 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved disentangled speech representations using contrastive learning in factorized hierarchical variational autoencoder
Paper and Code
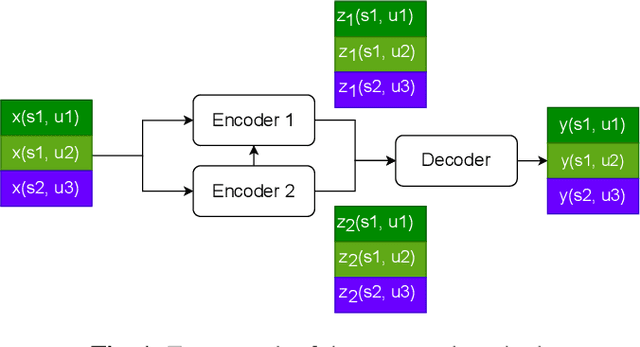
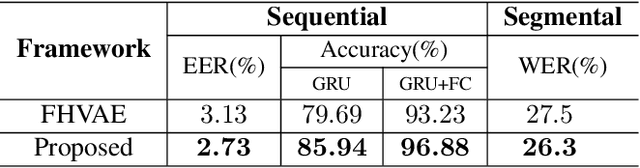
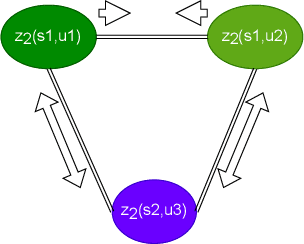
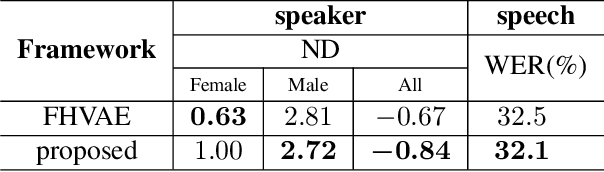
By utilizing the fact that speaker identity and content vary on different time scales, \acrlong{fhvae} (\acrshort{fhvae}) uses a sequential latent variable and a segmental latent variable to symbolize these two attributes. Disentanglement is carried out by assuming the latent variables representing speaker and content follow sequence-dependent and sequence-independent priors. For the sequence-dependent prior, \acrshort{fhvae} assumes a Gaussian distribution with an utterance-scale varying mean and a fixed small variance. The training process promotes sequential variables getting close to the mean of its prior with small variance. However, this constraint is relatively weak. Therefore, we introduce contrastive learning in the \acrshort{fhvae} framework. The proposed method aims to make the sequential variables clustering when representing the same speaker, while distancing themselves as far as possible from those of other speakers. The structure of the framework has not been changed in the proposed method but only the training process, thus no more cost is needed during test. Voice conversion has been chosen as the application in this paper. Latent variable evaluations include speakerincrease verification and identification for the sequential latent variable, and speech recognition for the segmental latent variable. Furthermore, assessments of voice conversion performance are on the grounds of speaker verification and speech recognition experiments. Experiment results show that the proposed method improves both sequential and segmental feature extraction compared with \acrshort{fhvae}, and moderately improved voice conversion performance.