 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeMo-Aligner: Scalable Toolkit for Efficient Model Alignment
May 02, 2024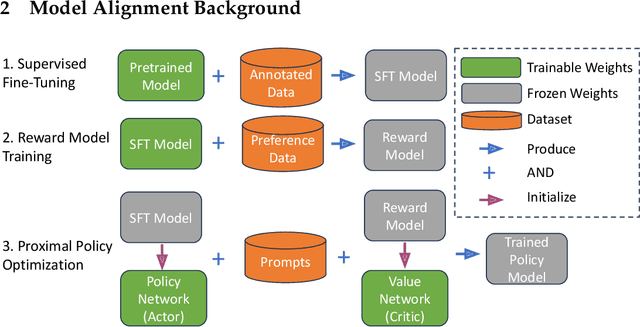
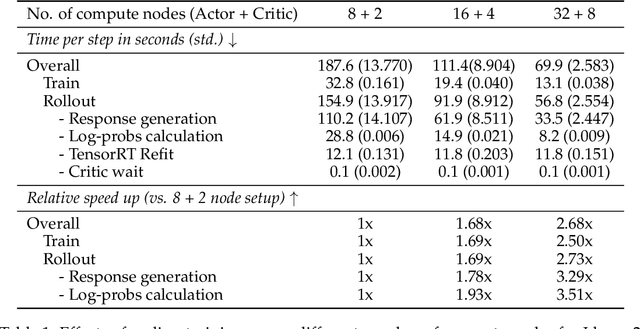

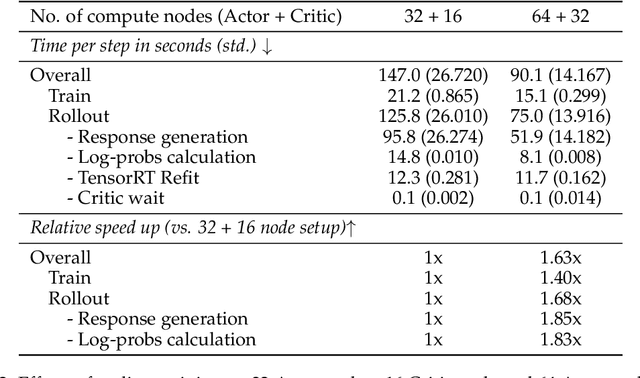
Aligning Large Language Models (LLMs) with human values and preferences is essential for making them helpful and safe. However, building efficient tools to perform alignment can be challenging, especially for the largest and most competent LLMs which often contain tens or hundreds of billions of parameters. We create NeMo-Aligner, a toolkit for model alignment that can efficiently scale to using hundreds of GPUs for training. NeMo-Aligner comes with highly optimized and scalable implementations for major paradigms of model alignment such as: Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), SteerLM, and Self-Play Fine-Tuning (SPIN). Additionally, our toolkit supports running most of the alignment techniques in a Parameter Efficient Fine-Tuning (PEFT) setting. NeMo-Aligner is designed for extensibility, allowing support for other alignment techniques with minimal effort. It is open-sourced with Apache 2.0 License and we invite community contributions at https://github.com/NVIDIA/NeMo-Aligner
Polaris: A Safety-focused LLM Constellation Architecture for Healthcare
Mar 20, 2024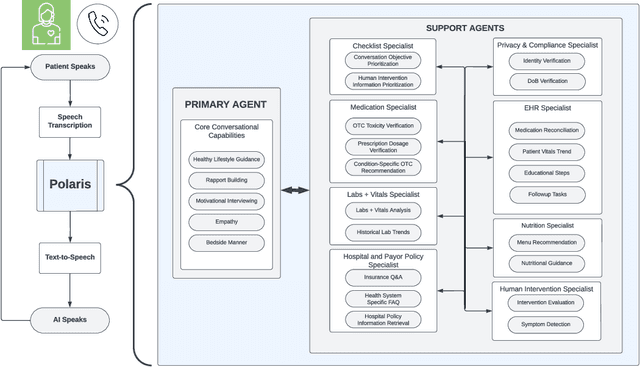
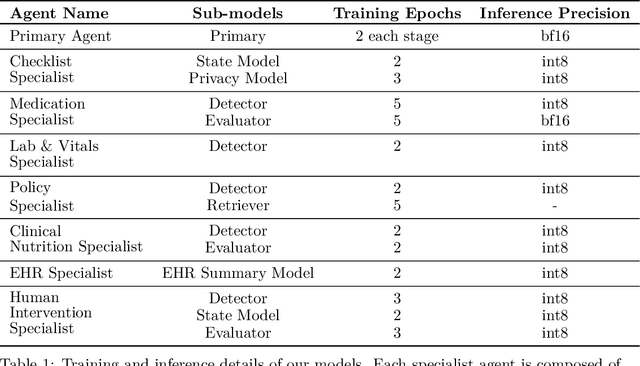
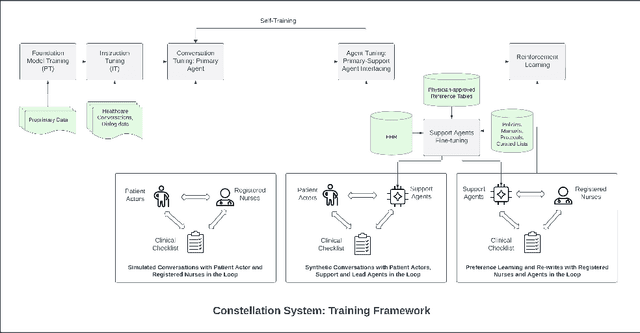
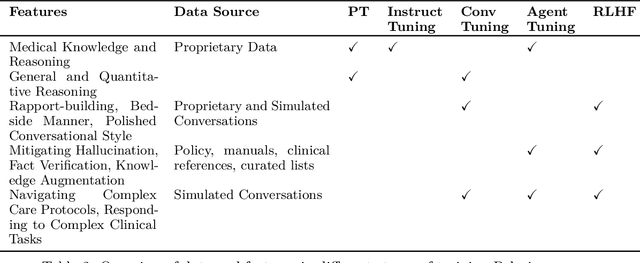
We develop Polaris, the first safety-focused LLM constellation for real-time patient-AI healthcare conversations. Unlike prior LLM works in healthcare focusing on tasks like question answering, our work specifically focuses on long multi-turn voice conversations. Our one-trillion parameter constellation system is composed of several multibillion parameter LLMs as co-operative agents: a stateful primary agent that focuses on driving an engaging conversation and several specialist support agents focused on healthcare tasks performed by nurses to increase safety and reduce hallucinations. We develop a sophisticated training protocol for iterative co-training of the agents that optimize for diverse objectives. We train our models on proprietary data, clinical care plans, healthcare regulatory documents, medical manuals, and other medical reasoning documents. We align our models to speak like medical professionals, using organic healthcare conversations and simulated ones between patient actors and experienced nurses. This allows our system to express unique capabilities such as rapport building, trust building, empathy and bedside manner. Finally, we present the first comprehensive clinician evaluation of an LLM system for healthcare. We recruited over 1100 U.S. licensed nurses and over 130 U.S. licensed physicians to perform end-to-end conversational evaluations of our system by posing as patients and rating the system on several measures. We demonstrate Polaris performs on par with human nurses on aggregate across dimensions such as medical safety, clinical readiness, conversational quality, and bedside manner. Additionally, we conduct a challenging task-based evaluation of the individual specialist support agents, where we demonstrate our LLM agents significantly outperform a much larger general-purpose LLM (GPT-4) as well as from its own medium-size class (LLaMA-2 70B).
HOPE: Human-Centric Off-Policy Evaluation for E-Learning and Healthcare
Feb 18, 2023Reinforcement learning (RL) has been extensively researched for enhancing human-environment interactions in various human-centric tasks, including e-learning and healthcare. Since deploying and evaluating policies online are high-stakes in such tasks, off-policy evaluation (OPE) is crucial for inducing effective policies. In human-centric environments, however, OPE is challenging because the underlying state is often unobservable, while only aggregate rewards can be observed (students' test scores or whether a patient is released from the hospital eventually). In this work, we propose a human-centric OPE (HOPE) to handle partial observability and aggregated rewards in such environments. Specifically, we reconstruct immediate rewards from the aggregated rewards considering partial observability to estimate expected total returns. We provide a theoretical bound for the proposed method, and we have conducted extensive experiments in real-world human-centric tasks, including sepsis treatments and an intelligent tutoring system. Our approach reliably predicts the returns of different policies and outperforms state-of-the-art benchmarks using both standard validation methods and human-centric significance tests.
InferNet for Delayed Reinforcement Tasks: Addressing the Temporal Credit Assignment Problem
May 02, 2021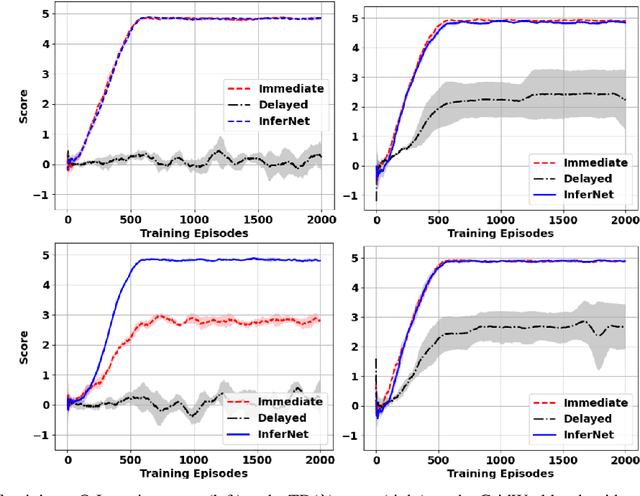



The temporal Credit Assignment Problem (CAP) is a well-known and challenging task in AI. While Reinforcement Learning (RL), especially Deep RL, works well when immediate rewards are available, it can fail when only delayed rewards are available or when the reward function is noisy. In this work, we propose delegating the CAP to a Neural Network-based algorithm named InferNet that explicitly learns to infer the immediate rewards from the delayed rewards. The effectiveness of InferNet was evaluated on two online RL tasks: a simple GridWorld and 40 Atari games; and two offline RL tasks: GridWorld and a real-life Sepsis treatment task. For all tasks, the effectiveness of using the InferNet inferred rewards is compared against the immediate and the delayed rewards with two settings: with noisy rewards and without noise. Overall, our results show that the effectiveness of InferNet is robust against noisy reward functions and is an effective add-on mechanism for solving temporal CAP in a wide range of RL tasks, from classic RL simulation environments to a real-world RL problem and for both online and offline learning.