 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoose coupling of spectral and spatial models for multi-channel diarization and enhancement of meetings in dynamic environments
Jan 22, 2026Sound capture by microphone arrays opens the possibility to exploit spatial, in addition to spectral, information for diarization and signal enhancement, two important tasks in meeting transcription. However, there is no one-to-one mapping of positions in space to speakers if speakers move. Here, we address this by proposing a novel joint spatial and spectral mixture model, whose two submodels are loosely coupled by modeling the relationship between speaker and position index probabilistically. Thus, spatial and spectral information can be jointly exploited, while at the same time allowing for speakers speaking from different positions. Experiments on the LibriCSS data set with simulated speaker position changes show great improvements over tightly coupled subsystems.
On the Application of Diffusion Models for Simultaneous Denoising and Dereverberation
Aug 26, 2025Diffusion models have been shown to achieve natural-sounding enhancement of speech degraded by noise or reverberation. However, their simultaneous denoising and dereverberation capability has so far not been studied much, although this is arguably the most common scenario in a practical application. In this work, we investigate different approaches to enhance noisy and/or reverberant speech. We examine the cascaded application of models, each trained on only one of the distortions, and compare it with a single model, trained either solely on data that is both noisy and reverberated, or trained on data comprising subsets of purely noisy, of purely reverberated, and of noisy reverberant speech. Tests are performed both on artificially generated and real recordings of noisy and/or reverberant data. The results show that, when using the cascade of models, satisfactory results are only achieved if they are applied in the order of the dominating distortion. If only a single model is desired that can operate on all distortion scenarios, the best compromise appears to be a model trained on the aforementioned three subsets of degraded speech data.
Diminishing Domain Mismatch for DNN-Based Acoustic Distance Estimation via Stochastic Room Reverberation Models
Aug 26, 2024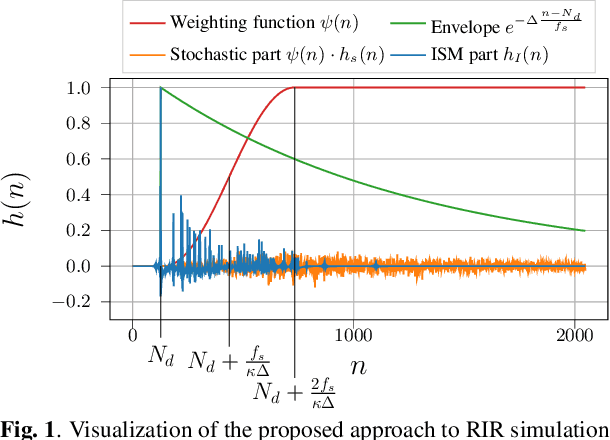
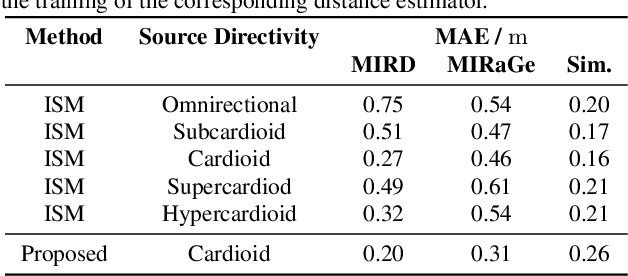
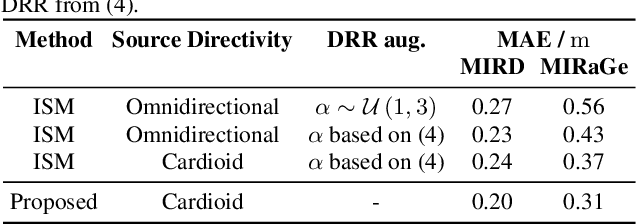

The room impulse response (RIR) encodes, among others, information about the distance of an acoustic source from the sensors. Deep neural networks (DNNs) have been shown to be able to extract that information for acoustic distance estimation. Since there exists only a very limited amount of annotated data, e.g., RIRs with distance information, training a DNN for acoustic distance estimation has to rely on simulated RIRs, resulting in an unavoidable mismatch to RIRs of real rooms. In this contribution, we show that this mismatch can be reduced by a novel combination of geometric and stochastic modeling of RIRs, resulting in a significantly improved distance estimation accuracy.
Investigating Speaker Embedding Disentanglement on Natural Read Speech
Aug 08, 2023
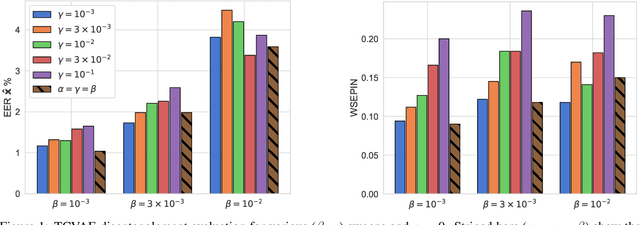
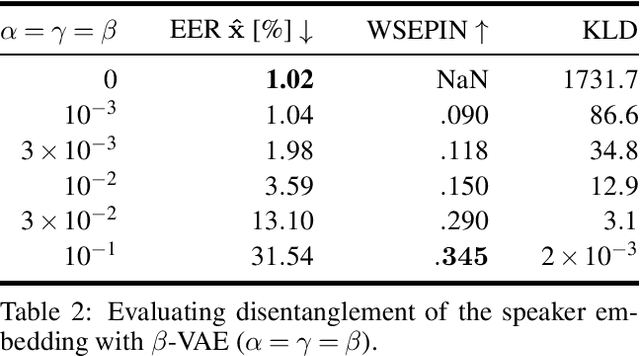
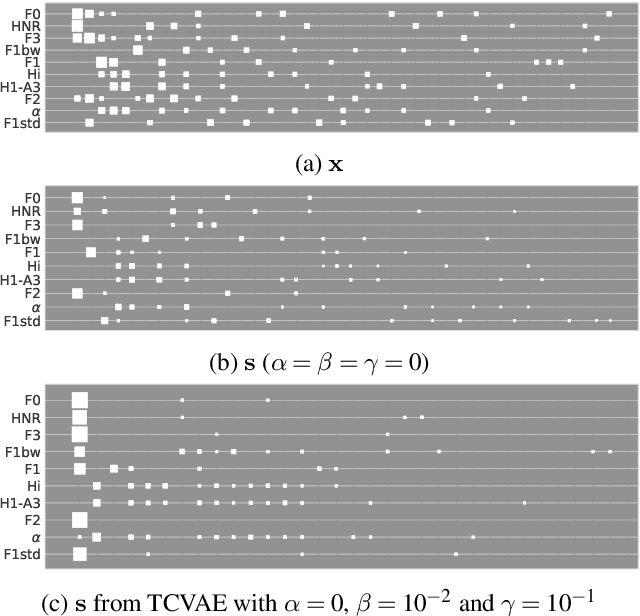
Disentanglement is the task of learning representations that identify and separate factors that explain the variation observed in data. Disentangled representations are useful to increase the generalizability, explainability, and fairness of data-driven models. Only little is known about how well such disentanglement works for speech representations. A major challenge when tackling disentanglement for speech representations are the unknown generative factors underlying the speech signal. In this work, we investigate to what degree speech representations encoding speaker identity can be disentangled. To quantify disentanglement, we identify acoustic features that are highly speaker-variant and can serve as proxies for the factors of variation underlying speech. We find that disentanglement of the speaker embedding is limited when trained with standard objectives promoting disentanglement but can be improved over vanilla representation learning to some extent.