 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Spatial Features in Foundation-Model-Based Speaker Diarization
Jan 05, 2026Recent advances in speaker diarization exploit large pretrained foundation models, such as WavLM, to achieve state-of-the-art performance on multiple datasets. Systems like DiariZen leverage these rich single-channel representations, but are limited to single-channel audio, preventing the use of spatial cues available in multi-channel recordings. This work analyzes the impact of incorporating spatial information into a state-of-the-art single-channel diarization system by evaluating several strategies for conditioning the model on multi-channel spatial features. Experiments on meeting-style datasets indicate that spatial information can improve diarization performance, but the overall improvement is smaller than expected for the proposed system, suggesting that the features aggregated over all WavLM layers already capture much of the information needed for accurate speaker discrimination, also in overlapping speech regions. These findings provide insight into the potential and limitations of using spatial cues to enhance foundation model-based diarization.
Diminishing Domain Mismatch for DNN-Based Acoustic Distance Estimation via Stochastic Room Reverberation Models
Aug 26, 2024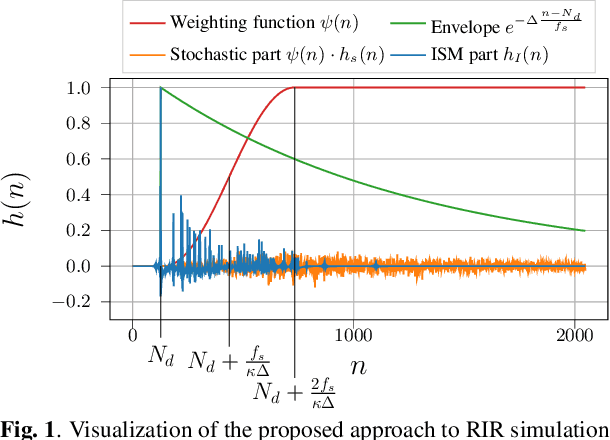
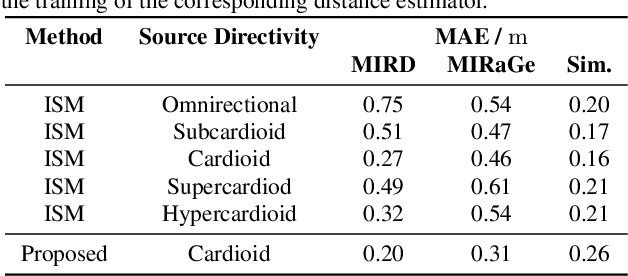
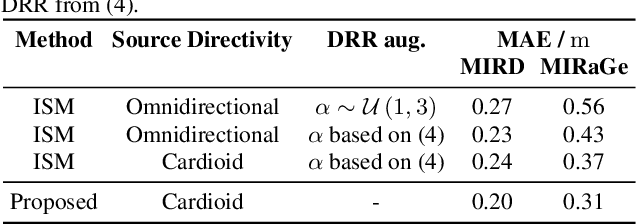

The room impulse response (RIR) encodes, among others, information about the distance of an acoustic source from the sensors. Deep neural networks (DNNs) have been shown to be able to extract that information for acoustic distance estimation. Since there exists only a very limited amount of annotated data, e.g., RIRs with distance information, training a DNN for acoustic distance estimation has to rely on simulated RIRs, resulting in an unavoidable mismatch to RIRs of real rooms. In this contribution, we show that this mismatch can be reduced by a novel combination of geometric and stochastic modeling of RIRs, resulting in a significantly improved distance estimation accuracy.
Spatial Diarization for Meeting Transcription with Ad-Hoc Acoustic Sensor Networks
Nov 27, 2023

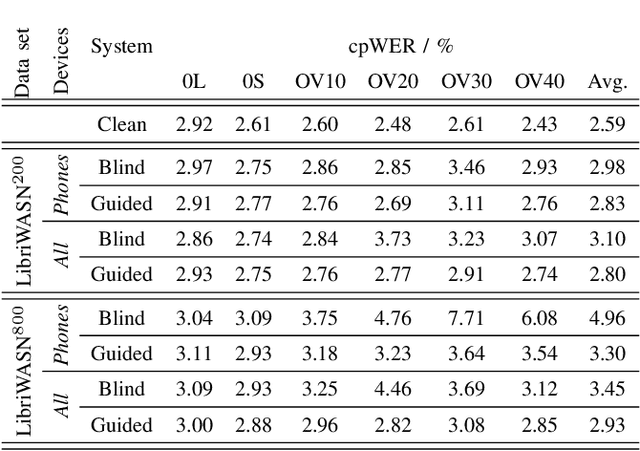
We propose a diarization system, that estimates "who spoke when" based on spatial information, to be used as a front-end of a meeting transcription system running on the signals gathered from an acoustic sensor network (ASN). Although the spatial distribution of the microphones is advantageous, exploiting the spatial diversity for diarization and signal enhancement is challenging, because the microphones' positions are typically unknown, and the recorded signals are initially unsynchronized in general. Here, we approach these issues by first blindly synchronizing the signals and then estimating time differences of arrival (TDOAs). The TDOA information is exploited to estimate the speakers' activity, even in the presence of multiple speakers being simultaneously active. This speaker activity information serves as a guide for a spatial mixture model, on which basis the individual speaker's signals are extracted via beamforming. Finally, the extracted signals are forwarded to a speech recognizer. Additionally, a novel initialization scheme for spatial mixture models based on the TDOA estimates is proposed. Experiments conducted on real recordings from the LibriWASN data set have shown that our proposed system is advantageous compared to a system using a spatial mixture model, which does not make use of external diarization information.
LibriWASN: A Data Set for Meeting Separation, Diarization, and Recognition with Asynchronous Recording Devices
Aug 21, 2023We present LibriWASN, a data set whose design follows closely the LibriCSS meeting recognition data set, with the marked difference that the data is recorded with devices that are randomly positioned on a meeting table and whose sampling clocks are not synchronized. Nine different devices, five smartphones with a single recording channel and four microphone arrays, are used to record a total of 29 channels. Other than that, the data set follows closely the LibriCSS design: the same LibriSpeech sentences are played back from eight loudspeakers arranged around a meeting table and the data is organized in subsets with different percentages of speech overlap. LibriWASN is meant as a test set for clock synchronization algorithms, meeting separation, diarization and transcription systems on ad-hoc wireless acoustic sensor networks. Due to its similarity to LibriCSS, meeting transcription systems developed for the former can readily be tested on LibriWASN. The data set is recorded in two different rooms and is complemented with ground-truth diarization information of who speaks when.
A Meeting Transcription System for an Ad-Hoc Acoustic Sensor Network
May 02, 2022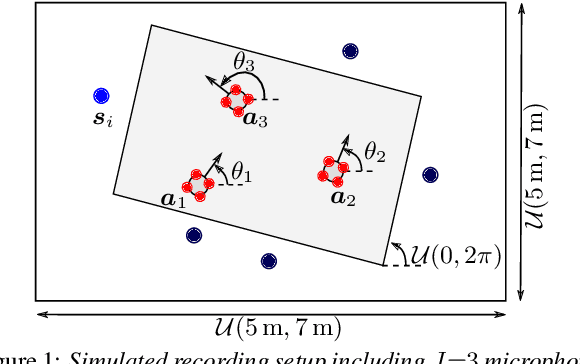
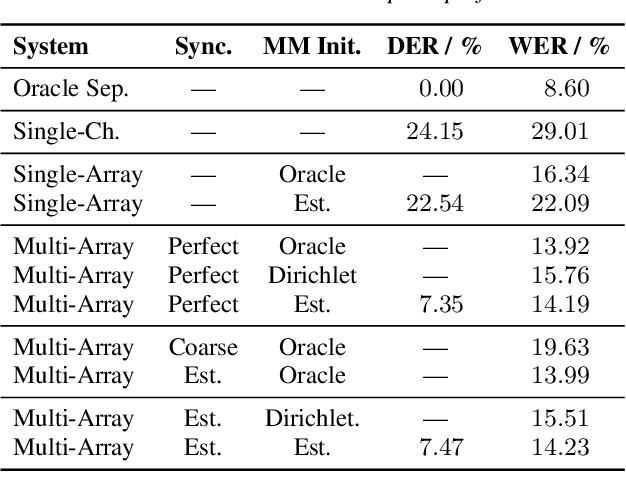
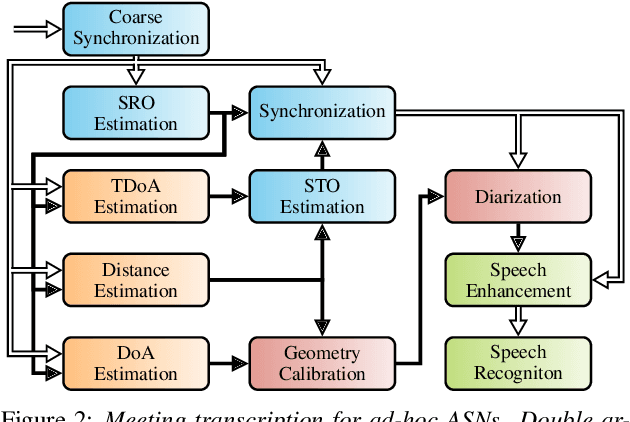
We propose a system that transcribes the conversation of a typical meeting scenario that is captured by a set of initially unsynchronized microphone arrays at unknown positions. It consists of subsystems for signal synchronization, including both sampling rate and sampling time offset estimation, diarization based on speaker and microphone array position estimation, multi-channel speech enhancement, and automatic speech recognition. With the estimated diarization information, a spatial mixture model is initialized that is used to estimate beamformer coefficients for source separation. Simulations show that the speech recognition accuracy can be improved by synchronizing and combining multiple distributed microphone arrays compared to a single compact microphone array. Furthermore, the proposed informed initialization of the spatial mixture model delivers a clear performance advantage over random initialization.
On Synchronization of Wireless Acoustic Sensor Networks in the Presence of Time-varying Sampling Rate Offsets and Speaker Changes
Oct 25, 2021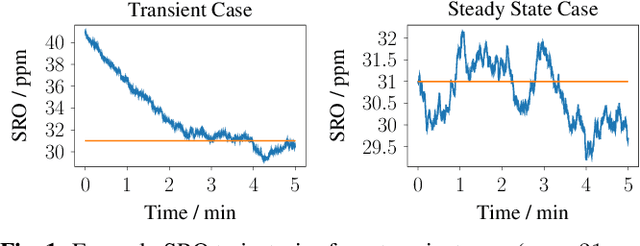
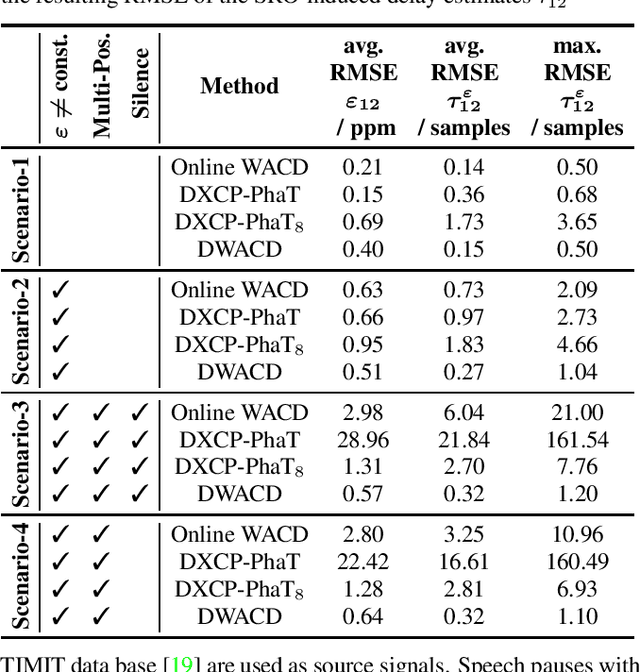
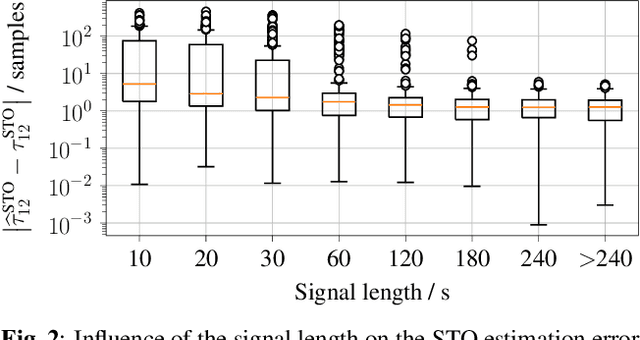

A wireless acoustic sensor network records audio signals with sampling time and sampling rate offsets between the audio streams, if the analog-digital converters (ADCs) of the network devices are not synchronized. Here, we introduce a new sampling rate offset model to simulate time-varying sampling frequencies caused, for example, by temperature changes of ADC crystal oscillators, and propose an estimation algorithm to handle this dynamic aspect in combination with changing acoustic source positions. Furthermore, we show how deep neural network based estimates of the distances between microphones and human speakers can be used to determine the sampling time offsets. This enables a synchronization of the audio streams to reflect the physical time differences of flight.