 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRAJECT-Bench:A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use
Oct 06, 2025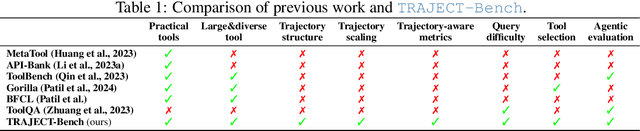

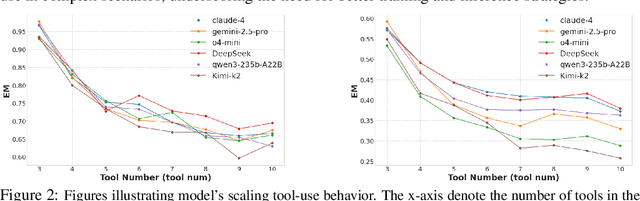
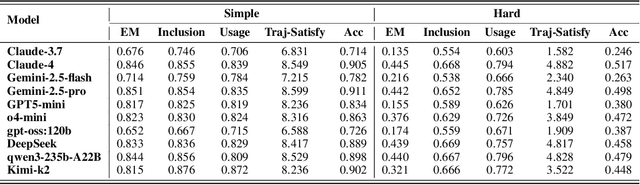
Large language model (LLM)-based agents increasingly rely on tool use to complete real-world tasks. While existing works evaluate the LLMs' tool use capability, they largely focus on the final answers yet overlook the detailed tool usage trajectory, i.e., whether tools are selected, parameterized, and ordered correctly. We introduce TRAJECT-Bench, a trajectory-aware benchmark to comprehensively evaluate LLMs' tool use capability through diverse tasks with fine-grained evaluation metrics. TRAJECT-Bench pairs high-fidelity, executable tools across practical domains with tasks grounded in production-style APIs, and synthesizes trajectories that vary in breadth (parallel calls) and depth (interdependent chains). Besides final accuracy, TRAJECT-Bench also reports trajectory-level diagnostics, including tool selection and argument correctness, and dependency/order satisfaction. Analyses reveal failure modes such as similar tool confusion and parameter-blind selection, and scaling behavior with tool diversity and trajectory length where the bottleneck of transiting from short to mid-length trajectories is revealed, offering actionable guidance for LLMs' tool use.
Retrieval-Augmented Generation with Graphs (GraphRAG)
Jan 08, 2025



Retrieval-augmented generation (RAG) is a powerful technique that enhances downstream task execution by retrieving additional information, such as knowledge, skills, and tools from external sources. Graph, by its intrinsic "nodes connected by edges" nature, encodes massive heterogeneous and relational information, making it a golden resource for RAG in tremendous real-world applications. As a result, we have recently witnessed increasing attention on equipping RAG with Graph, i.e., GraphRAG. However, unlike conventional RAG, where the retriever, generator, and external data sources can be uniformly designed in the neural-embedding space, the uniqueness of graph-structured data, such as diverse-formatted and domain-specific relational knowledge, poses unique and significant challenges when designing GraphRAG for different domains. Given the broad applicability, the associated design challenges, and the recent surge in GraphRAG, a systematic and up-to-date survey of its key concepts and techniques is urgently desired. Following this motivation, we present a comprehensive and up-to-date survey on GraphRAG. Our survey first proposes a holistic GraphRAG framework by defining its key components, including query processor, retriever, organizer, generator, and data source. Furthermore, recognizing that graphs in different domains exhibit distinct relational patterns and require dedicated designs, we review GraphRAG techniques uniquely tailored to each domain. Finally, we discuss research challenges and brainstorm directions to inspire cross-disciplinary opportunities. Our survey repository is publicly maintained at https://github.com/Graph-RAG/GraphRAG/.
Polaris: A Safety-focused LLM Constellation Architecture for Healthcare
Mar 20, 2024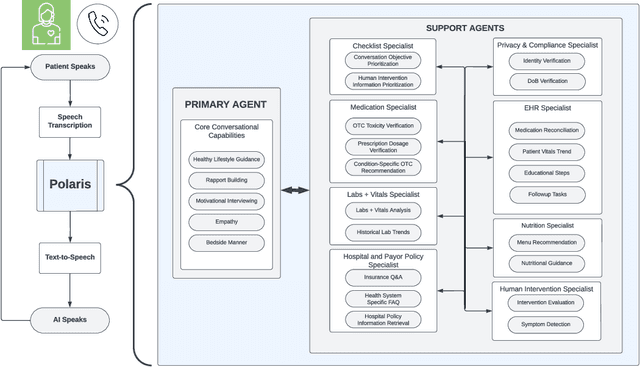
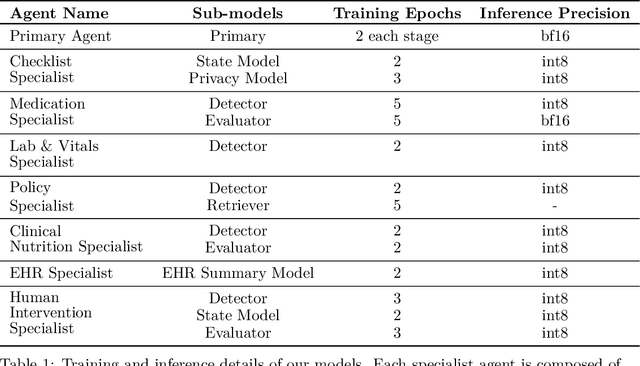
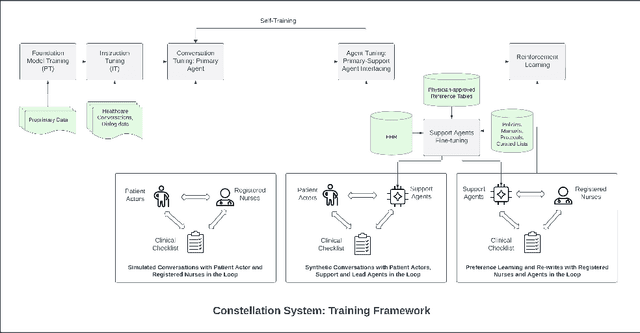
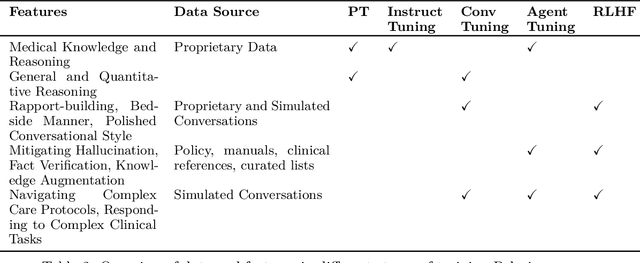
We develop Polaris, the first safety-focused LLM constellation for real-time patient-AI healthcare conversations. Unlike prior LLM works in healthcare focusing on tasks like question answering, our work specifically focuses on long multi-turn voice conversations. Our one-trillion parameter constellation system is composed of several multibillion parameter LLMs as co-operative agents: a stateful primary agent that focuses on driving an engaging conversation and several specialist support agents focused on healthcare tasks performed by nurses to increase safety and reduce hallucinations. We develop a sophisticated training protocol for iterative co-training of the agents that optimize for diverse objectives. We train our models on proprietary data, clinical care plans, healthcare regulatory documents, medical manuals, and other medical reasoning documents. We align our models to speak like medical professionals, using organic healthcare conversations and simulated ones between patient actors and experienced nurses. This allows our system to express unique capabilities such as rapport building, trust building, empathy and bedside manner. Finally, we present the first comprehensive clinician evaluation of an LLM system for healthcare. We recruited over 1100 U.S. licensed nurses and over 130 U.S. licensed physicians to perform end-to-end conversational evaluations of our system by posing as patients and rating the system on several measures. We demonstrate Polaris performs on par with human nurses on aggregate across dimensions such as medical safety, clinical readiness, conversational quality, and bedside manner. Additionally, we conduct a challenging task-based evaluation of the individual specialist support agents, where we demonstrate our LLM agents significantly outperform a much larger general-purpose LLM (GPT-4) as well as from its own medium-size class (LLaMA-2 70B).
Copyright Protection in Generative AI: A Technical Perspective
Feb 04, 2024



Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
Single-Cell Multimodal Prediction via Transformers
Mar 01, 2023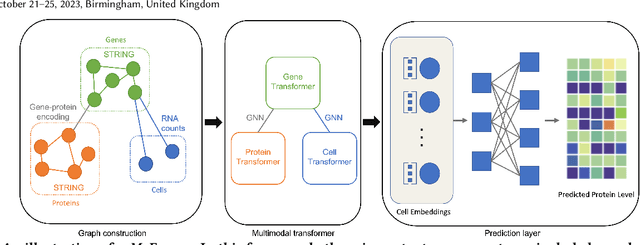
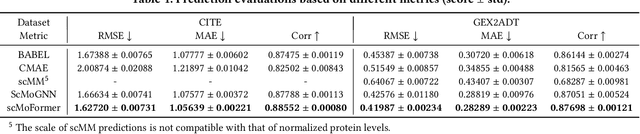
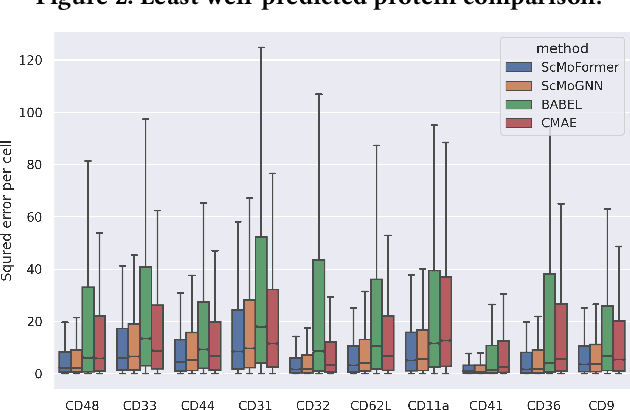
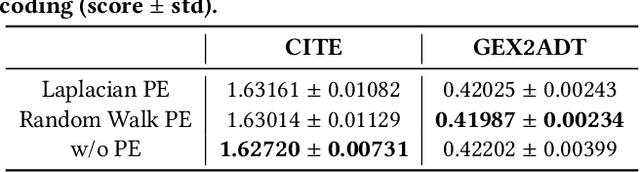
The recent development of multimodal single-cell technology has made the possibility of acquiring multiple omics data from individual cells, thereby enabling a deeper understanding of cellular states and dynamics. Nevertheless, the proliferation of multimodal single-cell data also introduces tremendous challenges in modeling the complex interactions among different modalities. The recently advanced methods focus on constructing static interaction graphs and applying graph neural networks (GNNs) to learn from multimodal data. However, such static graphs can be suboptimal as they do not take advantage of the downstream task information; meanwhile GNNs also have some inherent limitations when deeply stacking GNN layers. To tackle these issues, in this work, we investigate how to leverage transformers for multimodal single-cell data in an end-to-end manner while exploiting downstream task information. In particular, we propose a scMoFormer framework which can readily incorporate external domain knowledge and model the interactions within each modality and cross modalities. Extensive experiments demonstrate that scMoFormer achieves superior performance on various benchmark datasets. Note that scMoFormer won a Kaggle silver medal with the rank of $24\ /\ 1221$ (Top 2%) without ensemble in a NeurIPS 2022 competition. Our implementation is publicly available at Github.
Single Cells Are Spatial Tokens: Transformers for Spatial Transcriptomic Data Imputation
Feb 06, 2023
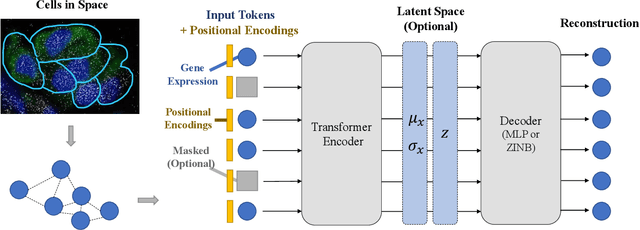
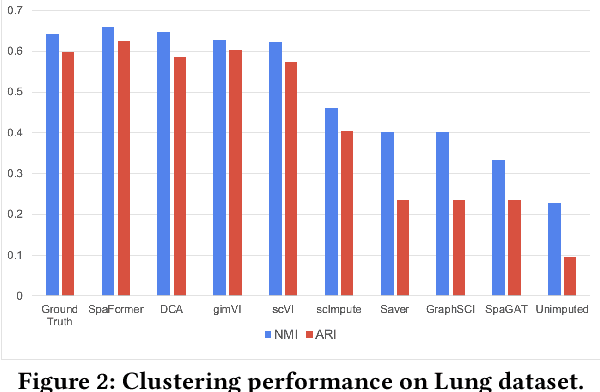
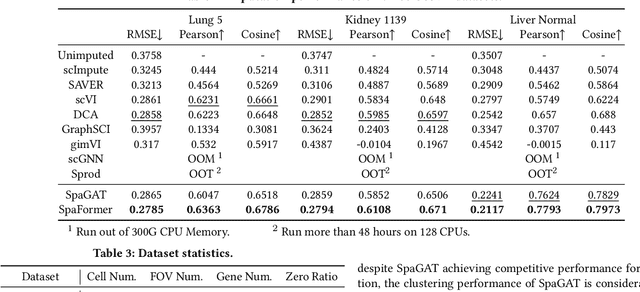
Spatially resolved transcriptomics brings exciting breakthroughs to single-cell analysis by providing physical locations along with gene expression. However, as a cost of the extremely high spatial resolution, the cellular level spatial transcriptomic data suffer significantly from missing values. While a standard solution is to perform imputation on the missing values, most existing methods either overlook spatial information or only incorporate localized spatial context without the ability to capture long-range spatial information. Using multi-head self-attention mechanisms and positional encoding, transformer models can readily grasp the relationship between tokens and encode location information. In this paper, by treating single cells as spatial tokens, we study how to leverage transformers to facilitate spatial tanscriptomics imputation. In particular, investigate the following two key questions: (1) $\textit{how to encode spatial information of cells in transformers}$, and (2) $\textit{ how to train a transformer for transcriptomic imputation}$. By answering these two questions, we present a transformer-based imputation framework, SpaFormer, for cellular-level spatial transcriptomic data. Extensive experiments demonstrate that SpaFormer outperforms existing state-of-the-art imputation algorithms on three large-scale datasets.
Empowering Graph Representation Learning with Test-Time Graph Transformation
Oct 07, 2022
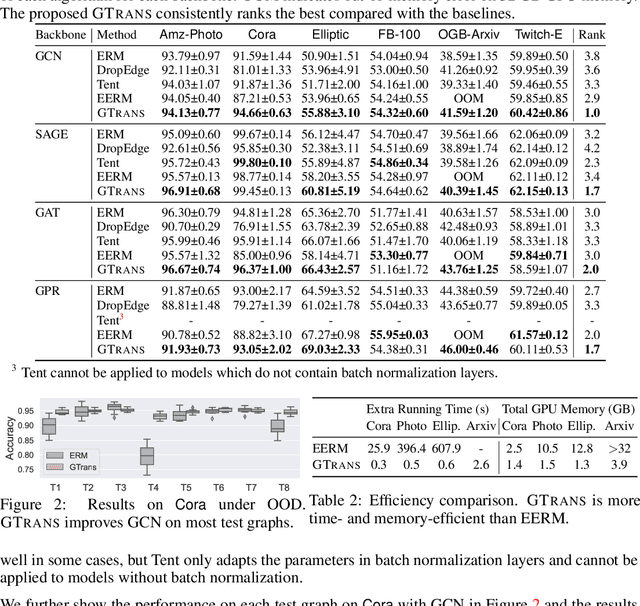
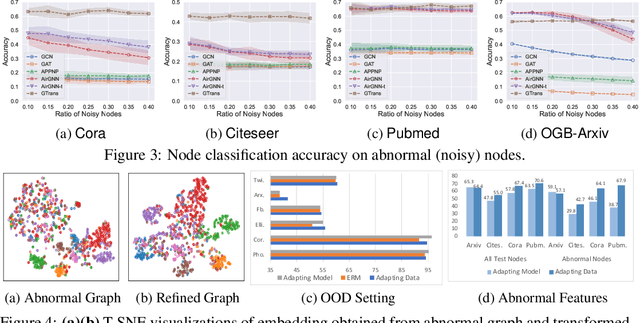

As powerful tools for representation learning on graphs, graph neural networks (GNNs) have facilitated various applications from drug discovery to recommender systems. Nevertheless, the effectiveness of GNNs is immensely challenged by issues related to data quality, such as distribution shift, abnormal features and adversarial attacks. Recent efforts have been made on tackling these issues from a modeling perspective which requires additional cost of changing model architectures or re-training model parameters. In this work, we provide a data-centric view to tackle these issues and propose a graph transformation framework named GTrans which adapts and refines graph data at test time to achieve better performance. We provide theoretical analysis on the design of the framework and discuss why adapting graph data works better than adapting the model. Extensive experiments have demonstrated the effectiveness of GTrans on three distinct scenarios for eight benchmark datasets where suboptimal data is presented. Remarkably, GTrans performs the best in most cases with improvements up to 2.8%, 8.2% and 3.8% over the best baselines on three experimental settings.
Are Graph Neural Networks Really Helpful for Knowledge Graph Completion?
May 21, 2022



Knowledge graphs (KGs) facilitate a wide variety of applications due to their ability to store relational knowledge applicable to many areas. Despite great efforts invested in creation and maintenance, even the largest KGs are far from complete. Hence, KG completion (KGC) has become one of the most crucial tasks for KG research. Recently, considerable literature in this space has centered around the use of Graph Neural Networks (GNNs) to learn powerful embeddings which leverage topological structures in the KGs. Specifically, dedicated efforts have been made to extend GNNs, which are commonly designed for simple homogeneous and uni-relational graphs, to the KG context which has diverse and multi-relational connections between entities, by designing more complex aggregation schemes over neighboring nodes (crucial to GNN performance) to appropriately leverage multi-relational information. The success of these methods is naturally attributed to the use of GNNs over simpler multi-layer perceptron (MLP) models, owing to their additional aggregation functionality. In this work, we find that surprisingly, simple MLP models are able to achieve comparable performance to GNNs, suggesting that aggregation may not be as crucial as previously believed. With further exploration, we show careful scoring function and loss function design has a much stronger influence on KGC model performance, and aggregation is not practically required. This suggests a conflation of scoring function design, loss function design, and aggregation in prior work, with promising insights regarding the scalability of state-of-the-art KGC methods today, as well as careful attention to more suitable aggregation designs for KGC tasks tomorrow.
Graph Neural Networks for Multimodal Single-Cell Data Integration
Mar 03, 2022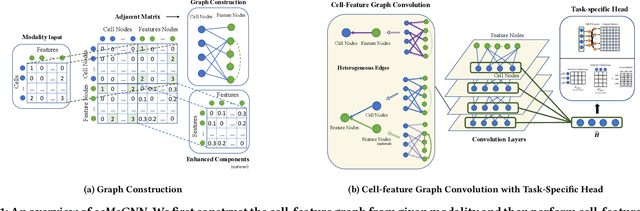
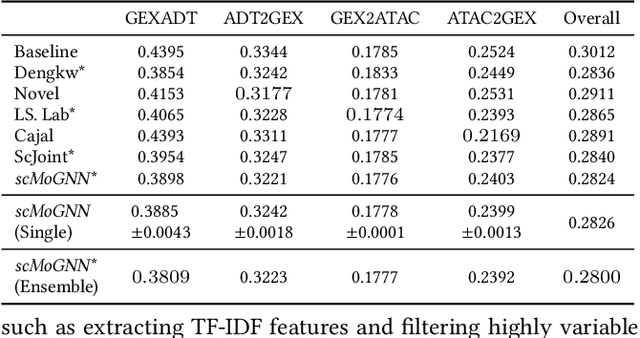
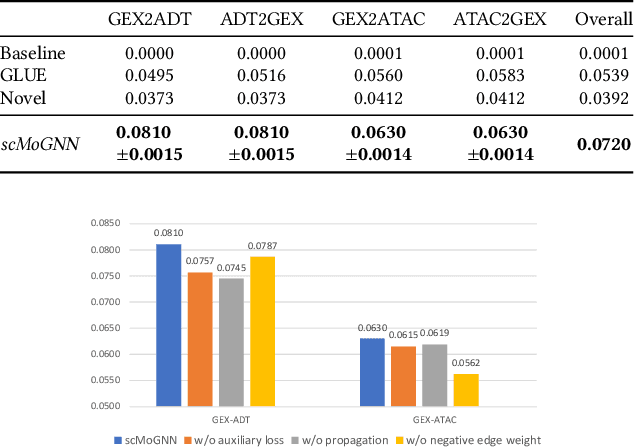
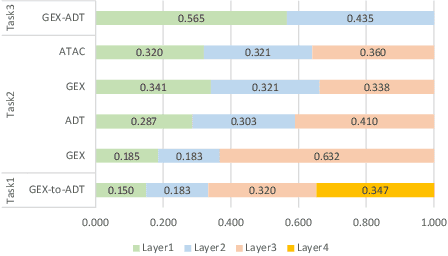
Recent advances in multimodal single-cell technologies have enabled simultaneous acquisitions of multiple omics data from the same cell, providing deeper insights into cellular states and dynamics. However, it is challenging to learn the joint representations from the multimodal data, model the relationship between modalities, and, more importantly, incorporate the vast amount of single-modality datasets into the downstream analyses. To address these challenges and correspondingly facilitate multimodal single-cell data analyses, three key tasks have been introduced: $\textit{modality prediction}$, $\textit{modality matching}$ and $\textit{joint embedding}$. In this work, we present a general Graph Neural Network framework $\textit{scMoGNN}$ to tackle these three tasks and show that $\textit{scMoGNN}$ demonstrates superior results in all three tasks compared with the state-of-the-art and conventional approaches. Our method is an official winner in the overall ranking of $\textit{modality prediction}$ from $\href{https://openproblems.bio/neurips_2021/}{\textit{NeurIPS 2021 Competition}}$.
Tell Me How to Survey: Literature Review Made Simple with Automatic Reading Path Generation
Oct 14, 2021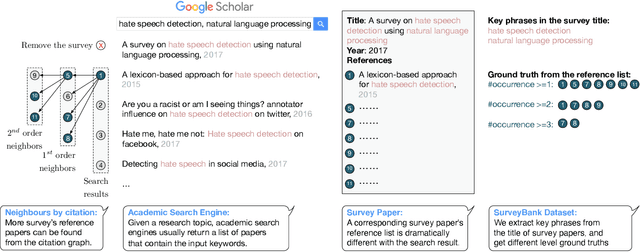
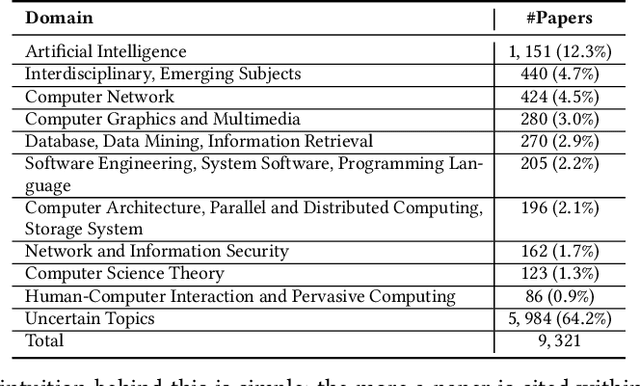
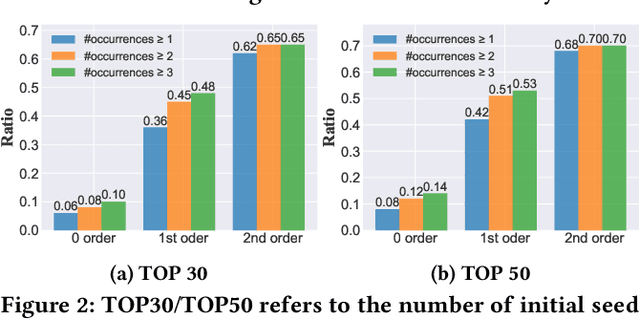

Recent years have witnessed the dramatic growth of paper volumes with plenty of new research papers published every day, especially in the area of computer science. How to glean papers worth reading from the massive literature to do a quick survey or keep up with the latest advancement about a specific research topic has become a challenging task. Existing academic search engines such as Google Scholar return relevant papers by individually calculating the relevance between each paper and query. However, such systems usually omit the prerequisite chains of a research topic and cannot form a meaningful reading path. In this paper, we introduce a new task named Reading Path Generation (RPG) which aims at automatically producing a path of papers to read for a given query. To serve as a research benchmark, we further propose SurveyBank, a dataset consisting of large quantities of survey papers in the field of computer science as well as their citation relationships. Each survey paper contains key phrases extracted from its title and multi-level reading lists inferred from its references. Furthermore, we propose a graph-optimization-based approach for reading path generation which takes the relationship between papers into account. Extensive evaluations demonstrate that our approach outperforms other baselines. A Real-time Reading Path Generation System (RePaGer) has been also implemented with our designed model. To the best of our knowledge, we are the first to target this important research problem. Our source code of RePaGer system and SurveyBank dataset can be found on here.