 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactNet: A Billion-Scale Knowledge Graph for Multilingual Factual Grounding
Feb 03, 2026While LLMs exhibit remarkable fluency, their utility is often compromised by factual hallucinations and a lack of traceable provenance. Existing resources for grounding mitigate this but typically enforce a dichotomy: they offer either structured knowledge without textual context (e.g., knowledge bases) or grounded text with limited scale and linguistic coverage. To bridge this gap, we introduce FactNet, a massive, open-source resource designed to unify 1.7 billion atomic assertions with 3.01 billion auditable evidence pointers derived exclusively from 316 Wikipedia editions. Unlike recent synthetic approaches, FactNet employs a strictly deterministic construction pipeline, ensuring that every evidence unit is recoverable with byte-level precision. Extensive auditing confirms a high grounding precision of 92.1%, even in long-tail languages. Furthermore, we establish FactNet-Bench, a comprehensive evaluation suite for Knowledge Graph Completion, Question Answering, and Fact Checking. FactNet provides the community with a foundational, reproducible resource for training and evaluating trustworthy, verifiable multilingual systems.
LPS-Bench: Benchmarking Safety Awareness of Computer-Use Agents in Long-Horizon Planning under Benign and Adversarial Scenarios
Feb 03, 2026Computer-use agents (CUAs) that interact with real computer systems can perform automated tasks but face critical safety risks. Ambiguous instructions may trigger harmful actions, and adversarial users can manipulate tool execution to achieve malicious goals. Existing benchmarks mostly focus on short-horizon or GUI-based tasks, evaluating on execution-time errors but overlooking the ability to anticipate planning-time risks. To fill this gap, we present LPS-Bench, a benchmark that evaluates the planning-time safety awareness of MCP-based CUAs under long-horizon tasks, covering both benign and adversarial interactions across 65 scenarios of 7 task domains and 9 risk types. We introduce a multi-agent automated pipeline for scalable data generation and adopt an LLM-as-a-judge evaluation protocol to assess safety awareness through the planning trajectory. Experiments reveal substantial deficiencies in existing CUAs' ability to maintain safe behavior. We further analyze the risks and propose mitigation strategies to improve long-horizon planning safety in MCP-based CUA systems. We open-source our code at https://github.com/tychenn/LPS-Bench.
Zero-Shot Stance Detection in the Wild: Dynamic Target Generation and Multi-Target Adaptation
Jan 28, 2026Current stance detection research typically relies on predicting stance based on given targets and text. However, in real-world social media scenarios, targets are neither predefined nor static but rather complex and dynamic. To address this challenge, we propose a novel task: zero-shot stance detection in the wild with Dynamic Target Generation and Multi-Target Adaptation (DGTA), which aims to automatically identify multiple target-stance pairs from text without prior target knowledge. We construct a Chinese social media stance detection dataset and design multi-dimensional evaluation metrics. We explore both integrated and two-stage fine-tuning strategies for large language models (LLMs) and evaluate various baseline models. Experimental results demonstrate that fine-tuned LLMs achieve superior performance on this task: the two-stage fine-tuned Qwen2.5-7B attains the highest comprehensive target recognition score of 66.99%, while the integrated fine-tuned DeepSeek-R1-Distill-Qwen-7B achieves a stance detection F1 score of 79.26%.
Principled Fine-tuning of LLMs from User-Edits: A Medley of Preference, Supervision, and Reward
Jan 27, 2026We study how to fine-tune LLMs using user-edit deployment data consisting of a set of context, an agent's response, and user edits. This deployment data is naturally generated by users in applications such as LLMs-based writing assistants and coding agents. The _natural_ origin of user edits makes it a desired source for adapting and personalizing LLMs. In this setup, there emerges a unification of various feedback types namely preferences, supervised labels, and cost that are typically studied separately in the literature. In this paper, we initiate the theoretical investigation of learning from user edits. We first derive bounds for learning algorithms that learn from each of these feedback types. We prove that these algorithms have different trade-offs depending upon the user, data distribution, and model class. We then propose a simple ensembling procedure to jointly learn from these feedback types. On two domains adapted from Gao et al. 2024, we show our ensembling procedure outperforms these methods that learn from individual feedback. Further, we show that our proposed procedure can robustly adapt to different user-edit distributions at test time.
GFix: Perceptually Enhanced Gaussian Splatting Video Compression
Nov 10, 2025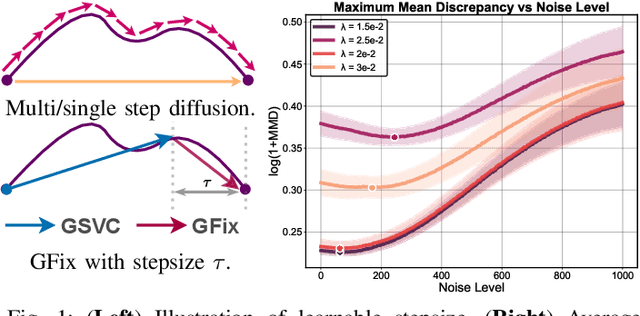
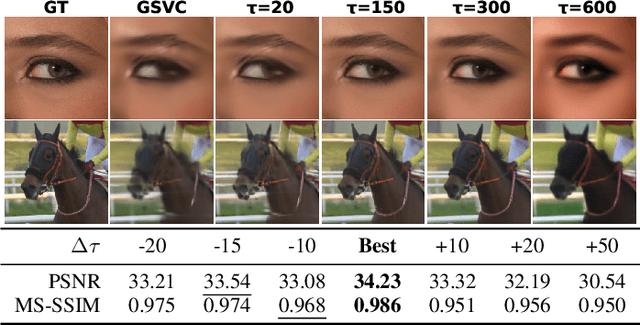
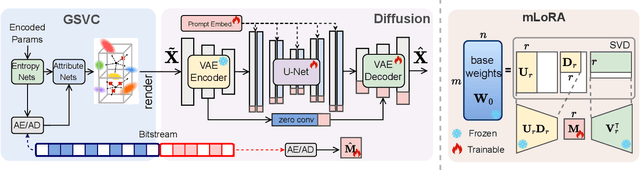
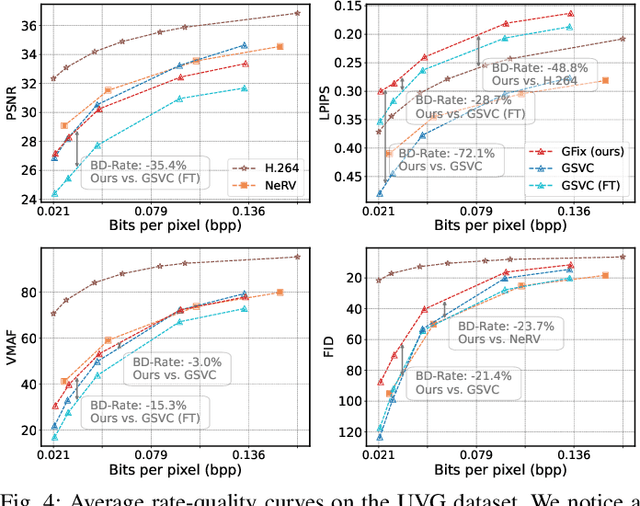
3D Gaussian Splatting (3DGS) enhances 3D scene reconstruction through explicit representation and fast rendering, demonstrating potential benefits for various low-level vision tasks, including video compression. However, existing 3DGS-based video codecs generally exhibit more noticeable visual artifacts and relatively low compression ratios. In this paper, we specifically target the perceptual enhancement of 3DGS-based video compression, based on the assumption that artifacts from 3DGS rendering and quantization resemble noisy latents sampled during diffusion training. Building on this premise, we propose a content-adaptive framework, GFix, comprising a streamlined, single-step diffusion model that serves as an off-the-shelf neural enhancer. Moreover, to increase compression efficiency, We propose a modulated LoRA scheme that freezes the low-rank decompositions and modulates the intermediate hidden states, thereby achieving efficient adaptation of the diffusion backbone with highly compressible updates. Experimental results show that GFix delivers strong perceptual quality enhancement, outperforming GSVC with up to 72.1% BD-rate savings in LPIPS and 21.4% in FID.
Vision Transformer for Robust Occluded Person Reidentification in Complex Surveillance Scenes
Oct 31, 2025Person re-identification (ReID) in surveillance is challenged by occlusion, viewpoint distortion, and poor image quality. Most existing methods rely on complex modules or perform well only on clear frontal images. We propose Sh-ViT (Shuffling Vision Transformer), a lightweight and robust model for occluded person ReID. Built on ViT-Base, Sh-ViT introduces three components: First, a Shuffle module in the final Transformer layer to break spatial correlations and enhance robustness to occlusion and blur; Second, scenario-adapted augmentation (geometric transforms, erasing, blur, and color adjustment) to simulate surveillance conditions; Third, DeiT-based knowledge distillation to improve learning with limited labels.To support real-world evaluation, we construct the MyTT dataset, containing over 10,000 pedestrians and 30,000+ images from base station inspections, with frequent equipment occlusion and camera variations. Experiments show that Sh-ViT achieves 83.2% Rank-1 and 80.1% mAP on MyTT, outperforming CNN and ViT baselines, and 94.6% Rank-1 and 87.5% mAP on Market1501, surpassing state-of-the-art methods.In summary, Sh-ViT improves robustness to occlusion and blur without external modules, offering a practical solution for surveillance-based personnel monitoring.
PERRY: Policy Evaluation with Confidence Intervals using Auxiliary Data
Jul 26, 2025Off-policy evaluation (OPE) methods aim to estimate the value of a new reinforcement learning (RL) policy prior to deployment. Recent advances have shown that leveraging auxiliary datasets, such as those synthesized by generative models, can improve the accuracy of these value estimates. Unfortunately, such auxiliary datasets may also be biased, and existing methods for using data augmentation for OPE in RL lack principled uncertainty quantification. In high stakes settings like healthcare, reliable uncertainty estimates are important for comparing policy value estimates. In this work, we propose two approaches to construct valid confidence intervals for OPE when using data augmentation. The first provides a confidence interval over the policy performance conditioned on a particular initial state $V^{\pi}(s_0)$-- such intervals are particularly important for human-centered applications. To do so we introduce a new conformal prediction method for high dimensional state MDPs. Second, we consider the more common task of estimating the average policy performance over many initial states; to do so we draw on ideas from doubly robust estimation and prediction powered inference. Across simulators spanning robotics, healthcare and inventory management, and a real healthcare dataset from MIMIC-IV, we find that our methods can use augmented data and still consistently produce intervals that cover the ground truth values, unlike previously proposed methods.
An Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
Instance Data Condensation for Image Super-Resolution
May 27, 2025
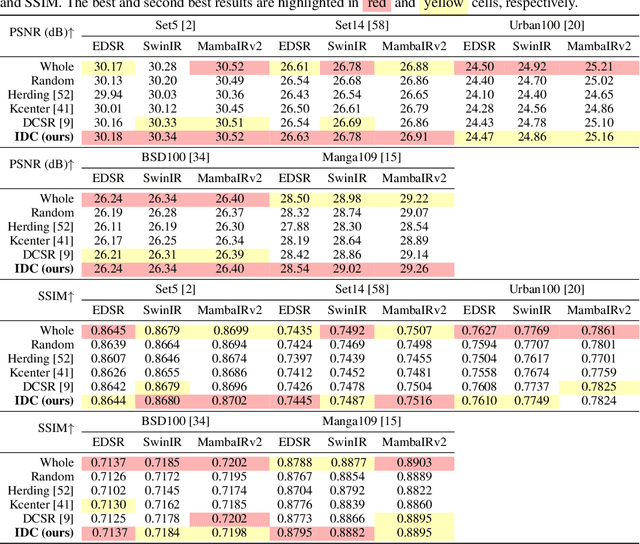
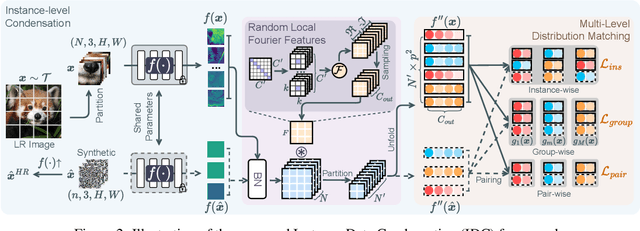
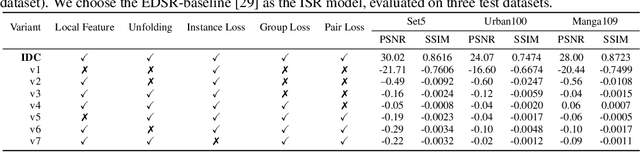
Deep learning based image Super-Resolution (ISR) relies on large training datasets to optimize model generalization; this requires substantial computational and storage resources during training. While dataset condensation has shown potential in improving data efficiency and privacy for high-level computer vision tasks, it has not yet been fully exploited for ISR. In this paper, we propose a novel Instance Data Condensation (IDC) framework specifically for ISR, which achieves instance-level data condensation through Random Local Fourier Feature Extraction and Multi-level Feature Distribution Matching. This aims to optimize feature distributions at both global and local levels and obtain high-quality synthesized training content with fine detail. This framework has been utilized to condense the most commonly used training dataset for ISR, DIV2K, with a 10% condensation rate. The resulting synthetic dataset offers comparable or (in certain cases) even better performance compared to the original full dataset and excellent training stability when used to train various popular ISR models. To the best of our knowledge, this is the first time that a condensed/synthetic dataset (with a 10% data volume) has demonstrated such performance. The source code and the synthetic dataset have been made available at https://github.com/.
GIViC: Generative Implicit Video Compression
Mar 25, 2025While video compression based on implicit neural representations (INRs) has recently demonstrated great potential, existing INR-based video codecs still cannot achieve state-of-the-art (SOTA) performance compared to their conventional or autoencoder-based counterparts given the same coding configuration. In this context, we propose a Generative Implicit Video Compression framework, GIViC, aiming at advancing the performance limits of this type of coding methods. GIViC is inspired by the characteristics that INRs share with large language and diffusion models in exploiting long-term dependencies. Through the newly designed implicit diffusion process, GIViC performs diffusive sampling across coarse-to-fine spatiotemporal decompositions, gradually progressing from coarser-grained full-sequence diffusion to finer-grained per-token diffusion. A novel Hierarchical Gated Linear Attention-based transformer (HGLA), is also integrated into the framework, which dual-factorizes global dependency modeling along scale and sequential axes. The proposed GIViC model has been benchmarked against SOTA conventional and neural codecs using a Random Access (RA) configuration (YUV 4:2:0, GOPSize=32), and yields BD-rate savings of 15.94%, 22.46% and 8.52% over VVC VTM, DCVC-FM and NVRC, respectively. As far as we are aware, GIViC is the first INR-based video codec that outperforms VTM based on the RA coding configuration. The source code will be made available.