 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Speech Representation Learning Based on Factorized Hierarchical Variational Autoencoder with Self-Supervised Objective
Paper and Code
Apr 05, 2022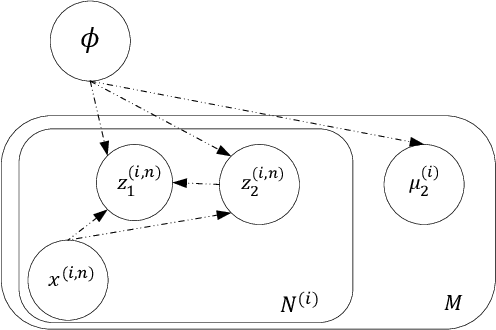

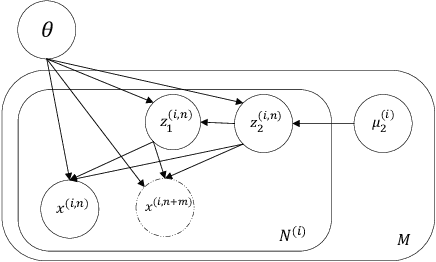
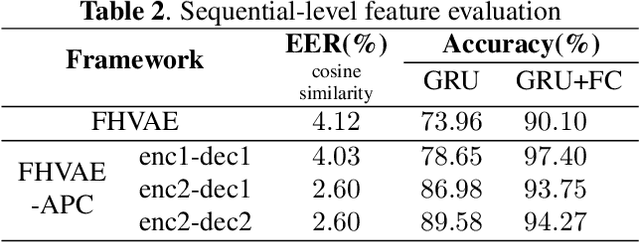
Disentangled representation learning aims to extract explanatory features or factors and retain salient information. Factorized hierarchical variational autoencoder (FHVAE) presents a way to disentangle a speech signal into sequential-level and segmental-level features, which represent speaker identity and speech content information, respectively. As a self-supervised objective, autoregressive predictive coding (APC), on the other hand, has been used in extracting meaningful and transferable speech features for multiple downstream tasks. Inspired by the success of these two representation learning methods, this paper proposes to integrate the APC objective into the FHVAE framework aiming at benefiting from the additional self-supervision target. The main proposed method requires neither more training data nor more computational cost at test time, but obtains improved meaningful representations while maintaining disentanglement. The experiments were conducted on the TIMIT dataset. Results demonstrate that FHVAE equipped with the additional self-supervised objective is able to learn features providing superior performance for tasks including speech recognition and speaker recognition. Furthermore, voice conversion, as one application of disentangled representation learning, has been applied and evaluated. The results show performance similar to baseline of the new framework on voice conversion.