 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Recurrent Variational Autoencoder for Speech Enhancement
Paper and Code
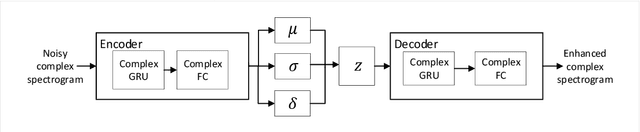
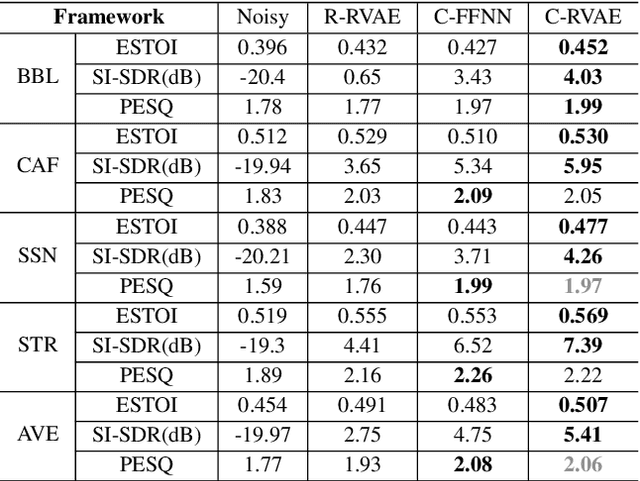
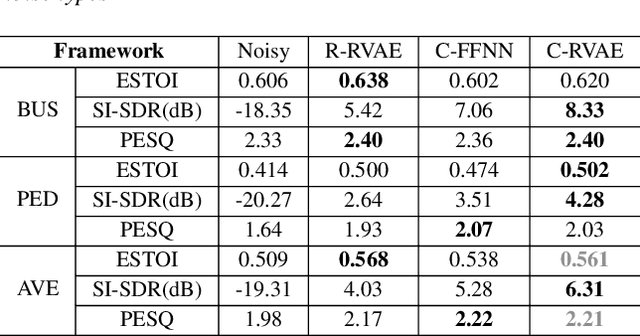
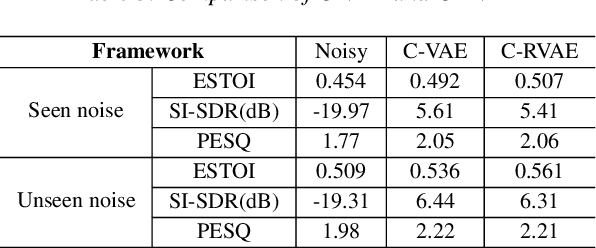
Commonly-used methods in speech enhancement are based on short-time fourier transform (STFT) representation, in particular on the magnitude of the STFT. This is because phase is naturally unstructured and intractable, and magnitude has shown more importance in speech enhancement. Nevertheless, phase has shown its significance in some research and cannot be ignored. Complex neural networks, with their inherent advantage, provide a solution for complex spectrogram processing. Complex variational autoencoder (VAE), as an extension of vanilla \acrshort{vae}, has shown positive results in complex spectrogram representation. However, the existing work on complex \acrshort{vae} only uses linear layers and merely applies the model on direct spectra representation. This paper extends the linear complex \acrshort{vae} to a non-linear one. Furthermore, on account of the temporal property of speech signals, a complex recurrent \acrshort{vae} is proposed. The proposed model has been applied on speech enhancement. As far as we know, it is the first time that a complex generative model is applied to speech enhancement. Experiments are based on the TIMIT dataset, while speech intelligibility and speech quality have been evaluated. The results show that, for speech enhancement, the proposed method has better performance on speech intelligibility and comparable performance on speech quality.