 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Pitch and Creak for Speaker Identity Preservation in Speech Synthesis
Feb 16, 2026We introduce a system capable of faithfully modifying the perceptual voice quality of creak while preserving the speaker's perceived identity. While it is well known that high creak probability is typically correlated with low pitch, it is important to note that this is a property observed on a population of speakers but does not necessarily hold across all situations. Disentanglement of pitch from creak is achieved by augmentation of the training dataset of a speech synthesis system with a speaker manipulation block based on conditional continuous normalizing flow. The experiments show greatly improved speaker verification performance over a range of creak manipulation strengths.
Synthesizing speech with selected perceptual voice qualities - A case study with creaky voice
Nov 07, 2025The control of perceptual voice qualities in a text-to-speech (TTS) system is of interest for applications where unmanipu- lated and manipulated speech probes can serve to illustrate pho- netic concepts that are otherwise difficult to grasp. Here, we show that a TTS system, that is augmented with a global speaker attribute manipulation block based on normalizing flows1 , is capable of correctly manipulating the non-persistent, localized quality of creaky voice, thus avoiding the necessity of a, typi- cally unreliable, frame-wise creak predictor. Subjective listen- ing tests confirm successful creak manipulation at a slightly re- duced MOS score compared to the original recording.
Speech Synthesis along Perceptual Voice Quality Dimensions
Jan 15, 2025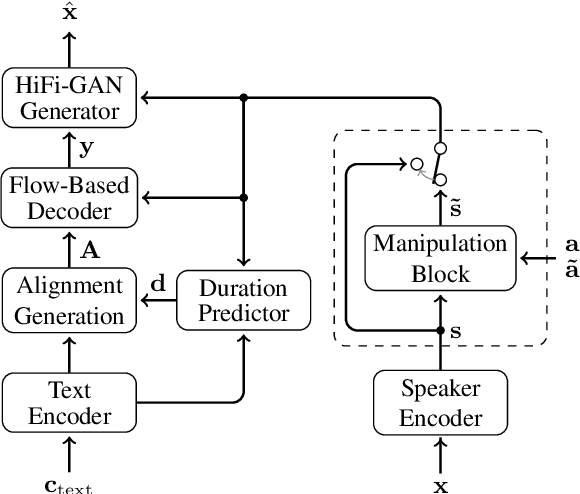
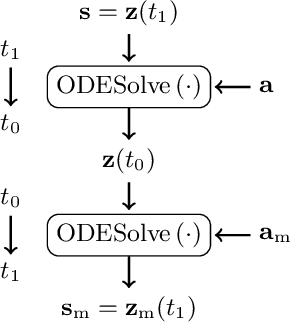
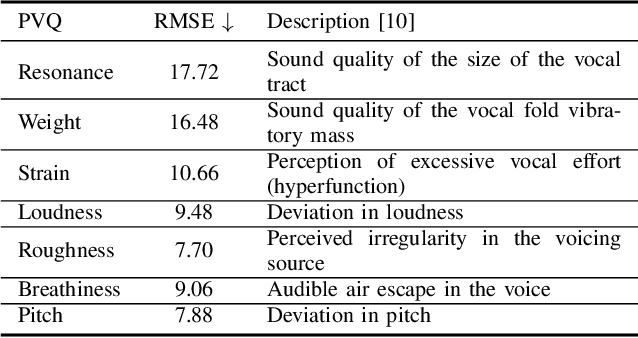

While expressive speech synthesis or voice conversion systems mainly focus on controlling or manipulating abstract prosodic characteristics of speech, such as emotion or accent, we here address the control of perceptual voice qualities (PVQs) recognized by phonetic experts, which are speech properties at a lower level of abstraction. The ability to manipulate PVQs can be a valuable tool for teaching speech pathologists in training or voice actors. In this paper, we integrate a Conditional Continuous-Normalizing-Flow-based method into a Text-to-Speech system to modify perceptual voice attributes on a continuous scale. Unlike previous approaches, our system avoids direct manipulation of acoustic correlates and instead learns from examples. We demonstrate the system's capability by manipulating four voice qualities: Roughness, breathiness, resonance and weight. Phonetic experts evaluated these modifications, both for seen and unseen speaker conditions. The results highlight both the system's strengths and areas for improvement.
Speaker and Style Disentanglement of Speech Based on Contrastive Predictive Coding Supported Factorized Variational Autoencoder
Sep 05, 2024Speech signals encompass various information across multiple levels including content, speaker, and style. Disentanglement of these information, although challenging, is important for applications such as voice conversion. The contrastive predictive coding supported factorized variational autoencoder achieves unsupervised disentanglement of a speech signal into speaker and content embeddings by assuming speaker info to be temporally more stable than content-induced variations. However, this assumption may introduce other temporal stable information into the speaker embeddings, like environment or emotion, which we call style. In this work, we propose a method to further disentangle non-content features into distinct speaker and style features, notably by leveraging readily accessible and well-defined speaker labels without the necessity for style labels. Experimental results validate the proposed method's effectiveness on extracting disentangled features, thereby facilitating speaker, style, or combined speaker-style conversion.
On Feature Importance and Interpretability of Speaker Representations
Oct 19, 2023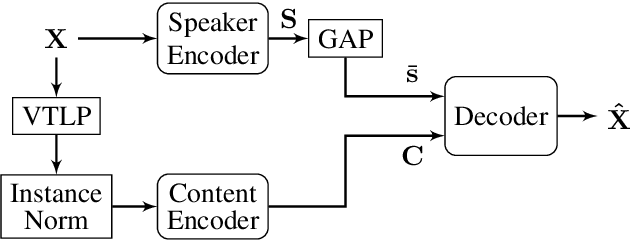
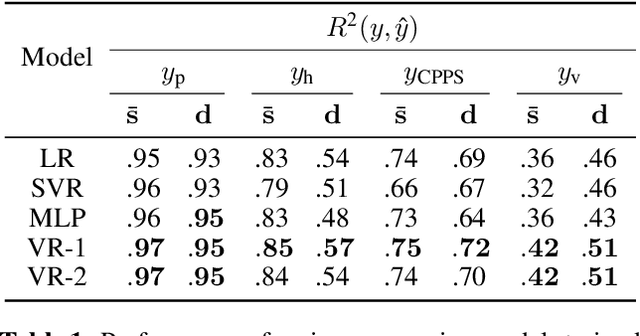
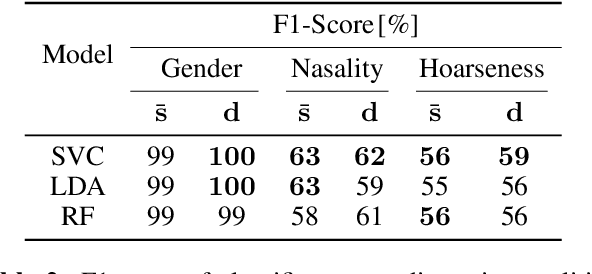

Unsupervised speech disentanglement aims at separating fast varying from slowly varying components of a speech signal. In this contribution, we take a closer look at the embedding vector representing the slowly varying signal components, commonly named the speaker embedding vector. We ask, which properties of a speaker's voice are captured and investigate to which extent do individual embedding vector components sign responsible for them, using the concept of Shapley values. Our findings show that certain speaker-specific acoustic-phonetic properties can be fairly well predicted from the speaker embedding, while the investigated more abstract voice quality features cannot.
A Comparison and Combination of Unsupervised Blind Source Separation Techniques
Jun 10, 2021
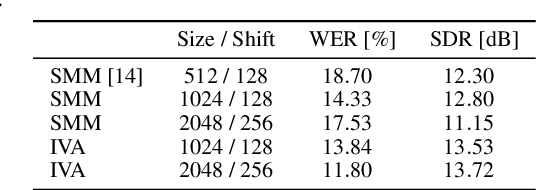
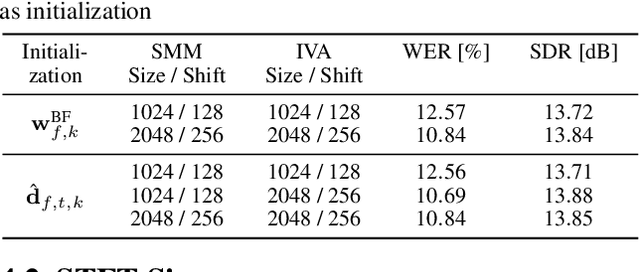
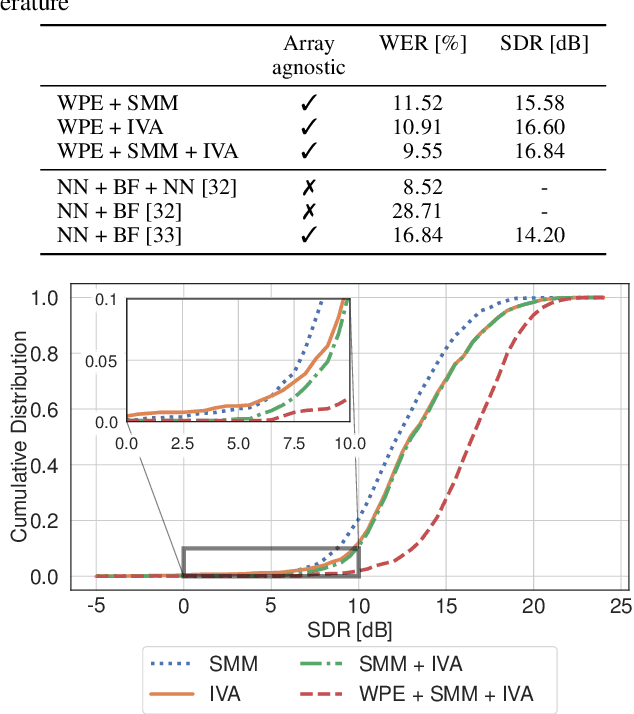
Unsupervised blind source separation methods do not require a training phase and thus cannot suffer from a train-test mismatch, which is a common concern in neural network based source separation. The unsupervised techniques can be categorized in two classes, those building upon the sparsity of speech in the Short-Time Fourier transform domain and those exploiting non-Gaussianity or non-stationarity of the source signals. In this contribution, spatial mixture models which fall in the first category and independent vector analysis (IVA) as a representative of the second category are compared w.r.t. their separation performance and the performance of a downstream speech recognizer on a reverberant dataset of reasonable size. Furthermore, we introduce a serial concatenation of the two, where the result of the mixture model serves as initialization of IVA, which achieves significantly better WER performance than each algorithm individually and even approaches the performance of a much more complex neural network based technique.