 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Deep Learning for Complex Speech Spectrograms
May 13, 2025Recent advancements in deep learning have significantly impacted the field of speech signal processing, particularly in the analysis and manipulation of complex spectrograms. This survey provides a comprehensive overview of the state-of-the-art techniques leveraging deep neural networks for processing complex spectrograms, which encapsulate both magnitude and phase information. We begin by introducing complex spectrograms and their associated features for various speech processing tasks. Next, we explore the key components and architectures of complex-valued neural networks, which are specifically designed to handle complex-valued data and have been applied for complex spectrogram processing. We then discuss various training strategies and loss functions tailored for training neural networks to process and model complex spectrograms. The survey further examines key applications, including phase retrieval, speech enhancement, and speech separation, where deep learning has achieved significant progress by leveraging complex spectrograms or their derived feature representations. Additionally, we examine the intersection of complex spectrograms with generative models. This survey aims to serve as a valuable resource for researchers and practitioners in the field of speech signal processing and complex-valued neural networks.
Speaker and Style Disentanglement of Speech Based on Contrastive Predictive Coding Supported Factorized Variational Autoencoder
Sep 05, 2024Speech signals encompass various information across multiple levels including content, speaker, and style. Disentanglement of these information, although challenging, is important for applications such as voice conversion. The contrastive predictive coding supported factorized variational autoencoder achieves unsupervised disentanglement of a speech signal into speaker and content embeddings by assuming speaker info to be temporally more stable than content-induced variations. However, this assumption may introduce other temporal stable information into the speaker embeddings, like environment or emotion, which we call style. In this work, we propose a method to further disentangle non-content features into distinct speaker and style features, notably by leveraging readily accessible and well-defined speaker labels without the necessity for style labels. Experimental results validate the proposed method's effectiveness on extracting disentangled features, thereby facilitating speaker, style, or combined speaker-style conversion.
Cross-Domain Graph Data Scaling: A Showcase with Diffusion Models
Jun 04, 2024Models for natural language and images benefit from data scaling behavior: the more data fed into the model, the better they perform. This 'better with more' phenomenon enables the effectiveness of large-scale pre-training on vast amounts of data. However, current graph pre-training methods struggle to scale up data due to heterogeneity across graphs. To achieve effective data scaling, we aim to develop a general model that is able to capture diverse data patterns of graphs and can be utilized to adaptively help the downstream tasks. To this end, we propose UniAug, a universal graph structure augmentor built on a diffusion model. We first pre-train a discrete diffusion model on thousands of graphs across domains to learn the graph structural patterns. In the downstream phase, we provide adaptive enhancement by conducting graph structure augmentation with the help of the pre-trained diffusion model via guided generation. By leveraging the pre-trained diffusion model for structure augmentation, we consistently achieve performance improvements across various downstream tasks in a plug-and-play manner. To the best of our knowledge, this study represents the first demonstration of a data-scaling graph structure augmentor on graphs across domains.
Single-Cell Multimodal Prediction via Transformers
Mar 01, 2023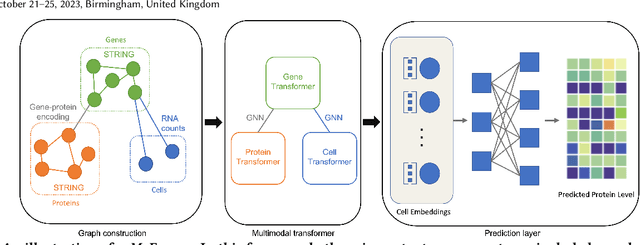
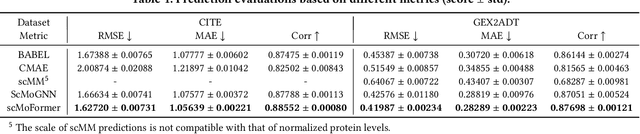
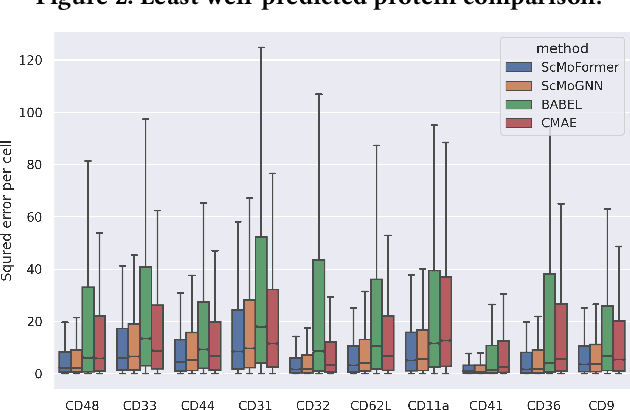
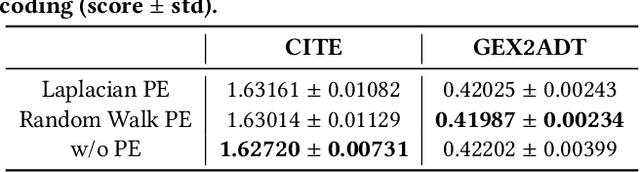
The recent development of multimodal single-cell technology has made the possibility of acquiring multiple omics data from individual cells, thereby enabling a deeper understanding of cellular states and dynamics. Nevertheless, the proliferation of multimodal single-cell data also introduces tremendous challenges in modeling the complex interactions among different modalities. The recently advanced methods focus on constructing static interaction graphs and applying graph neural networks (GNNs) to learn from multimodal data. However, such static graphs can be suboptimal as they do not take advantage of the downstream task information; meanwhile GNNs also have some inherent limitations when deeply stacking GNN layers. To tackle these issues, in this work, we investigate how to leverage transformers for multimodal single-cell data in an end-to-end manner while exploiting downstream task information. In particular, we propose a scMoFormer framework which can readily incorporate external domain knowledge and model the interactions within each modality and cross modalities. Extensive experiments demonstrate that scMoFormer achieves superior performance on various benchmark datasets. Note that scMoFormer won a Kaggle silver medal with the rank of $24\ /\ 1221$ (Top 2%) without ensemble in a NeurIPS 2022 competition. Our implementation is publicly available at Github.
Single Cells Are Spatial Tokens: Transformers for Spatial Transcriptomic Data Imputation
Feb 06, 2023
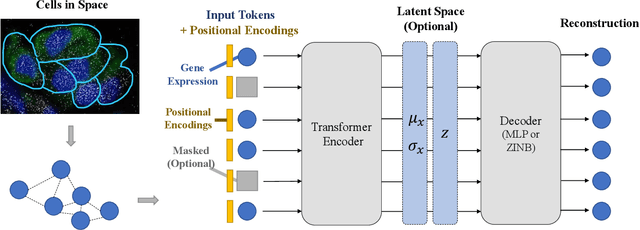
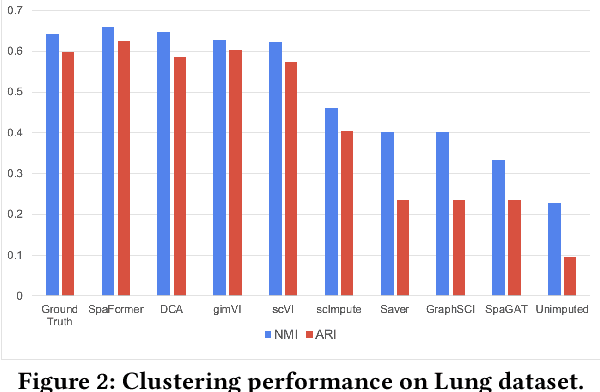
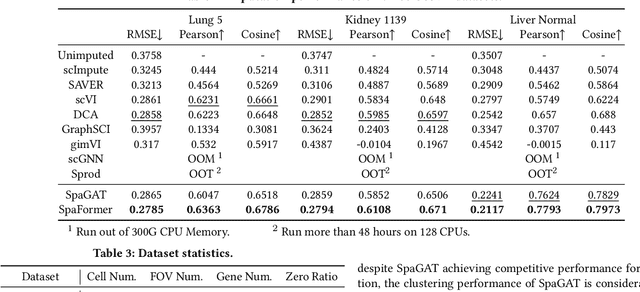
Spatially resolved transcriptomics brings exciting breakthroughs to single-cell analysis by providing physical locations along with gene expression. However, as a cost of the extremely high spatial resolution, the cellular level spatial transcriptomic data suffer significantly from missing values. While a standard solution is to perform imputation on the missing values, most existing methods either overlook spatial information or only incorporate localized spatial context without the ability to capture long-range spatial information. Using multi-head self-attention mechanisms and positional encoding, transformer models can readily grasp the relationship between tokens and encode location information. In this paper, by treating single cells as spatial tokens, we study how to leverage transformers to facilitate spatial tanscriptomics imputation. In particular, investigate the following two key questions: (1) $\textit{how to encode spatial information of cells in transformers}$, and (2) $\textit{ how to train a transformer for transcriptomic imputation}$. By answering these two questions, we present a transformer-based imputation framework, SpaFormer, for cellular-level spatial transcriptomic data. Extensive experiments demonstrate that SpaFormer outperforms existing state-of-the-art imputation algorithms on three large-scale datasets.
Improved disentangled speech representations using contrastive learning in factorized hierarchical variational autoencoder
Nov 15, 2022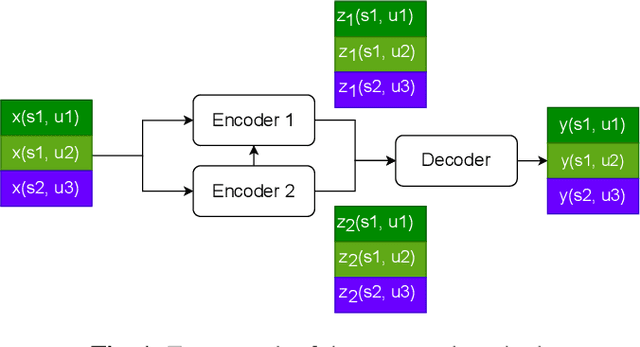
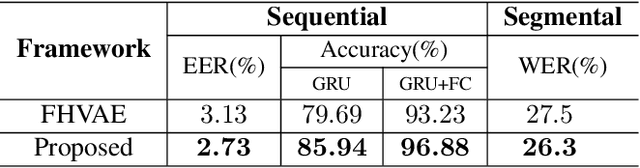
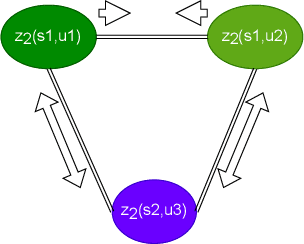
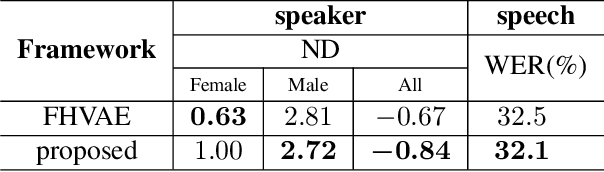
By utilizing the fact that speaker identity and content vary on different time scales, \acrlong{fhvae} (\acrshort{fhvae}) uses a sequential latent variable and a segmental latent variable to symbolize these two attributes. Disentanglement is carried out by assuming the latent variables representing speaker and content follow sequence-dependent and sequence-independent priors. For the sequence-dependent prior, \acrshort{fhvae} assumes a Gaussian distribution with an utterance-scale varying mean and a fixed small variance. The training process promotes sequential variables getting close to the mean of its prior with small variance. However, this constraint is relatively weak. Therefore, we introduce contrastive learning in the \acrshort{fhvae} framework. The proposed method aims to make the sequential variables clustering when representing the same speaker, while distancing themselves as far as possible from those of other speakers. The structure of the framework has not been changed in the proposed method but only the training process, thus no more cost is needed during test. Voice conversion has been chosen as the application in this paper. Latent variable evaluations include speakerincrease verification and identification for the sequential latent variable, and speech recognition for the segmental latent variable. Furthermore, assessments of voice conversion performance are on the grounds of speaker verification and speech recognition experiments. Experiment results show that the proposed method improves both sequential and segmental feature extraction compared with \acrshort{fhvae}, and moderately improved voice conversion performance.
Superiority of GNN over NN in generalizing bandlimited functions
Jun 13, 2022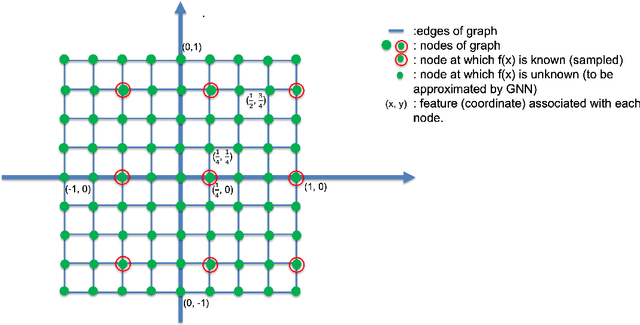
We constructively show, via rigorous mathematical arguments, that GNN architectures outperform those of NN in approximating bandlimited functions on compact $d$-dimensional Euclidean grids. We show that the former only need $\mathcal{M}$ sampled functional values in order to achieve a uniform approximation error of $O_{d}(2^{-\mathcal{M}^{1/d}})$ and that this error rate is optimal, in the sense that, NNs might achieve worse.
Complex Recurrent Variational Autoencoder for Speech Enhancement
Apr 05, 2022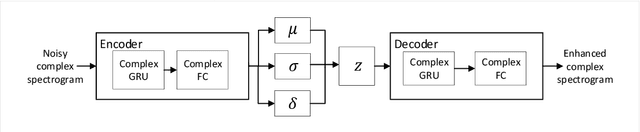
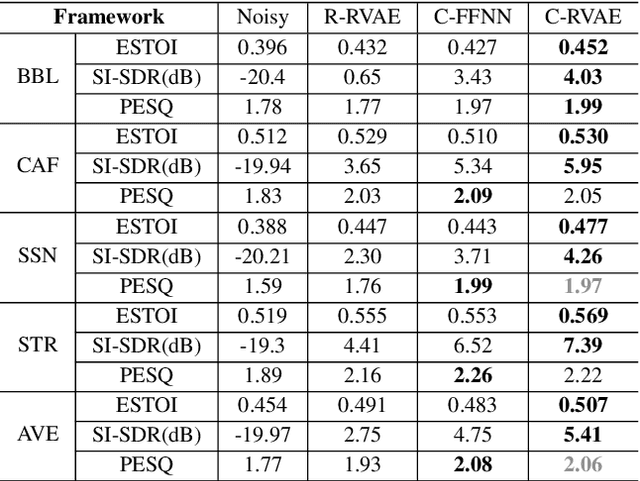
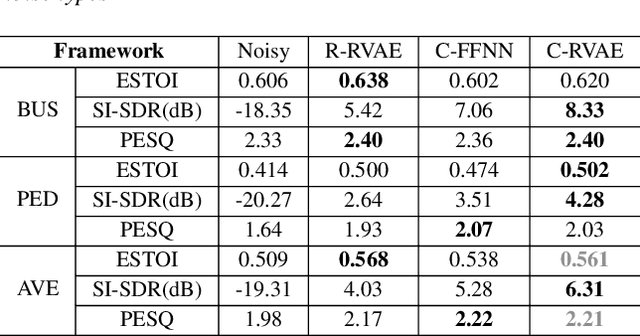
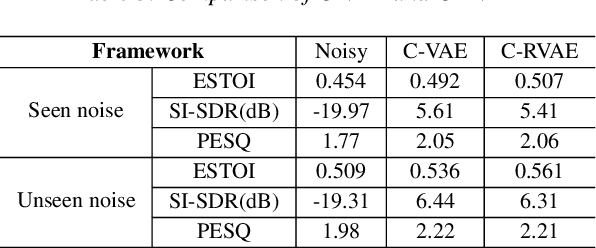
Commonly-used methods in speech enhancement are based on short-time fourier transform (STFT) representation, in particular on the magnitude of the STFT. This is because phase is naturally unstructured and intractable, and magnitude has shown more importance in speech enhancement. Nevertheless, phase has shown its significance in some research and cannot be ignored. Complex neural networks, with their inherent advantage, provide a solution for complex spectrogram processing. Complex variational autoencoder (VAE), as an extension of vanilla \acrshort{vae}, has shown positive results in complex spectrogram representation. However, the existing work on complex \acrshort{vae} only uses linear layers and merely applies the model on direct spectra representation. This paper extends the linear complex \acrshort{vae} to a non-linear one. Furthermore, on account of the temporal property of speech signals, a complex recurrent \acrshort{vae} is proposed. The proposed model has been applied on speech enhancement. As far as we know, it is the first time that a complex generative model is applied to speech enhancement. Experiments are based on the TIMIT dataset, while speech intelligibility and speech quality have been evaluated. The results show that, for speech enhancement, the proposed method has better performance on speech intelligibility and comparable performance on speech quality.
Disentangled Speech Representation Learning Based on Factorized Hierarchical Variational Autoencoder with Self-Supervised Objective
Apr 05, 2022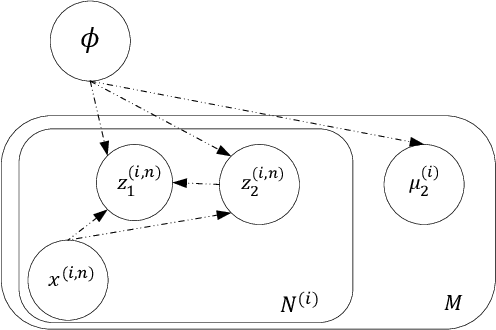

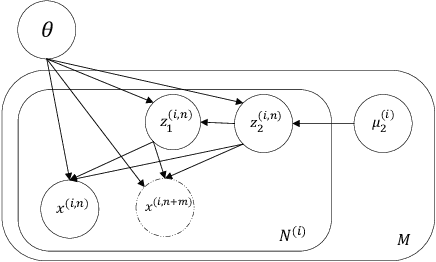
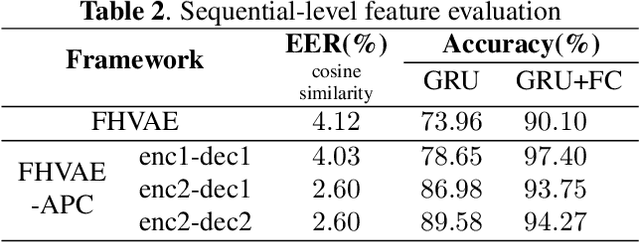
Disentangled representation learning aims to extract explanatory features or factors and retain salient information. Factorized hierarchical variational autoencoder (FHVAE) presents a way to disentangle a speech signal into sequential-level and segmental-level features, which represent speaker identity and speech content information, respectively. As a self-supervised objective, autoregressive predictive coding (APC), on the other hand, has been used in extracting meaningful and transferable speech features for multiple downstream tasks. Inspired by the success of these two representation learning methods, this paper proposes to integrate the APC objective into the FHVAE framework aiming at benefiting from the additional self-supervision target. The main proposed method requires neither more training data nor more computational cost at test time, but obtains improved meaningful representations while maintaining disentanglement. The experiments were conducted on the TIMIT dataset. Results demonstrate that FHVAE equipped with the additional self-supervised objective is able to learn features providing superior performance for tasks including speech recognition and speaker recognition. Furthermore, voice conversion, as one application of disentangled representation learning, has been applied and evaluated. The results show performance similar to baseline of the new framework on voice conversion.
Graph Neural Networks for Multimodal Single-Cell Data Integration
Mar 03, 2022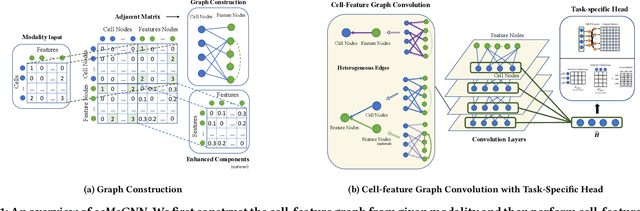
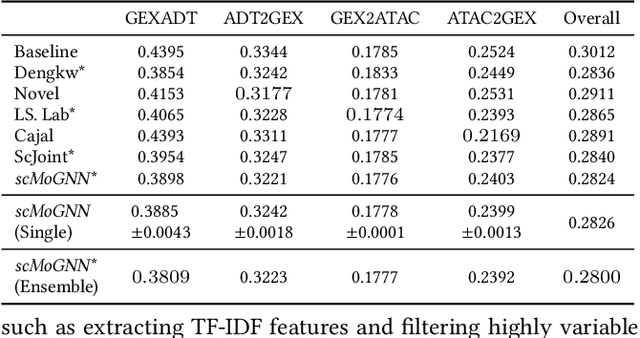
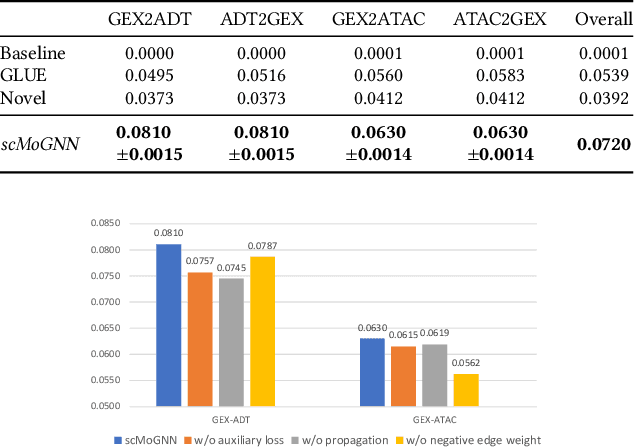
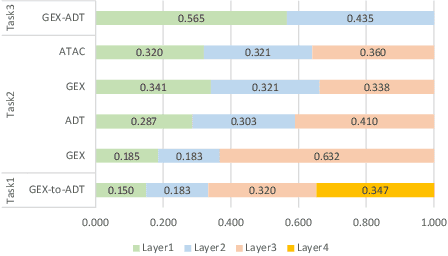
Recent advances in multimodal single-cell technologies have enabled simultaneous acquisitions of multiple omics data from the same cell, providing deeper insights into cellular states and dynamics. However, it is challenging to learn the joint representations from the multimodal data, model the relationship between modalities, and, more importantly, incorporate the vast amount of single-modality datasets into the downstream analyses. To address these challenges and correspondingly facilitate multimodal single-cell data analyses, three key tasks have been introduced: $\textit{modality prediction}$, $\textit{modality matching}$ and $\textit{joint embedding}$. In this work, we present a general Graph Neural Network framework $\textit{scMoGNN}$ to tackle these three tasks and show that $\textit{scMoGNN}$ demonstrates superior results in all three tasks compared with the state-of-the-art and conventional approaches. Our method is an official winner in the overall ranking of $\textit{modality prediction}$ from $\href{https://openproblems.bio/neurips_2021/}{\textit{NeurIPS 2021 Competition}}$.