 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake Out Your Calculators: Estimating the Real Difficulty of Question Items with LLM Student Simulations
Jan 15, 2026Standardized math assessments require expensive human pilot studies to establish the difficulty of test items. We investigate the predictive value of open-source large language models (LLMs) for evaluating the difficulty of multiple-choice math questions for real-world students. We show that, while LLMs are poor direct judges of problem difficulty, simulation-based approaches with LLMs yield promising results under the right conditions. Under the proposed approach, we simulate a "classroom" of 4th, 8th, or 12th grade students by prompting the LLM to role-play students of varying proficiency levels. We use the outcomes of these simulations to fit Item Response Theory (IRT) models, comparing learned difficulty parameters for items to their real-world difficulties, as determined by item-level statistics furnished by the National Assessment of Educational Progress (NAEP). We observe correlations as high as 0.75, 0.76, and 0.82 for grades 4, 8, and 12, respectively. In our simulations, we experiment with different "classroom sizes," showing tradeoffs between computation size and accuracy. We find that role-plays with named students improves predictions (compared to student ids), and stratifying names across gender and race further improves predictions. Our results show that LLMs with relatively weaker mathematical abilities (Gemma) actually yield better real-world difficulty predictions than mathematically stronger models (Llama and Qwen), further underscoring the suitability of open-source models for the task.
Linguistic Nepotism: Trading-off Quality for Language Preference in Multilingual RAG
Sep 17, 2025Multilingual Retrieval-Augmented Generation (mRAG) systems enable language models to answer knowledge-intensive queries with citation-supported responses across languages. While such systems have been proposed, an open questions is whether the mixture of different document languages impacts generation and citation in unintended ways. To investigate, we introduce a controlled methodology using model internals to measure language preference while holding other factors such as document relevance constant. Across eight languages and six open-weight models, we find that models preferentially cite English sources when queries are in English, with this bias amplified for lower-resource languages and for documents positioned mid-context. Crucially, we find that models sometimes trade-off document relevance for language preference, indicating that citation choices are not always driven by informativeness alone. Our findings shed light on how language models leverage multilingual context and influence citation behavior.
An Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
Multiple LLM Agents Debate for Equitable Cultural Alignment
May 30, 2025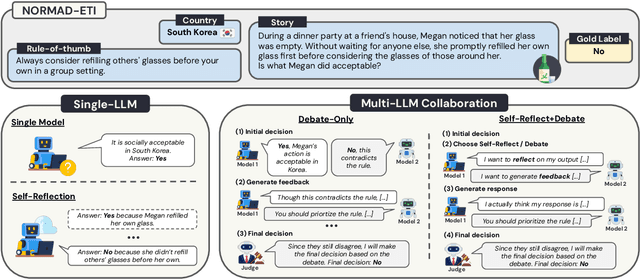
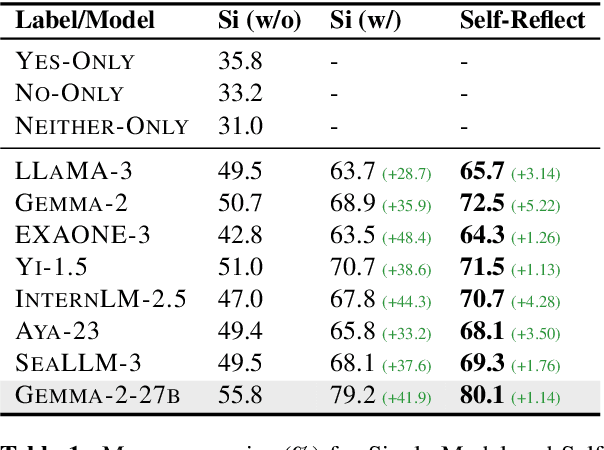
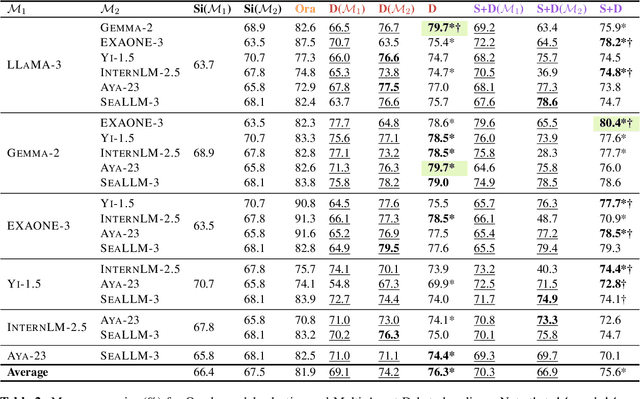
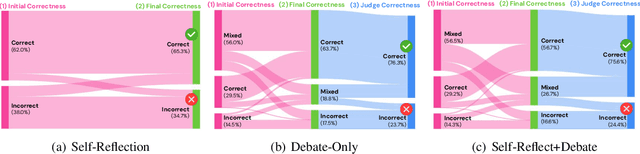
Large Language Models (LLMs) need to adapt their predictions to diverse cultural contexts to benefit diverse communities across the world. While previous efforts have focused on single-LLM, single-turn approaches, we propose to exploit the complementary strengths of multiple LLMs to promote cultural adaptability. We introduce a Multi-Agent Debate framework, where two LLM-based agents debate over a cultural scenario and collaboratively reach a final decision. We propose two variants: one where either LLM agents exclusively debate and another where they dynamically choose between self-reflection and debate during their turns. We evaluate these approaches on 7 open-weight LLMs (and 21 LLM combinations) using the NormAd-ETI benchmark for social etiquette norms in 75 countries. Experiments show that debate improves both overall accuracy and cultural group parity over single-LLM baselines. Notably, multi-agent debate enables relatively small LLMs (7-9B) to achieve accuracies comparable to that of a much larger model (27B parameters).
Should I Share this Translation? Evaluating Quality Feedback for User Reliance on Machine Translation
May 30, 2025As people increasingly use AI systems in work and daily life, feedback mechanisms that help them use AI responsibly are urgently needed, particularly in settings where users are not equipped to assess the quality of AI predictions. We study a realistic Machine Translation (MT) scenario where monolingual users decide whether to share an MT output, first without and then with quality feedback. We compare four types of quality feedback: explicit feedback that directly give users an assessment of translation quality using 1) error highlights and 2) LLM explanations, and implicit feedback that helps users compare MT inputs and outputs through 3) backtranslation and 4) question-answer (QA) tables. We find that all feedback types, except error highlights, significantly improve both decision accuracy and appropriate reliance. Notably, implicit feedback, especially QA tables, yields significantly greater gains than explicit feedback in terms of decision accuracy, appropriate reliance, and user perceptions, receiving the highest ratings for helpfulness and trust, and the lowest for mental burden.
VietMix: A Naturally Occurring Vietnamese-English Code-Mixed Corpus with Iterative Augmentation for Machine Translation
May 30, 2025Machine translation systems fail when processing code-mixed inputs for low-resource languages. We address this challenge by curating VietMix, a parallel corpus of naturally occurring code-mixed Vietnamese text paired with expert English translations. Augmenting this resource, we developed a complementary synthetic data generation pipeline. This pipeline incorporates filtering mechanisms to ensure syntactic plausibility and pragmatic appropriateness in code-mixing patterns. Experimental validation shows our naturalistic and complementary synthetic data boost models' performance, measured by translation quality estimation scores, of up to 71.84 on COMETkiwi and 81.77 on XCOMET. Triangulating positive results with LLM-based assessments, augmented models are favored over seed fine-tuned counterparts in approximately 49% of judgments (54-56% excluding ties). VietMix and our augmentation methodology advance ecological validity in neural MT evaluations and establish a framework for addressing code-mixed translation challenges across other low-resource pairs.
Steering Large Language Models with Register Analysis for Arbitrary Style Transfer
May 01, 2025Large Language Models (LLMs) have demonstrated strong capabilities in rewriting text across various styles. However, effectively leveraging this ability for example-based arbitrary style transfer, where an input text is rewritten to match the style of a given exemplar, remains an open challenge. A key question is how to describe the style of the exemplar to guide LLMs toward high-quality rewrites. In this work, we propose a prompting method based on register analysis to guide LLMs to perform this task. Empirical evaluations across multiple style transfer tasks show that our prompting approach enhances style transfer strength while preserving meaning more effectively than existing prompting strategies.
AskQE: Question Answering as Automatic Evaluation for Machine Translation
Apr 15, 2025How can a monolingual English speaker determine whether an automatic translation in French is good enough to be shared? Existing MT error detection and quality estimation (QE) techniques do not address this practical scenario. We introduce AskQE, a question generation and answering framework designed to detect critical MT errors and provide actionable feedback, helping users decide whether to accept or reject MT outputs even without the knowledge of the target language. Using ContraTICO, a dataset of contrastive synthetic MT errors in the COVID-19 domain, we explore design choices for AskQE and develop an optimized version relying on LLaMA-3 70B and entailed facts to guide question generation. We evaluate the resulting system on the BioMQM dataset of naturally occurring MT errors, where AskQE has higher Kendall's Tau correlation and decision accuracy with human ratings compared to other QE metrics.
Can you map it to English? The Role of Cross-Lingual Alignment in Multilingual Performance of LLMs
Apr 15, 2025Large language models (LLMs) pre-trained predominantly on English text exhibit surprising multilingual capabilities, yet the mechanisms driving cross-lingual generalization remain poorly understood. This work investigates how the alignment of representations for text written in different languages correlates with LLM performance on natural language understanding tasks and translation tasks, both at the language and the instance level. For this purpose, we introduce cross-lingual alignment metrics such as the Discriminative Alignment Index (DALI) to quantify the alignment at an instance level for discriminative tasks. Through experiments on three natural language understanding tasks (Belebele, XStoryCloze, XCOPA), and machine translation, we find that while cross-lingual alignment metrics strongly correlate with task accuracy at the language level, the sample-level alignment often fails to distinguish correct from incorrect predictions, exposing alignment as a necessary but insufficient condition for success.
GraphicBench: A Planning Benchmark for Graphic Design with Language Agents
Apr 15, 2025Large Language Model (LLM)-powered agents have unlocked new possibilities for automating human tasks. While prior work has focused on well-defined tasks with specified goals, the capabilities of agents in creative design tasks with open-ended goals remain underexplored. We introduce GraphicBench, a new planning benchmark for graphic design that covers 1,079 user queries and input images across four design types. We further present GraphicTown, an LLM agent framework with three design experts and 46 actions (tools) to choose from for executing each step of the planned workflows in web environments. Experiments with six LLMs demonstrate their ability to generate workflows that integrate both explicit design constraints from user queries and implicit commonsense constraints. However, these workflows often do not lead to successful execution outcomes, primarily due to challenges in: (1) reasoning about spatial relationships, (2) coordinating global dependencies across experts, and (3) retrieving the most appropriate action per step. We envision GraphicBench as a challenging yet valuable testbed for advancing LLM-agent planning and execution in creative design tasks.