 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Pitch and Creak for Speaker Identity Preservation in Speech Synthesis
Feb 16, 2026We introduce a system capable of faithfully modifying the perceptual voice quality of creak while preserving the speaker's perceived identity. While it is well known that high creak probability is typically correlated with low pitch, it is important to note that this is a property observed on a population of speakers but does not necessarily hold across all situations. Disentanglement of pitch from creak is achieved by augmentation of the training dataset of a speech synthesis system with a speaker manipulation block based on conditional continuous normalizing flow. The experiments show greatly improved speaker verification performance over a range of creak manipulation strengths.
Speech Quality-Based Localization of Low-Quality Speech and Text-to-Speech Synthesis Artefacts
Jan 29, 2026A large number of works view the automatic assessment of speech from an utterance- or system-level perspective. While such approaches are good in judging overall quality, they cannot adequately explain why a certain score was assigned to an utterance. frame-level scores can provide better interpretability, but models predicting them are harder to tune and regularize since no strong targets are available during training. In this work, we show that utterance-level speech quality predictors can be regularized with a segment-based consistency constraint which notably reduces frame-level stochasticity. We then demonstrate two applications involving frame-level scores: The partial spoof scenario and the detection of synthesis artefacts in two state-of-the-art text-to-speech systems. For the latter, we perform listening tests and confirm that listeners rate segments to be of poor quality more often in the set defined by low frame-level scores than in a random control set.
Loose coupling of spectral and spatial models for multi-channel diarization and enhancement of meetings in dynamic environments
Jan 22, 2026Sound capture by microphone arrays opens the possibility to exploit spatial, in addition to spectral, information for diarization and signal enhancement, two important tasks in meeting transcription. However, there is no one-to-one mapping of positions in space to speakers if speakers move. Here, we address this by proposing a novel joint spatial and spectral mixture model, whose two submodels are loosely coupled by modeling the relationship between speaker and position index probabilistically. Thus, spatial and spectral information can be jointly exploited, while at the same time allowing for speakers speaking from different positions. Experiments on the LibriCSS data set with simulated speaker position changes show great improvements over tightly coupled subsystems.
On the Role of Spatial Features in Foundation-Model-Based Speaker Diarization
Jan 05, 2026Recent advances in speaker diarization exploit large pretrained foundation models, such as WavLM, to achieve state-of-the-art performance on multiple datasets. Systems like DiariZen leverage these rich single-channel representations, but are limited to single-channel audio, preventing the use of spatial cues available in multi-channel recordings. This work analyzes the impact of incorporating spatial information into a state-of-the-art single-channel diarization system by evaluating several strategies for conditioning the model on multi-channel spatial features. Experiments on meeting-style datasets indicate that spatial information can improve diarization performance, but the overall improvement is smaller than expected for the proposed system, suggesting that the features aggregated over all WavLM layers already capture much of the information needed for accurate speaker discrimination, also in overlapping speech regions. These findings provide insight into the potential and limitations of using spatial cues to enhance foundation model-based diarization.
Synthesizing speech with selected perceptual voice qualities - A case study with creaky voice
Nov 07, 2025The control of perceptual voice qualities in a text-to-speech (TTS) system is of interest for applications where unmanipu- lated and manipulated speech probes can serve to illustrate pho- netic concepts that are otherwise difficult to grasp. Here, we show that a TTS system, that is augmented with a global speaker attribute manipulation block based on normalizing flows1 , is capable of correctly manipulating the non-persistent, localized quality of creaky voice, thus avoiding the necessity of a, typi- cally unreliable, frame-wise creak predictor. Subjective listen- ing tests confirm successful creak manipulation at a slightly re- duced MOS score compared to the original recording.
On the Application of Diffusion Models for Simultaneous Denoising and Dereverberation
Aug 26, 2025Diffusion models have been shown to achieve natural-sounding enhancement of speech degraded by noise or reverberation. However, their simultaneous denoising and dereverberation capability has so far not been studied much, although this is arguably the most common scenario in a practical application. In this work, we investigate different approaches to enhance noisy and/or reverberant speech. We examine the cascaded application of models, each trained on only one of the distortions, and compare it with a single model, trained either solely on data that is both noisy and reverberated, or trained on data comprising subsets of purely noisy, of purely reverberated, and of noisy reverberant speech. Tests are performed both on artificially generated and real recordings of noisy and/or reverberant data. The results show that, when using the cascade of models, satisfactory results are only achieved if they are applied in the order of the dominating distortion. If only a single model is desired that can operate on all distortion scenarios, the best compromise appears to be a model trained on the aforementioned three subsets of degraded speech data.
Towards Frame-level Quality Predictions of Synthetic Speech
Aug 14, 2025While automatic subjective speech quality assessment has witnessed much progress, an open question is whether an automatic quality assessment at frame resolution is possible. This would be highly desirable, as it adds explainability to the assessment of speech synthesis systems. Here, we take first steps towards this goal by identifying issues of existing quality predictors that prevent sensible frame-level prediction. Further, we define criteria that a frame-level predictor should fulfill. We also suggest a chunk-based processing that avoids the impact of a localized distortion on the score of neighboring frames. Finally, we measure in experiments with localized artificial distortions the localization performance of a set of frame-level quality predictors and show that they can outperform detection performance of human annotations obtained from a crowd-sourced perception experiment.
30+ Years of Source Separation Research: Achievements and Future Challenges
Jan 21, 2025Source separation (SS) of acoustic signals is a research field that emerged in the mid-1990s and has flourished ever since. On the occasion of ICASSP's 50th anniversary, we review the major contributions and advancements in the past three decades in the speech, audio, and music SS research field. We will cover both single- and multi-channel SS approaches. We will also look back on key efforts to foster a culture of scientific evaluation in the research field, including challenges, performance metrics, and datasets. We will conclude by discussing current trends and future research directions.
Speech Synthesis along Perceptual Voice Quality Dimensions
Jan 15, 2025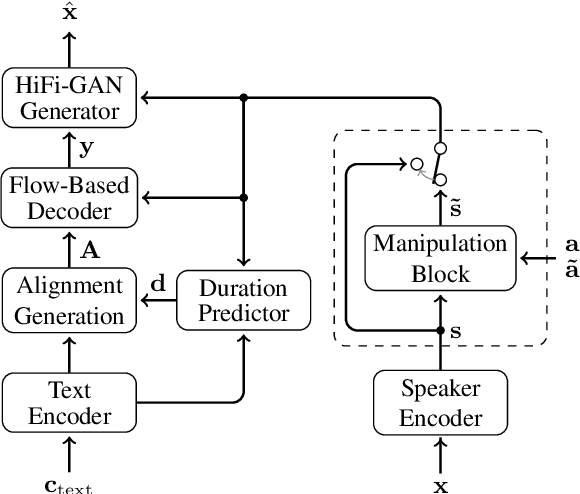
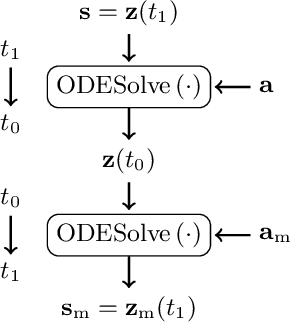
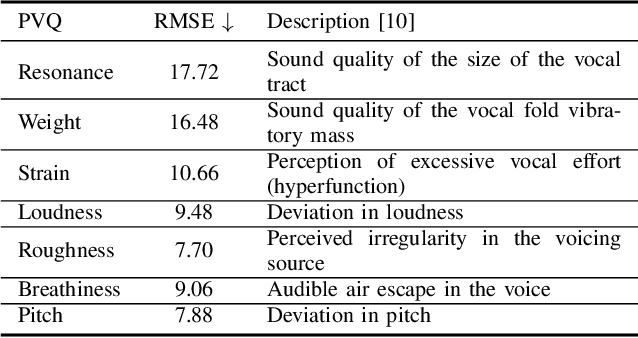

While expressive speech synthesis or voice conversion systems mainly focus on controlling or manipulating abstract prosodic characteristics of speech, such as emotion or accent, we here address the control of perceptual voice qualities (PVQs) recognized by phonetic experts, which are speech properties at a lower level of abstraction. The ability to manipulate PVQs can be a valuable tool for teaching speech pathologists in training or voice actors. In this paper, we integrate a Conditional Continuous-Normalizing-Flow-based method into a Text-to-Speech system to modify perceptual voice attributes on a continuous scale. Unlike previous approaches, our system avoids direct manipulation of acoustic correlates and instead learns from examples. We demonstrate the system's capability by manipulating four voice qualities: Roughness, breathiness, resonance and weight. Phonetic experts evaluated these modifications, both for seen and unseen speaker conditions. The results highlight both the system's strengths and areas for improvement.
Microphone Array Signal Processing and Deep Learning for Speech Enhancement
Jan 13, 2025



Multi-channel acoustic signal processing is a well-established and powerful tool to exploit the spatial diversity between a target signal and non-target or noise sources for signal enhancement. However, the textbook solutions for optimal data-dependent spatial filtering rest on the knowledge of second-order statistical moments of the signals, which have traditionally been difficult to acquire. In this contribution, we compare model-based, purely data-driven, and hybrid approaches to parameter estimation and filtering, where the latter tries to combine the benefits of model-based signal processing and data-driven deep learning to overcome their individual deficiencies. We illustrate the underlying design principles with examples from noise reduction, source separation, and dereverberation.
* Accepted for IEEE Signal Processing Magazine