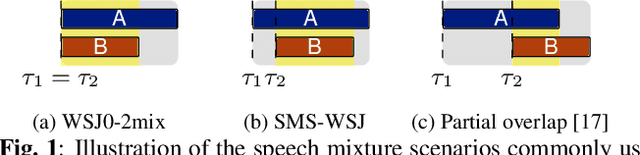
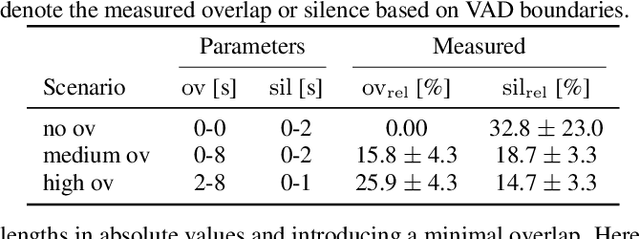
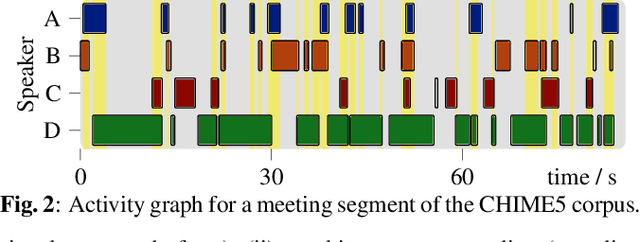
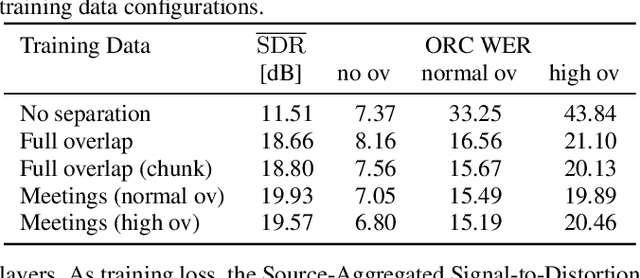
The scope of speech enhancement has changed from a monolithic view of single, independent tasks, to a joint processing of complex conversational speech recordings. Training and evaluation of these single tasks requires synthetic data with access to intermediate signals that is as close as possible to the evaluation scenario. As such data often is not available, many works instead use specialized databases for the training of each system component, e.g WSJ0-mix for source separation. We present a Multi-purpose Multi-Speaker Mixture Signal Generator (MMS-MSG) for generating a variety of speech mixture signals based on any speech corpus, ranging from classical anechoic mixtures (e.g., WSJ0-mix) over reverberant mixtures (e.g., SMS-WSJ) to meeting-style data. Its highly modular and flexible structure allows for the simulation of diverse environments and dynamic mixing, while simultaneously enabling an easy extension and modification to generate new scenarios and mixture types. These meetings can be used for prototyping, evaluation, or training purposes. We provide example evaluation data and baseline results for meetings based on the WSJ corpus. Further, we demonstrate the usefulness for realistic scenarios by using MMS-MSG to provide training data for the LibriCSS database.